Netflix Movie recommendation system
Category: AI & Machine LearningNetflix Movie recommendation system
Category: AI & Machine LearningStatement:
Netflix is all about connecting people to the movies they love. To help customers find those movies, they’ve developed a world-class movie recommendation system: CinematchSM. Its job is to predict whether someone will enjoy a movie based on how much they liked or disliked other movies. they use those predictions to make personal movie recommendations based on each customer’s unique tastes Given list of ratings provided by user per a movie on particular date. We need to predict the rating will be given by an user on a particular day.- Data Type
- Text files and csv files
- Movie_titles.csv (id, year, name)
- Train data: combined_data.txt( movie_id, {user_id, rating, date_of_rating}*)
- Test data: qualifying.txt (movie_id, {user_id, date}*)
- Data Size: 682 MB
Key Points:
- Validity of this course is 240 days( i.e Starts from the date of your registration to this course)
- Expert Guidance, we will try to answer your queries in atmost 24hours
- 10+ machine learning algorithms will be taught in this course.
- No prerequisites-- we will teach every thing from basics ( we just expect you to know basic programming)
- Python for Data science is part of the course curriculum.
Target Audience:
We are building our course content and teaching methodology to cater to the needs to students at various levels of expertise and varying background skills. This course can be taken by anyone with a working knowledge of a modern programming language like C/C++/Java/Python. We expect the average student to spend at least 5 hours a week over a 6 month period amounting to a 145+ hours of effort. More the effort, better the results. Here is a list of customers who would benefit from our course:-
- Undergrad (BS/BTech/BE) students in engineering and science.
- Grad(MS/MTech/ME/MCA) students in engineering and science.
- Working professionals: Software engineers, Business analysts, Product managers, Program managers, Managers, Startup teams building ML products/service
Course Features
Lectures
Duration
100+ hours
Skill level
All levels
Language
English
Assessments

QUALIFICATION: Masters from IISC Bangalore, PROFESSIONAL EXPERIENCE: 11+ years of Experience( Yahoo Labs, Matherix Labs Co-founder, and Amazon)
Netflix Movie recommendation system
Category: AI & Machine Learning
4 Comment(s)
Loading...
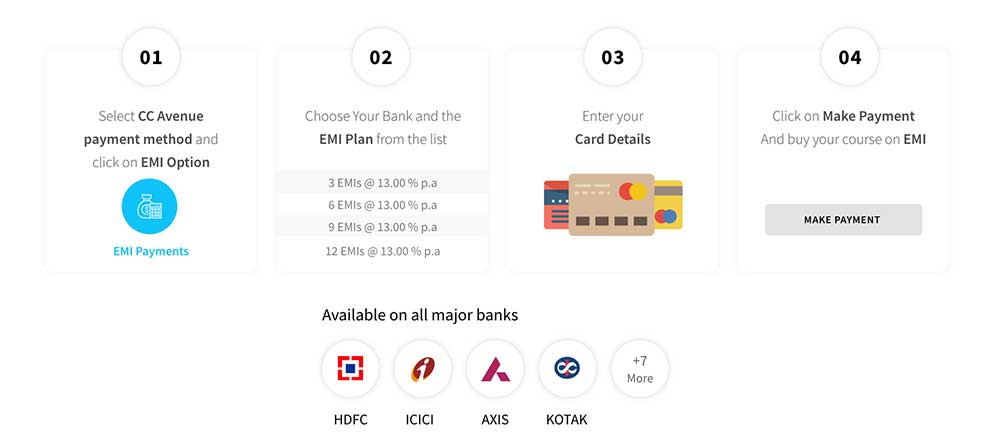
Pay easy monthly installments instead of lump-sum amount.