In today’s fast-paced digital world, organizations generate massive streams of data from sources like social media, IoT devices, web applications, and financial transactions. The need to analyze and act on this data in real time has given rise to powerful stream processing frameworks. One of the most prominent among them is Apache Spark Streaming. As an extension of the Apache Spark ecosystem, Spark Streaming enables scalable, fault-tolerant stream processing of live data. It bridges the gap between batch and real-time analytics, making it a vital tool for modern businesses that rely on instant insights for operational efficiency and decision-making.
What is Spark Streaming?
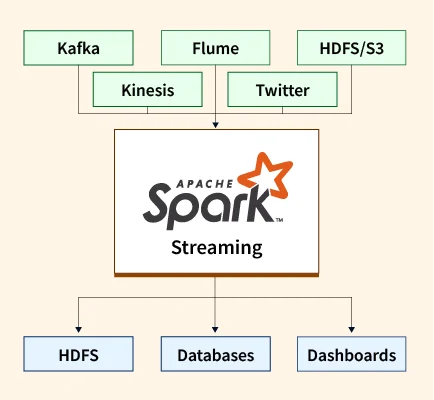
Spark Streaming is a real-time data processing framework built on top of Apache Spark. Its core purpose is to process and analyze live data streams from various sources such as Kafka, Flume, Amazon Kinesis, and TCP sockets. Unlike traditional batch processing, Spark Streaming enables applications to respond to data as it arrives, making it ideal for time-sensitive use cases like fraud detection, monitoring, and recommendation engines.
Spark Streaming works by dividing incoming data into small batches, known as micro-batches. These batches are then processed using the same powerful Spark engine that handles batch and machine learning tasks. This approach allows developers to apply high-level APIs like map, reduce, join, and window to streaming data—just as they would with static datasets.
Core Concepts of Spark Streaming
1. DStreams (Discretized Streams)
At the heart of Spark Streaming is the concept of Discretized Streams (DStreams). A DStream represents a continuous stream of data divided into small, time-based batches. Internally, each batch is treated as a Resilient Distributed Dataset (RDD), enabling Spark to use its fault-tolerant and distributed processing engine to handle streaming data just like batch data.
2. Receivers and Input Sources
To ingest live data, Spark Streaming relies on receivers that listen to input sources. These sources include Apache Kafka, Apache Flume, TCP sockets, Amazon Kinesis, and HDFS directories. Receivers collect the incoming data and buffer it into memory for further processing. Reliable receivers ensure fault tolerance by acknowledging data only after successful ingestion.
3. Transformations and Actions
Once data is ingested into DStreams, Spark Streaming supports a range of transformations and actions. Common transformations include map, flatMap, filter, reduceByKey, join, and windowed operations like sliding and tumbling windows. These allow real-time aggregation and correlation across time intervals. Actions like count, saveAsTextFiles, or foreachRDD execute computations or trigger output.
4. Output Operations
After processing, the final results can be sent to external systems such as HDFS, databases (e.g., Cassandra, PostgreSQL), dashboards, or even live applications. This step completes the streaming pipeline and allows downstream systems to act on the processed data in near real-time.
Spark Streaming vs. Structured Streaming
While both frameworks are part of Apache Spark, Spark Streaming and Structured Streaming differ significantly in design and capability. Spark Streaming uses DStreams and micro-batching, offering functional APIs but limited built-in guarantees for exactly-once processing. In contrast, Structured Streaming provides a declarative API, treating streaming data as an unbounded table and enabling stronger fault tolerance, end-to-end consistency, and event-time processing.
Structured Streaming is preferred for mission-critical, real-time applications where accuracy and latency matter. Spark Streaming may still be used for legacy systems or simpler use cases, but Structured Streaming is the recommended modern approach going forward.
Limitations and Challenges
Despite its strengths, Spark Streaming has a few limitations. Its micro-batch architecture introduces slight latency, making it less ideal for ultra-low-latency requirements. Setting up streaming pipelines can be complex, especially when integrating multiple sources. Additionally, the learning curve for managing stateful processing and error handling can be steep.
Read More:
Reference: