The rapid growth of big data has made traditional data processing methods inefficient, leading to the need for scalable solutions. Hadoop is an open-source framework that enables the distributed storage and parallel processing of massive datasets across multiple machines.
Hadoop’s ability to handle large-scale data efficiently makes it essential for big data analytics, cloud computing, and enterprise-level data processing. By distributing data and computational tasks across clusters, it provides a cost-effective and reliable approach to managing structured and unstructured data at scale.
What is Hadoop?
Hadoop is an open-source framework designed for distributed storage and parallel processing of large datasets across multiple machines. It provides a scalable and fault-tolerant architecture, making it an essential tool for handling massive volumes of structured and unstructured data.
Hadoop plays a crucial role in big data analytics, allowing organizations to process large-scale information efficiently. It is widely used in cloud computing environments, enabling businesses to store and analyze data without relying on expensive high-performance hardware. In enterprise solutions, Hadoop helps industries such as finance, healthcare, and e-commerce manage and extract insights from complex datasets.
Developed under the Apache Software Foundation, Hadoop has evolved into a robust ecosystem with various components that extend its capabilities. Its open-source nature allows developers and businesses to customize and optimize it for specific data processing needs, making it one of the most widely adopted big data technologies today.
History of Hadoop
Hadoop traces its origins to Google’s MapReduce and Google File System (GFS), which were designed to handle large-scale data processing across distributed systems. These technologies inspired the development of an open-source framework that could replicate similar functionality for broader applications.
Doug Cutting and Mike Cafarella played a key role in creating Hadoop while working on the Nutch search engine project in the early 2000s. They needed a way to process massive amounts of web data efficiently, leading them to develop Hadoop as an independent project. Doug Cutting named it after his son’s toy elephant, and it later became part of the Apache Software Foundation.
Since its inception, Hadoop has evolved into a leading big data framework, expanding beyond its original MapReduce model to include a full ecosystem of tools such as Apache HDFS, YARN, and Apache Hive. Today, it remains a foundational technology for processing and analyzing big data across industries.
Hadoop Architecture and Core Components
Hadoop follows a distributed architecture, allowing it to process vast amounts of data efficiently. It consists of four core components: HDFS, MapReduce, YARN, and Hadoop Common, each playing a crucial role in data storage, processing, resource management, and system utilities.
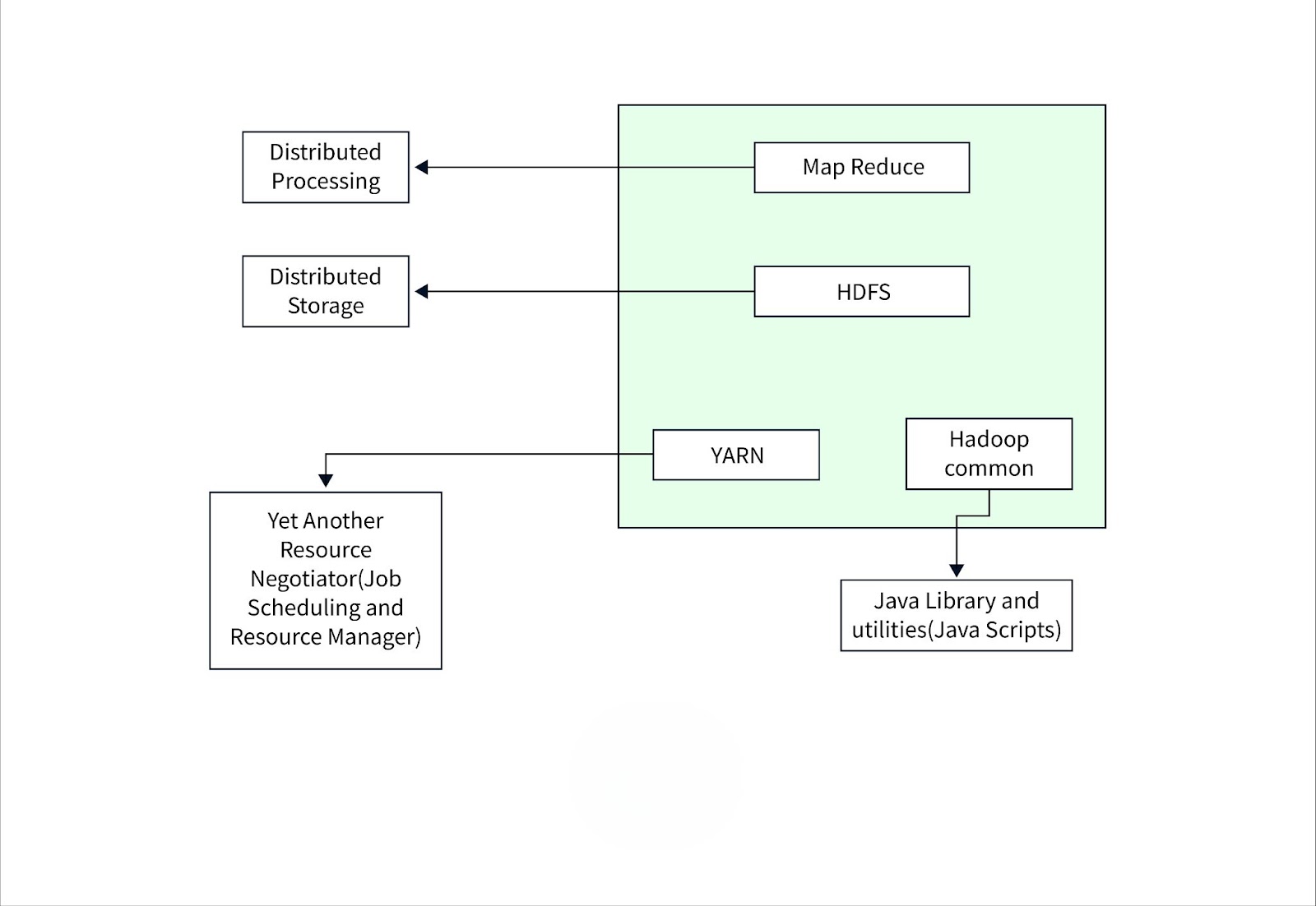
1. Hadoop Distributed File System (HDFS)
HDFS is the primary storage system in Hadoop, designed to handle large datasets by distributing them across multiple nodes. It enables fault tolerance, high availability, and scalability, making it ideal for storing and managing big data.
Key Features of HDFS:
- Block Storage: Large files are divided into fixed-size blocks (default 128MB or 256MB).
- Replication: Each block is replicated (default: 3 copies) across different nodes to ensure data redundancy.
- Fault Tolerance: If a node fails, the system retrieves data from replicated blocks on other nodes.
hdfs dfs -mkdir /user/hadoop/data
hdfs dfs -put localfile.txt /user/hadoop/data/2. MapReduce Processing Model
MapReduce is Hadoop’s batch-processing framework, designed for parallel data processing. It consists of two key phases:
- Map Function: Processes input data, applies a transformation, and generates key-value pairs.
- Reduce Function: Aggregates and processes key-value pairs from the Map phase to generate final results.
Example: Word Count Program in MapReduce (Python)
from mrjob.job import MRJob
class WordCount(MRJob):
def mapper(self, _, line):
for word in line.split():
yield word, 1
def reducer(self, word, counts):
yield word, sum(counts)
if __name__ == '__main__':
WordCount.run()This program counts occurrences of each word in a given dataset using MapReduce parallel processing.
3. Yet Another Resource Negotiator (YARN)
YARN is responsible for job scheduling and resource management in Hadoop. It allows multiple applications to run on a shared Hadoop cluster, optimizing CPU, memory, and disk usage.
Key Functions of YARN:
- ResourceManager: Allocates cluster resources dynamically.
- NodeManager: Monitors and manages resource usage on each node.
- ApplicationMaster: Manages application execution across the cluster.
YARN Code Example (Submitting a Job in YARN):
yarn jar hadoop-mapreduce-examples.jar wordcount input_dir output_dir 4. Hadoop Common
Hadoop Common provides the utility tools and libraries required for running Hadoop. It includes:
- Configuration APIs for Hadoop’s core components.
- Java libraries needed for integration with third-party applications.
- File System Abstractions for connecting to HDFS and other storage systems.
Without Hadoop Common, the ecosystem’s core functionalities like file access, I/O operations, and system logging would not be possible.
These four components form the foundation of Hadoop’s scalable, distributed architecture, making it a powerful tool for processing and analyzing large datasets efficiently.
How Hadoop Works?
Hadoop processes large datasets by distributing storage and computation across multiple machines in a cluster. The workflow involves storing data in HDFS, processing it with MapReduce, and managing resources with YARN.
- Data Ingestion: Raw data (e.g., transaction logs, sensor data) is loaded into HDFS using tools like Apache Sqoop or Flume.
- Data Storage in HDFS: The data is split into blocks and replicated across nodes for fault tolerance.
- Job Submission: A Hadoop job (such as a MapReduce task) is submitted via YARN.
- Data Processing with MapReduce:
- The Map function transforms the input data into key-value pairs.
- The Reduce function aggregates and processes the results.
- Output Storage: The final processed data is stored back into HDFS or exported to external databases like Apache Hive or HBase for further analysis.
Real-World Example: Processing E-Commerce Transaction Logs
Consider an e-commerce company analyzing transaction logs to identify popular products. Hadoop can process massive log files efficiently:
- Step 1: Load transaction logs into HDFS.
- Step 2: Use MapReduce to count the occurrences of each purchased product.
- Step 3: Store the aggregated results in HDFS for reporting.
Python Code (MapReduce for Counting Product Sales):
from mrjob.job import MRJob
class ProductSalesCount(MRJob):
def mapper(self, _, line):
fields = line.split(",") # Assuming CSV format (ProductID, UserID, Price)
yield fields[0], 1
def reducer(self, product, counts):
yield product, sum(counts)
if __name__ == '__main__':
ProductSalesCount.run()Hadoop enables businesses to analyze large-scale data efficiently, improving decision-making in industries like finance, healthcare, and retail.
Features of Hadoop
Hadoop is widely adopted for big data processing due to its scalability, fault tolerance, distributed processing, and cost-effectiveness. These features make it a powerful framework for handling large datasets efficiently.
- Scalability: Hadoop can scale horizontally by adding more nodes to the cluster, allowing it to handle petabytes of data. Unlike traditional systems, it does not require high-end hardware, making it ideal for organizations with growing data needs.
- Fault Tolerance: HDFS ensures data availability and reliability through automatic replication. By storing multiple copies of data across different nodes, Hadoop prevents data loss in case of hardware failure, making it highly resilient.
- Distributed Processing: Hadoop divides large datasets into smaller chunks and processes them in parallel across multiple nodes, significantly improving execution speed. This distributed model enables efficient big data analytics, even on commodity hardware.
- Open-Source: Developed under the Apache Software Foundation, Hadoop is an open-source framework, allowing businesses to adopt it without licensing costs. Its extensibility and integration with other big data tools like Apache Spark, Hive, and HBase make it a flexible choice for enterprise applications.
Hadoop Ecosystem and Common Frameworks
The Hadoop ecosystem consists of various tools and frameworks that enhance its data processing capabilities. These components enable efficient data storage, querying, analysis, and real-time processing, making Hadoop a versatile big data solution.
1. Apache Hive – Data Warehousing & SQL-like Querying
Apache Hive is a data warehousing framework built on Hadoop that enables users to perform SQL-like queries using HiveQL. It simplifies big data analytics for users familiar with SQL, making Hadoop more accessible to data analysts.
- Converts HiveQL queries into MapReduce jobs for execution.
- Ideal for structured and semi-structured data processing.
- Used for business intelligence and reporting applications.
2. Apache Pig – High-Level Scripting for Large Datasets
Apache Pig provides a high-level scripting language (Pig Latin) for processing large datasets in Hadoop. It abstracts complex MapReduce tasks, making it easier to write data transformation scripts.
- Used for ETL (Extract, Transform, Load) operations.
- Handles unstructured and semi-structured data efficiently.
- Preferred by data engineers for pipeline automation.
3. Apache HBase – NoSQL Database for Real-Time Data Access
Apache HBase is a NoSQL database designed for handling large-scale, real-time data on Hadoop. Unlike traditional relational databases, HBase provides fast read and write access to massive datasets.
- Supports random and real-time data access in Hadoop.
- Ideal for applications requiring low-latency data retrieval, such as IoT and financial systems.
- Works seamlessly with HDFS and Apache Phoenix for structured querying.
4. Apache Spark – Faster In-Memory Processing
Apache Spark is a high-speed data processing engine that improves upon Hadoop’s batch-processing limitations by offering in-memory computation. It is widely used for real-time analytics, machine learning, and big data streaming applications.
- 100x faster than MapReduce for iterative tasks.
- Supports multiple languages, including Python, Scala, and Java.
- Integrates with Hadoop, Hive, and HBase for advanced analytics.
Advantages and Disadvantages of Hadoop
Hadoop offers significant advantages in big data processing, but it also has some limitations that organizations need to consider.
Advantages
- Cost-Effective – Being an open-source framework, Hadoop eliminates licensing costs and runs on commodity hardware, reducing infrastructure expenses.
- Handles Structured & Unstructured Data – Supports diverse data formats, including text, images, videos, and sensor data, making it highly versatile for various industries.
- Scalability – Can scale horizontally by adding more nodes, allowing organizations to process petabytes of data efficiently.
- Fault Tolerance – Automatic data replication across nodes ensures system reliability, even in case of hardware failures.
Disadvantages
- High Learning Curve – Hadoop requires expertise in Java, MapReduce, and HDFS, making it challenging for beginners without programming experience.
- Latency Issues – Hadoop’s batch processing model (MapReduce) is not ideal for real-time analytics, making it less suitable for applications requiring instant insights.
- Storage Overhead – The default data replication (3 copies per block) increases storage requirements significantly, impacting cost efficiency.
Despite its limitations, Hadoop remains a powerful big data framework, particularly for organizations dealing with large-scale data storage and batch processing needs.
Future of Hadoop and Its Relevance in Big Data
Hadoop continues to be a key player in big data processing, but its role is evolving as newer technologies like Apache Spark gain popularity.
Shift from Hadoop MapReduce to Apache Spark
Many organizations are moving away from Hadoop’s MapReduce framework in favor of Apache Spark, which offers in-memory processing and faster data analytics. While MapReduce is efficient for batch processing, Spark provides superior performance for real-time analytics, machine learning, and iterative computations.
Role of Hadoop in Cloud-Based Big Data Solutions
With the rise of cloud computing, Hadoop is being integrated with platforms like Amazon EMR, Google Cloud Dataproc, and Microsoft Azure HDInsight. These services allow businesses to scale their Hadoop clusters dynamically, reducing infrastructure costs while leveraging cloud storage and computing power.
Future Trends in Hadoop Adoption
Despite the shift toward real-time analytics, Hadoop remains relevant in:
- Enterprise data lakes for storing and managing massive datasets.
- Hybrid cloud architectures combining on-premise and cloud-based Hadoop solutions.
- Industry-specific big data applications, including finance, healthcare, and retail.
Hadoop’s future lies in hybrid data environments, where it works alongside modern big data frameworks, ensuring it remains a crucial part of enterprise analytics strategies.
Read More:
References: