Machine Learning (ML) is a rapidly advancing field within artificial intelligence that empowers systems to learn from data and improve over time without explicit programming. With applications across sectors like healthcare, finance, and retail, ML is revolutionizing how we analyze data, make decisions, and automate processes.
What is Machine Learning?
Machine Learning (ML) is a subset of artificial intelligence focused on creating systems that learn from data to make decisions or predictions. Unlike traditional programming, where explicit instructions are coded for each task, ML enables computers to learn patterns and insights from data autonomously. This capability makes ML essential for handling tasks with complex, non-deterministic patterns.
ML’s core objective is to enable systems to recognize patterns within data and generalize these patterns to new, unseen scenarios. By analyzing past data, ML models can make predictions or decisions in real-time, adapting as they encounter more information. This learning process involves training algorithms on a dataset, allowing them to optimize their performance over time.
The applications of ML span across many fields. In healthcare, ML models assist in diagnosing diseases by analyzing medical images or patient records. In finance, ML is crucial for fraud detection, credit scoring, and algorithmic trading. E-commerce companies use ML to recommend products based on users’ past interactions, while social media platforms employ it to detect inappropriate content and improve user experience. In manufacturing, ML optimizes supply chain logistics and predicts machinery maintenance needs.
The flexibility and scalability of ML make it invaluable across industries, empowering organizations to drive data-driven decision-making, enhance efficiency, and improve customer experiences. As a result, ML is a transformative force in modern technology, offering innovative solutions for challenges in both business and daily life.
How Does Machine Learning Work?
Machine Learning (ML) works by using data to train algorithms, enabling them to recognize patterns, make predictions, and improve over time. The ML workflow comprises several stages, each essential for building an effective model that can generalize well to new data.
The first stage is data collection, where relevant data is gathered from various sources. This data serves as the foundation for training the model, and its quality and diversity are critical to the model’s success.
Next, data preprocessing cleans and transforms the raw data into a suitable format. Preprocessing includes handling missing values, normalizing features, and encoding categorical data. This stage ensures that the model can accurately interpret the data and improves the quality of insights generated.
In the model training stage, the dataset is divided into a training set and a testing set. The training set is used to teach the model, enabling it to adjust its parameters based on patterns within the data. During training, the model optimizes its predictions by minimizing errors, a process driven by the chosen algorithm and learning technique.
After training, the model is evaluated using the testing set to assess its performance on new, unseen data. Evaluation metrics such as accuracy, precision, and recall measure the model’s predictive power. Another critical metric is generalization—the model’s ability to perform well on both training and testing data. A model that generalizes effectively can make accurate predictions on data it hasn’t encountered before.
Finally, the model may undergo fine-tuning or optimization to enhance its performance. Adjustments to hyperparameters, data balancing, or algorithm changes help improve accuracy and prevent overfitting, where a model becomes too tailored to training data.
This iterative workflow ensures that the model is adaptable, reliable, and capable of producing actionable insights from data, empowering organizations to automate processes and make data-driven decisions effectively.
Machine Learning vs. Traditional Programming
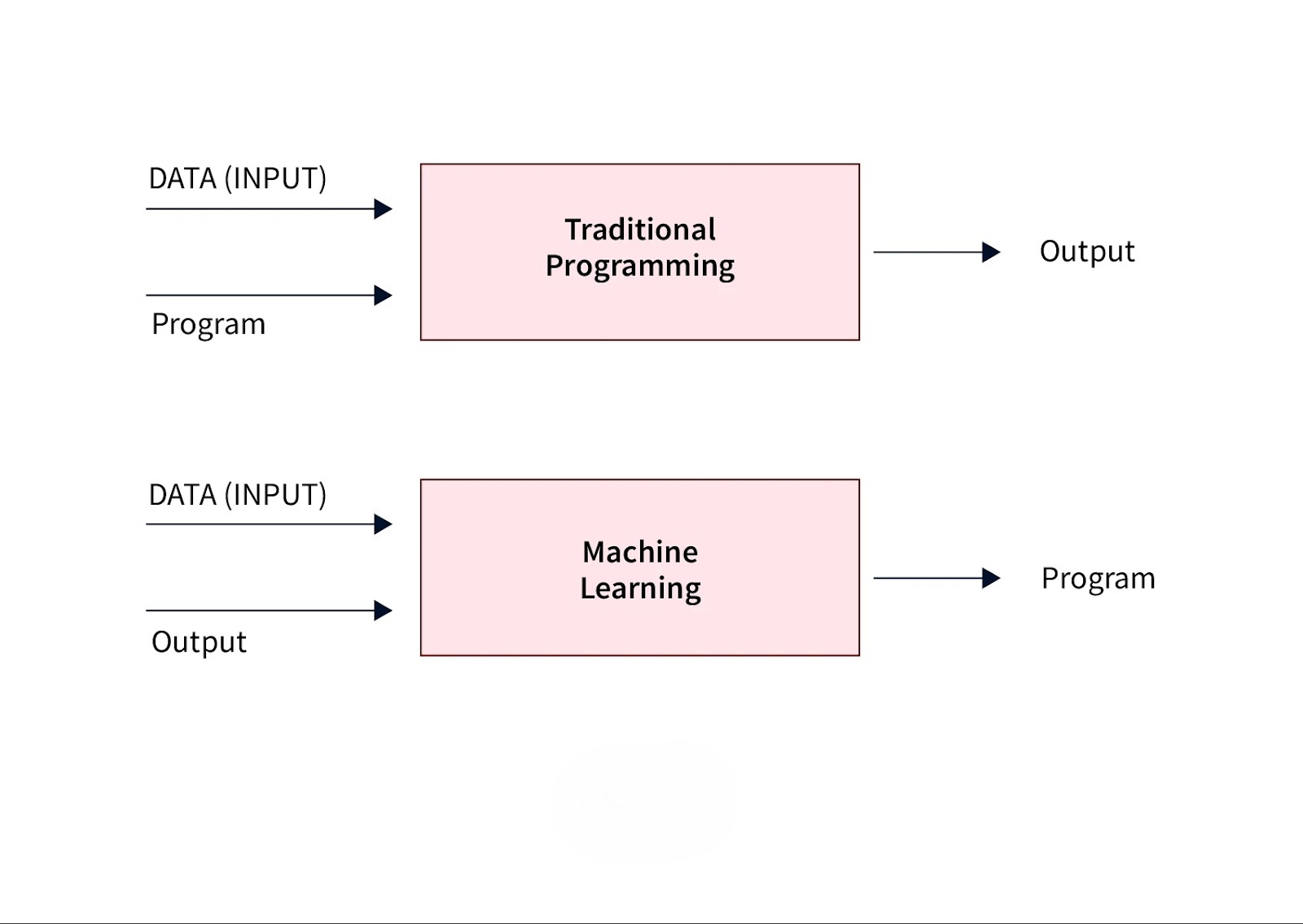
Machine Learning (ML) and traditional programming take fundamentally different approaches to problem-solving. In traditional programming, developers write explicit rules and instructions for the system to follow. This approach is ideal for well-defined tasks, like calculating payroll or managing inventory, where precise instructions yield consistent outcomes.
ML, however, is designed to handle complex, variable scenarios where defining explicit rules is challenging. Instead of being programmed with detailed instructions, ML models learn from data. By identifying patterns in historical data, an ML model can make predictions or classifications for new, unseen data. This adaptability is critical for tasks like image recognition, natural language processing, or fraud detection, where variations in data make rule-based programming impractical.
In traditional programming, every possible scenario must be anticipated, which can become unwieldy for dynamic, large-scale problems. ML overcomes this by continuously learning from data, allowing it to adapt to new inputs and refine its performance over time. For example, in a spam filter, ML algorithms can learn to recognize new types of spam messages based on user interactions and evolving language patterns.
Ultimately, ML’s ability to “learn” from data and make predictions independently is what distinguishes it from traditional programming, providing flexibility and scalability in an increasingly data-driven world.
Types of Machine Learning
Machine Learning (ML) encompasses various methods tailored to different data types and learning objectives. The four primary types are supervised, unsupervised, semi-supervised, and reinforcement learning. Each type serves distinct purposes, enabling ML to adapt to various applications.
1. Supervised Learning
In supervised learning, the model is trained on labeled data, where each data point has an input and a known output, or target variable. The goal is for the model to learn the mapping from input to output, so it can predict outcomes for new data. Supervised learning is widely used in classification (e.g., identifying spam emails) and regression (e.g., predicting house prices) tasks. It’s effective when a substantial amount of labeled data is available, and the model’s performance can be evaluated by comparing its predictions with known results.
2. Unsupervised Learning
Unsupervised learning deals with unlabeled data, where the model seeks to identify patterns or relationships without specific guidance on outcomes. It’s particularly useful for discovering hidden structures within data, making it ideal for tasks like clustering (grouping similar items, such as customer segmentation) and association (finding relationships, such as product recommendations). Unsupervised learning enables insights from raw data and helps uncover trends that might not be immediately apparent, providing valuable exploratory analysis and data grouping.
3. Semi-Supervised Learning
Semi-supervised learning combines both labeled and unlabeled data, capitalizing on a small set of labeled examples to guide learning on a larger set of unlabeled data. This method is especially useful when labeled data is costly or time-consuming to obtain. Practical applications include image recognition and text classification, where obtaining full labels is challenging but some labeled examples can enhance the learning process. Semi-supervised learning balances accuracy and efficiency, improving performance without requiring extensive labeled datasets.
4. Reinforcement Learning
Reinforcement learning (RL) involves an agent that learns by trial and error through interactions with an environment, receiving rewards for favorable actions and penalties for unfavorable ones. Unlike other ML types, RL focuses on sequential decision-making and is widely used in robotics, gaming, and automated trading. The agent’s goal is to maximize cumulative rewards by learning an optimal policy over time. RL’s adaptability to dynamic environments and its ability to improve through experience make it suitable for complex tasks requiring autonomous action and strategy formation.
Common Machine Learning Algorithms
Machine Learning (ML) encompasses a variety of algorithms designed for specific tasks, each with distinct advantages and applications. Here are some of the most popular ML algorithms.
1. Linear Regression
Linear regression is used to predict continuous variables by finding a relationship between input features and the target variable. It assumes a linear relationship and fits a line (or hyperplane in higher dimensions) to minimize prediction errors. Common applications include forecasting (e.g., predicting sales based on historical data) and risk assessment. Linear regression is straightforward and interpretable, making it a widely used algorithm for tasks that require an understanding of relationships between variables.
2. Logistic Regression
Despite its name, logistic regression is a classification algorithm primarily used for binary classification (e.g., spam vs. non-spam) and can extend to multi-class classification tasks. It estimates the probability of a data point belonging to a particular category by applying a logistic function. Logistic regression is effective for medical diagnosis, fraud detection, and other tasks where predicting categorical outcomes is crucial. Its simplicity and efficiency make it a go-to algorithm for classification problems.
3. Decision Trees and Random Forests
Decision trees use a tree-like structure to make decisions based on feature values, which are split to maximize predictive accuracy. They are intuitive and useful for both classification and regression tasks. However, decision trees can overfit on complex datasets. Random forests, an ensemble method, address this by generating multiple decision trees and averaging their predictions, leading to better generalization. They are widely used in credit scoring, bioinformatics, and other fields that benefit from robust predictive models.
4. Neural Networks
Neural networks, inspired by the human brain, are the foundation of deep learning. They consist of layers of interconnected nodes (neurons) that process data and learn complex patterns. Neural networks are powerful for tasks such as image recognition, natural language processing, and speech recognition. Due to their ability to handle large and complex datasets, they are particularly effective in applications where deep learning’s feature extraction capabilities are advantageous.
5. Clustering Algorithms
Clustering algorithms, like K-means and hierarchical clustering, are unsupervised methods used to group data points based on similarity. K-means assigns data points to a predefined number of clusters, while hierarchical clustering builds a tree-like structure. Clustering is invaluable in customer segmentation, image compression, and anomaly detection, where grouping similar data can reveal insights or help with data organization. These algorithms are crucial for exploratory analysis in cases where labels are unavailable.
Machine Learning Lifecycle
The Machine Learning (ML) lifecycle outlines the essential steps needed to develop and deploy ML models successfully. From defining the problem to monitoring the model in a live environment, each phase plays a critical role in ensuring the model’s effectiveness and reliability.
1. Data Collection
Data collection is the foundational step, as high-quality data directly influences the ML model’s accuracy. Data must be relevant, representative, and comprehensive to capture the problem’s nuances. This stage includes identifying reliable data sources and gathering sufficient quantities of labeled or unlabeled data, depending on the task.
2. Data Preprocessing
Data preprocessing prepares raw data for the ML model by handling missing values, normalizing numerical data, and transforming variables as needed. Techniques like data cleaning, feature scaling, and encoding categorical variables help standardize the data, allowing models to learn effectively from it.
3. Model Training and Testing
In this stage, the ML model is trained on a labeled dataset to recognize patterns and relationships between input features and the target variable. Testing the model on a separate dataset evaluates its accuracy and generalization ability, providing insights into how well the model may perform on new, unseen data.
4. Evaluation and Fine-tuning
Model evaluation involves assessing the model’s performance using metrics like accuracy, precision, and recall. Based on these results, fine-tuning adjusts parameters (hyperparameters) to enhance accuracy or reduce errors. This iterative process ensures the model is optimized for the specific task.
5. Deployment and Monitoring
Once the model meets performance standards, it is deployed into a real-world environment. This step involves integrating the model into applications or systems where it can make predictions on live data. Continuous monitoring is crucial post-deployment to detect performance drifts, manage data changes, and ensure the model’s predictions remain accurate over time. Tools for automated monitoring and retraining cycles are essential to maintaining the model’s effectiveness, especially as real-world data evolves.
Machine Learning in Action: Real-World Applications
Machine Learning (ML) has transformative applications across numerous industries, revolutionizing processes and enabling data-driven decision-making.
- Healthcare: ML is widely used in predictive diagnostics, where algorithms analyze patient data to detect early signs of diseases, such as cancer or heart conditions. In medical imaging, ML helps identify anomalies that may be challenging for human eyes, leading to improved accuracy and faster diagnoses.
- Finance: ML algorithms are crucial in fraud detection and credit scoring. By analyzing transaction patterns, banks and financial institutions can detect suspicious activity and prevent fraud in real-time. Additionally, ML-based credit scoring models assess creditworthiness by examining factors beyond traditional financial histories, leading to more inclusive and fair lending practices.
- Retail: Recommendation systems powered by ML personalize the shopping experience, suggesting products based on past behavior, preferences, and trending items. Retailers use ML to optimize inventory management, forecast demand, and understand customer behavior, driving both customer satisfaction and sales.
- Transportation: In the automotive industry, ML is a foundational technology for autonomous vehicles. Through sensors and real-time data processing, self-driving cars learn to navigate roads, recognize obstacles, and make safe driving decisions. ML also enhances transportation systems by enabling route optimization and predictive maintenance for vehicles.
ML’s versatility continues to create new possibilities, reshaping industries and redefining operational standards.
Advantages and Disadvantages of Machine Learning
Machine Learning offers significant advantages but also poses certain limitations.
Advantages:
- Efficiency: ML automates complex processes, reducing manual effort and enabling quick decision-making, especially in data-heavy tasks.
- Accuracy: With proper data, ML models provide high accuracy, as seen in predictive models for healthcare and finance.
- Automation: ML facilitates continuous learning from new data, improving accuracy over time. This is particularly valuable in dynamic fields like fraud detection and recommendation systems.
Disadvantages:
- Data Dependency: ML models rely on large, high-quality datasets. Insufficient or biased data can hinder model performance and lead to inaccurate predictions.
- Bias: ML algorithms may inherit biases present in training data, resulting in unfair or skewed decisions, especially in sensitive areas like hiring and law enforcement.
- Interpretability: Complex ML models, such as deep neural networks, are often challenging to interpret, making it difficult to understand their decision-making process and creating trust issues, particularly in critical applications.
Key Challenges in Machine Learning
Machine Learning (ML) faces several pressing challenges that need careful consideration and management for responsible and effective application.
1. Privacy and Security
One of the primary challenges in ML is ensuring data privacy and security. With vast amounts of personal data used for model training, there are concerns about the protection and ethical use of information. Compliance with regulations such as the General Data Protection Regulation (GDPR) requires organizations to handle data responsibly, imposing constraints on data storage, usage, and sharing. Additionally, as AI systems become more pervasive, there’s a growing need for frameworks that ensure secure and responsible AI practices to prevent misuse and protect user privacy.
2. Bias and Fairness
Bias in ML algorithms stems from historical data containing societal biases, which may inadvertently perpetuate discrimination. Ensuring fairness is critical, especially in applications like hiring, law enforcement, and healthcare, where biased decisions can have severe consequences. Researchers and practitioners are focusing on methods to mitigate bias, such as bias-aware algorithms and balanced datasets. Implementing fairness in ML requires ongoing efforts to refine algorithms and validate data sources, reducing the risk of biased outputs and promoting ethical ML practices.
3. Transparency and Interpretability
Complex ML models, particularly deep learning networks, often lack transparency, making it difficult to interpret their decisions. This lack of interpretability can erode trust, especially in critical applications like healthcare and finance, where decisions impact human lives. Explainable AI (XAI) aims to bridge this gap by making ML models’ processes more understandable. Transparent models allow users to gain insights into how decisions are made, fostering greater trust in AI systems, especially where accountability is essential.
Future of Machine Learning
The future of ML is marked by several promising trends and developments. Quantum computing is expected to accelerate ML advancements, enabling models to process vast datasets more efficiently and solve complex problems beyond current computational limits. Another emerging trend is hybrid ML-AI models that combine traditional ML techniques with advanced AI approaches, leading to enhanced predictive capabilities and adaptability.
ML is also expected to have a profound impact on the job market. While it will automate routine tasks, there will be a surge in demand for ML professionals and roles requiring data-driven decision-making. However, ethical considerations will continue to be paramount, as there are ongoing discussions about the role of AI in society, including job displacement, privacy, and bias concerns. The future of ML will likely emphasize a balance between technological innovation and responsible application.
Conclusion
Machine Learning has transformed the way industries leverage data, bringing unprecedented capabilities to predict, analyze, and automate processes. From enhancing decision-making to driving innovation, ML’s impact on society is profound. However, challenges like privacy, bias, and interpretability need to be addressed to ensure responsible deployment. As ML continues to evolve, professionals and organizations alike must focus on ethical practices while exploring new advancements in the field. Continued learning, curiosity, and commitment to ethical AI will be essential for shaping a future where ML benefits humanity comprehensively.
References:


