Data preparation is a critical yet often overlooked phase in data science and analytics projects. It involves the process of cleaning, transforming, and organizing raw data to ensure it’s ready for analysis. This step serves as the foundation for successful data analysis, directly influencing the accuracy of models and the quality of insights derived from data.
Without proper data preparation, even the most sophisticated algorithms can produce inaccurate results. In this article, we’ll delve into what data preparation entails, why it’s essential for data-driven projects, and how it helps in creating cleaner, well-structured datasets that enhance model performance and decision-making.
What is Data Preparation?
Data preparation refers to the process of transforming raw, unstructured, or inconsistent data into a clean and organized format that can be used for analysis. This stage is crucial in the data science workflow as it ensures that the data is of high quality and ready for further use in modeling, reporting, or visualization.
The primary goals of data preparation are to enhance data quality, remove inconsistencies, and improve the usability of data. By cleaning and structuring the data, you reduce the risk of errors and inaccuracies in your analysis. Whether the data is coming from multiple sources or in different formats, data preparation helps ensure that it can be integrated seamlessly into the analytics process.
Why is Data Preparation Important?
The importance of data preparation lies in its ability to drastically improve the quality of data used for analysis and modeling. Poorly prepared data often leads to faulty conclusions, inaccurate models, and poor decision-making. Incomplete or inconsistent datasets can result in skewed insights, leading organizations down the wrong path.
The Impact of Poor Data
Poor data, such as missing values, duplicates, or erroneous entries, can introduce significant biases in the analysis. For instance, if an AI model is trained on unclean data, it may fail to generalize well in real-world scenarios, leading to inaccurate predictions.
Benefits of Proper Data Preparation
Data preparation offers several key benefits:
- Cleaner datasets: Ensures that data is free from errors and inconsistencies.
- Better insights: Clean and well-organized data allows for more accurate analysis and reporting.
- Reduced errors: By identifying and resolving data quality issues early, data preparation helps reduce the risk of errors during the analysis phase.
Impact on Machine Learning and AI
Data preparation is particularly critical in machine learning and AI projects. Since these models rely on large amounts of data, the quality of the data directly impacts their performance. Properly prepared data leads to better feature selection, more accurate models, and ultimately, more reliable predictions and insights.
Steps in the Data Preparation Process
Data preparation follows a series of key steps designed to ensure the data is clean, structured, and ready for analysis:
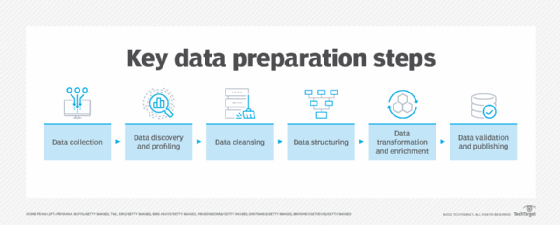
1. Data Collection
The first step in data preparation involves gathering data from various sources. These sources can include databases, spreadsheets, APIs, or external datasets. To ensure comprehensive analysis, it’s important to gather a wide variety of data, both in terms of volume and type.
- Objective: Collect sufficient and relevant data for the project.
- Outcome: A diverse and comprehensive dataset ready for further profiling.
2. Data Discovery and Profiling
Once the data is collected, it’s time to analyze its characteristics. Data profiling helps in understanding the structure, distributions, and trends within the dataset, as well as identifying any potential issues such as outliers or missing values.
- Objective: Understand the data’s basic properties and detect irregularities.
- Outcome: A detailed profile of the dataset, highlighting trends and areas of concern.
3. Data Cleansing and Validation
This is one of the most important steps in data preparation. Data cleansing involves identifying and correcting any errors, inconsistencies, or duplicates in the dataset. Validation ensures that the data is accurate, complete, and free of errors.
- Objective: Ensure the accuracy and integrity of the dataset.
- Outcome: A clean, error-free dataset that’s ready for transformation.
4. Data Structuring
In this step, the data is organized into a structured format, such as a table or relational database. This involves removing irrelevant information and ensuring that the data is stored in a logical, accessible format for easy analysis.
- Objective: Structure the data for ease of access and analysis.
- Outcome: A well-organized dataset that’s easy to work with.
5. Data Transformation and Enrichment
Raw data often needs to be transformed into a format that is suitable for analysis. This can include converting data types, normalizing values, or applying feature engineering techniques. Enrichment involves adding additional attributes to the dataset, such as timestamps, labels, or external data, to enhance its value.
- Objective: Convert raw data into a usable format and add value to the dataset.
- Outcome: A transformed dataset that’s ready for analysis, with enriched features.
6. Data Validation and Publishing
The final step involves validating the prepared data to ensure it meets the required standards and is ready for analysis. After validation, the data is stored or published for use in further analytics processes.
- Objective: Ensure the data is accurate and analysis-ready.
- Outcome: A validated dataset, stored or published for further use in modeling or reporting.
Tools For Data Preparation
There are several tools available that streamline the data preparation process, making it easier to clean, structure, and transform data.
Popular Tools for Data Preparation
- Talend: A comprehensive data integration tool that automates data preparation tasks, enabling seamless data cleaning, transformation, and validation.
- Trifacta: A powerful tool designed for data wrangling, making it easy to prepare and structure data for analysis.
- Alteryx: A self-service data preparation platform that allows users to automate and simplify complex data preparation tasks.
- Pandas (Python Library): A flexible, open-source library in Python used for data manipulation, cleansing, and transformation in data science projects.
- OpenRefine: An open-source tool for working with messy data, particularly useful for cleaning and transforming unstructured data.
Feature Comparison
Different tools offer varying levels of automation, ease of use, and integration with big data platforms. For instance, platforms like Talend and Alteryx offer robust automation features, making them suitable for large-scale projects, while Pandas provides greater flexibility for developers working with custom data processing workflows.
Self-Service Data Preparation Tools
For business users who don’t have a technical background, self-service tools like Trifacta and Alteryx provide an intuitive interface that allows non-programmers to clean, transform, and prepare data without relying on data scientists.
Challenges in Data Preparation
Data preparation, while essential, is not without its challenges. Some common obstacles include:
1. Handling Large Datasets
Working with large datasets can be resource-intensive and time-consuming. Processing and cleaning massive amounts of data requires significant computing power and storage capabilities.
2. Ensuring Data Privacy
Data privacy is a critical concern, especially when dealing with sensitive or personal information. Ensuring that data collection, cleaning, and preparation adhere to privacy regulations such as GDPR or CCPA is essential to avoid legal issues.
3. Managing Unstructured Data
Unstructured data, such as text, images, and videos, presents additional challenges for data preparation. Unlike structured data, unstructured data requires specialized techniques for cleaning and organizing before it can be analyzed.
4. Dealing with Missing or Incomplete Data
Missing or incomplete data is a common issue that can significantly impact the quality of analysis. Handling missing data requires careful consideration, as removing or imputing missing values can introduce biases into the dataset.
5. Time and Resource Constraints
Data preparation can be a time-consuming process, especially in large-scale projects. Balancing the need for clean, well-structured data with time and resource constraints is a common challenge in data preparation.
Conclusion
Data preparation is a vital step in ensuring the quality and reliability of data used in analytics, machine learning, and artificial intelligence projects. Without clean, well-structured data, even the most advanced algorithms can fail to produce accurate insights. By following a structured approach to data collection, cleansing, transformation, and validation, organizations can ensure that their data is ready for meaningful analysis.
The right tools, best practices, and careful attention to detail throughout the data preparation process can make a significant difference in the success of data-driven projects. With well-prepared data, data scientists and analysts can make informed decisions, build more accurate models, and ultimately drive better outcomes in their projects.
References:
- What is Data Preparation?
- What is Data Preparation? Processes and Example | Talend
- Data Preparation in Data Science. Data preparation: – | by Swapnil Bandgar | Analytics Vidhya | Medium


