Weka (Waikato Environment for Knowledge Analysis) is a popular open-source machine learning software that provides tools for data mining, classification, clustering, and predictive modeling. Developed at the University of Waikato, New Zealand, Weka has gained widespread adoption due to its user-friendly interface, powerful machine learning algorithms, and extensive documentation.
Weka was initially created as a tool for agricultural data analysis but has since evolved into a comprehensive suite for researchers, data scientists, and students exploring machine learning concepts. It supports graphical user interfaces (GUI), command-line operations, and Java integration, making it highly versatile.
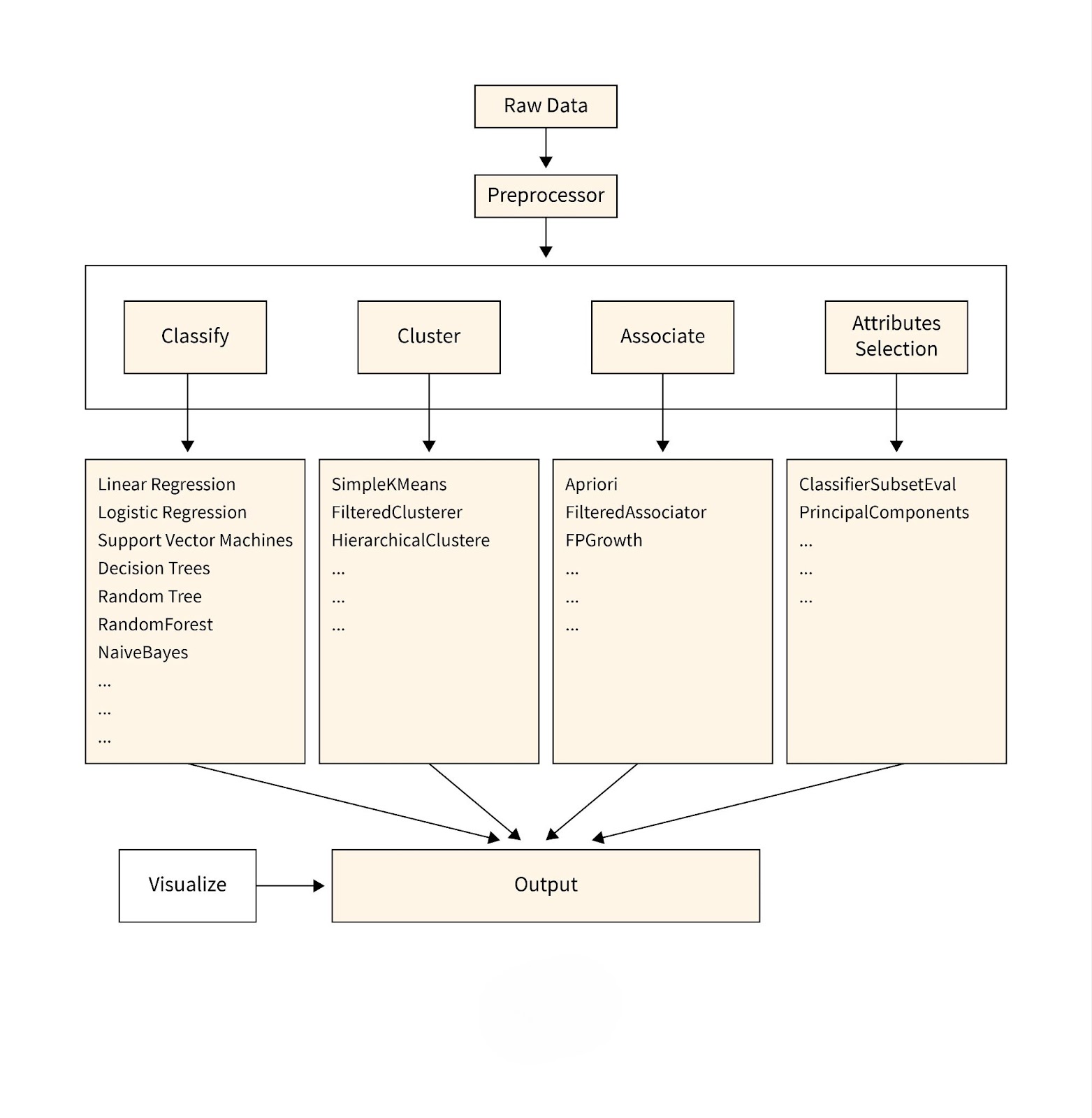
One of Weka’s biggest strengths is its ease of use, allowing users to apply machine learning techniques without extensive programming knowledge. Its preprocessing, classification, clustering, regression, and visualization tools make it an essential resource for both beginners and advanced users in the field of artificial intelligence and data science.
Features of Weka
Weka is widely recognized for its powerful yet easy-to-use features, making it an essential tool for data mining and machine learning. Below are some of its key features:
- Graphical User Interface (GUI) for Easy Interaction: Weka provides an intuitive Graphical User Interface (GUI) that allows users to apply machine learning techniques without writing code. The GUI offers a drag-and-drop approach to load datasets, apply preprocessing techniques, train models, and visualize results.
- Support for Multiple Data Mining and Machine Learning Tasks: Weka supports a variety of machine learning operations, including:
- Classification (e.g., Decision Trees, Naïve Bayes, SVMs)
- Clustering (e.g., K-Means, Hierarchical Clustering)
- Regression (e.g., Linear Regression, Multilayer Perceptron)
- Feature Selection for dimensionality reduction
- Data Preprocessing such as handling missing values and normalization
- Integration with Java for Extensibility: Weka is implemented in Java, allowing developers to extend its functionalities through custom algorithms. It provides an API that integrates easily with Java-based machine learning projects.
- Comprehensive Preprocessing and Visualization Tools: Weka includes built-in tools for data cleaning, transformation, and visualization, ensuring that datasets are optimized before model training. Users can generate histograms, scatter plots, and summary statistics for better data understanding.
Installation and Requirements for Weka
Weka is a cross-platform machine learning tool that runs on Windows, Mac, and Linux. It is developed in Java, making it compatible with most operating systems. Below are the system requirements and installation steps.
System Requirements
- Windows: Windows 7 or later, Java 8 or higher
- Mac: macOS 10.10 or later, Java 8 or higher
- Linux: Any modern Linux distribution with Java support
Step-by-Step Guide to Installing Weka
- Download Weka from the official website: Weka Download Page.
- Choose the appropriate version for your operating system.
- Run the installer and follow the on-screen instructions.
- Once installed, launch Weka to ensure it runs correctly.
Setting Up Weka with Java and Additional Libraries
- Ensure Java 8 or higher is installed. If not, download it from Oracle Java.
- To extend Weka’s capabilities, users can install additional libraries like MOA (Massive Online Analysis) for real-time data mining.
Weka’s simple setup process ensures that users can start experimenting with machine learning immediately after installation.
Data Types and Formats in Weka
Weka supports various data file formats for machine learning tasks. The most commonly used formats include:
- ARFF (Attribute-Relation File Format) – Weka’s native format, storing both metadata and dataset values.
- CSV (Comma-Separated Values) – Widely used for structured datasets but requires conversion into ARFF for optimal use in Weka.
- C4.5 (Attribute-Value Pairs) – Used for decision tree models.
- JSON and XML – Supported through additional plugins for handling complex structured data.
Converting Datasets into Compatible Formats
- Users can convert CSV files to ARFF within Weka’s Preprocessing panel or manually using Python or Java scripts.
- Missing values and categorical attributes must be properly formatted to avoid errors.
- Weka provides built-in tools for data transformation to ensure seamless compatibility with its algorithms.
Using the right file format ensures that Weka can efficiently process and analyze data for machine learning tasks.
Loading Data in Weka
Weka’s Graphical User Interface (GUI) makes it easy to import datasets:
- Open Weka and navigate to the Explorer panel.
- Click Open File, select the dataset in ARFF, CSV, or other supported formats.
- Use the Preprocessing tab to inspect data attributes and clean missing values.
Command-Line Interface Options
Advanced users can load datasets using Weka’s command-line interface (CLI):
java weka.core.converters.CSVLoader dataset.csv > dataset.arffThis method is useful for automation and integrating Weka with other tools.
Best Practices for Ensuring Data Quality:
- Ensure that all attributes are properly labeled and formatted correctly.
- Handle missing values using Weka’s built-in imputation techniques.
- Normalize numerical features to improve model performance.
Data Mining Process with Weka
Weka simplifies the data mining process through an intuitive Explorer interface, which consists of multiple panels designed for different stages of analysis. Below are the key components of Weka’s Explorer and their functions:
Preprocessing Panel: Data Filtering and Transformation
Before applying machine learning algorithms, raw data must be cleaned and transformed. The Preprocessing panel allows users to:
- Handle missing values by replacing or removing them.
- Normalize or standardize numerical attributes.
- Apply feature selection techniques to remove irrelevant attributes.
- Convert categorical variables into numeric formats for ML models.
Classification Panel: Training Machine Learning Models
The Classification panel enables users to train supervised models, such as:
- Decision Trees (J48, Random Forest)
- Naïve Bayes
- Support Vector Machines (SVM)
It also provides performance evaluation tools, such as confusion matrices and cross-validation.
Clustering Panel: Grouping Similar Data Points
This panel supports unsupervised learning algorithms, including:
- K-Means Clustering
- Hierarchical Clustering
- EM (Expectation-Maximization)
Association Rules Panel: Identifying Relationships in Data
Weka’s Apriori algorithm helps in discovering association rules (e.g., market basket analysis), revealing relationships between different items in datasets.
Visualization Panel: Graphical Representation of Results
Weka includes scatter plots, histograms, and decision tree diagrams for visualizing patterns and model performance.
Types of Machine Learning Algorithms in Weka
Weka provides a comprehensive set of machine learning algorithms, categorized into supervised, unsupervised, and reinforcement learning, with support for deep learning extensions.
1. Supervised Learning: Decision Trees, Naïve Bayes, SVM
Supervised learning involves training models on labeled datasets. Weka includes:
- Decision Trees (J48, Random Forest) – Used for classification tasks such as spam detection and fraud analysis.
- Naïve Bayes – A probabilistic classifier effective in text classification and sentiment analysis.
- Support Vector Machines (SVM) – Ideal for high-dimensional data like image recognition and medical diagnosis.
2. Unsupervised Learning: K-Means Clustering, DBSCAN
Unsupervised learning identifies patterns in unlabeled data:
- K-Means Clustering – Groups data points based on similarity, widely used in customer segmentation.
- DBSCAN – Density-based clustering useful for detecting anomalies and outliers.
3. Reinforcement Learning: Application in Weka
Weka supports reinforcement learning through extensions, allowing users to train agents in dynamic environments, such as robotics and game AI.
4. Deep Learning Extensions: Using Weka with TensorFlow and DL4J
Weka integrates with TensorFlow and DeepLearning4J (DL4J), enabling users to build and train deep learning models for tasks like image recognition and NLP.
These algorithms make Weka a powerful tool for both traditional and advanced machine learning applications.
Advantages and Disadvantages of Using Weka
Advantages of Using Weka
- Open-source and free to use – Weka is completely free, making it accessible for students, researchers, and professionals.
- User-friendly interface – The GUI-based approach allows beginners to apply machine learning techniques without coding.
- Comprehensive machine learning tools – Supports classification, clustering, regression, and association rule mining in one platform.
- Extensive documentation and community support – Users can find numerous tutorials, guides, and forums for troubleshooting and learning.
- Preprocessing and visualization tools – Offers built-in tools for data cleaning, feature selection, and graphical representation.
Limitations of Weka
- Limited scalability for large datasets – Weka loads data into memory, making it inefficient for big data applications.
- Slower performance compared to advanced ML libraries – Tools like TensorFlow, Scikit-Learn, and PyTorch are optimized for speed and efficiency.
- Lack of deep learning support – Weka is not designed for neural networks and GPU-based computations, making it unsuitable for large-scale AI applications.
- Less flexibility in model customization – Advanced users may find Weka’s pre-built algorithms limiting compared to custom implementations in Python or R.
While Weka is excellent for academic research and small-scale projects, those working on big data and deep learning may require additional tools for advanced functionality.
Applications of Weka
Weka is widely used across multiple domains due to its versatile machine learning and data mining capabilities. Below are some of its key applications:
- Academic Research and Education – Weka is extensively used in universities and research institutions to teach machine learning concepts. Its GUI-based interface allows students to explore different ML techniques without requiring advanced programming knowledge. Researchers also use Weka for experiments, prototype testing, and algorithm benchmarking.
- Predictive Analytics in Healthcare and Finance – Weka is applied in predictive modeling for sectors like healthcare and finance. In healthcare, it helps in disease prediction, patient risk assessment, and medical diagnosis by analyzing historical patient data. In finance, Weka is used for credit scoring, fraud detection, and stock market predictions, leveraging machine learning algorithms for risk analysis.
- Automated Data Preprocessing and Model Evaluation – Weka simplifies data cleaning, transformation, and feature selection, making it ideal for preprocessing datasets before model training. It also provides tools for evaluating ML models, including cross-validation and performance metrics like accuracy, precision, and recall.
- Integration in AI-Driven Decision-Making Systems – Weka can be integrated into AI-powered applications to automate decision-making processes, such as customer segmentation, recommendation systems, and anomaly detection. It is also used in robotics and IoT for intelligent pattern recognition and real-time analysis.
Weka Extension Packages
Popular Weka Extension Packages
Weka’s functionality can be expanded through extension packages, providing additional tools for specialized machine learning tasks. Some of the most widely used packages include:
- MOA (Massive Online Analysis) – Designed for real-time stream data mining, enabling users to handle continuously evolving datasets.
- Auto-WEKA – Automates hyperparameter tuning, helping users find the best ML model configurations without manual adjustments.
Creating and Contributing Weka Packages
Developers can create custom extension packages by implementing Java-based modules and integrating them with Weka’s framework. The process involves:
- Writing custom ML algorithms using the Weka API.
- Packaging and testing the extension with different datasets.
- Submitting contributions following community guidelines on Weka’s official repository.
Benefits of Weka Extension Packages
By utilizing extensions, users can enhance Weka’s core capabilities for deep learning, big data analytics, and automated ML. These packages enable advanced users to customize Weka for specific research, industrial applications, and large-scale data processing.
With an active developer community, Weka continues to evolve through open-source contributions, making it a flexible and powerful ML platform.
Conclusion
Weka is a powerful open-source machine learning tool that offers easy-to-use interfaces, a diverse range of algorithms, and built-in data preprocessing tools. With applications in academic research, healthcare, finance, and AI-driven decision-making, Weka remains a popular choice for students, researchers, and industry professionals.
Its GUI, extensibility through Java, and support for automation make it ideal for exploring machine learning without requiring extensive programming knowledge. As AI continues to evolve, Weka’s integration with deep learning frameworks and big data analytics will enhance its capabilities, ensuring its relevance in the ever-growing field of data science and machine learning.
References:


