Data modeling is the process of creating a visual representation, or blueprint, of a system’s data. It provides a structured way to organize and standardize how data is stored, processed, and retrieved, ensuring consistency and clarity in data management. By using data models, organizations can understand their data relationships, streamline workflows, and improve decision-making through reliable data insights.
In today’s data-driven world, effective data modeling is crucial for ensuring that businesses can leverage their data efficiently. Whether you’re designing a new database system or refining an existing one, data models serve as a roadmap that guides both technical and non-technical stakeholders in understanding how data flows through an organization.
What is a Data Model?
A data model is a visual or conceptual representation of how data is structured and organized within a system. It defines the data elements and their relationships, acting as a blueprint for building databases and ensuring that data is organized in a logical, consistent manner. The goal of data modeling is to provide a clear, standardized view of the data that can be easily understood by all stakeholders, from database designers to business analysts.
Data models are essential in defining how data is stored, accessed, and managed, which in turn supports accurate reporting, analysis, and decision-making across organizations. They help prevent data inconsistencies and redundancies by providing a well-structured framework for managing data throughout its lifecycle.
What is Data Modeling?
Data modeling is the process of designing the structure of a database or information system through the creation of data models. The purpose of data modeling is to ensure that data is stored and represented in a way that facilitates efficient data retrieval, updates, and analysis. It involves understanding the data requirements, identifying key entities, and defining the relationships between them.
The main objectives of data modeling include:
- Ensuring data consistency and accuracy.
- Facilitating communication between stakeholders (business and technical teams).
- Supporting scalability by anticipating future data requirements.
- Improving decision-making through well-organized and accessible data.
The Data Modeling Process (Step-by-step Breakdown)
Data modeling follows a structured process that ensures a systematic approach to organizing data within a system. Below is a step-by-step breakdown of the key stages involved in the data modeling process:
1. Data Analysis and Requirements Gathering
The first step involves analyzing the business requirements and understanding the type of data that will be used. This phase includes gathering information about what data needs to be stored, how it will be accessed, and what relationships exist between the data elements. Stakeholders collaborate to identify key data entities and establish data use cases.
2. Conceptual Modeling
Conceptual modeling is the high-level representation of data, focusing on the entities, their attributes, and the relationships between them. The objective is to provide an overview of the system’s data requirements without going into technical details. It serves as a bridge between business requirements and the technical design of the data system.
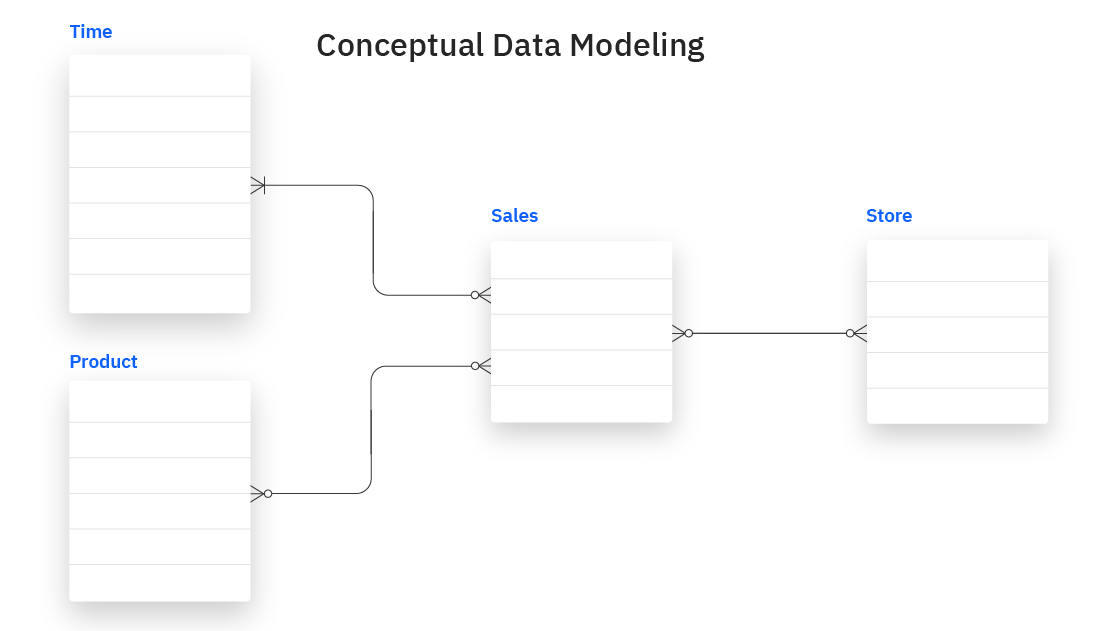
Source: IBM
3. Logical Modeling
Logical modeling involves adding more detail to the conceptual model, such as defining the data types and structuring the relationships between entities. At this stage, the model describes how the data will be logically stored without specifying the actual database technology or system. It also includes constraints, such as unique identifiers and relationships like one-to-many or many-to-many.
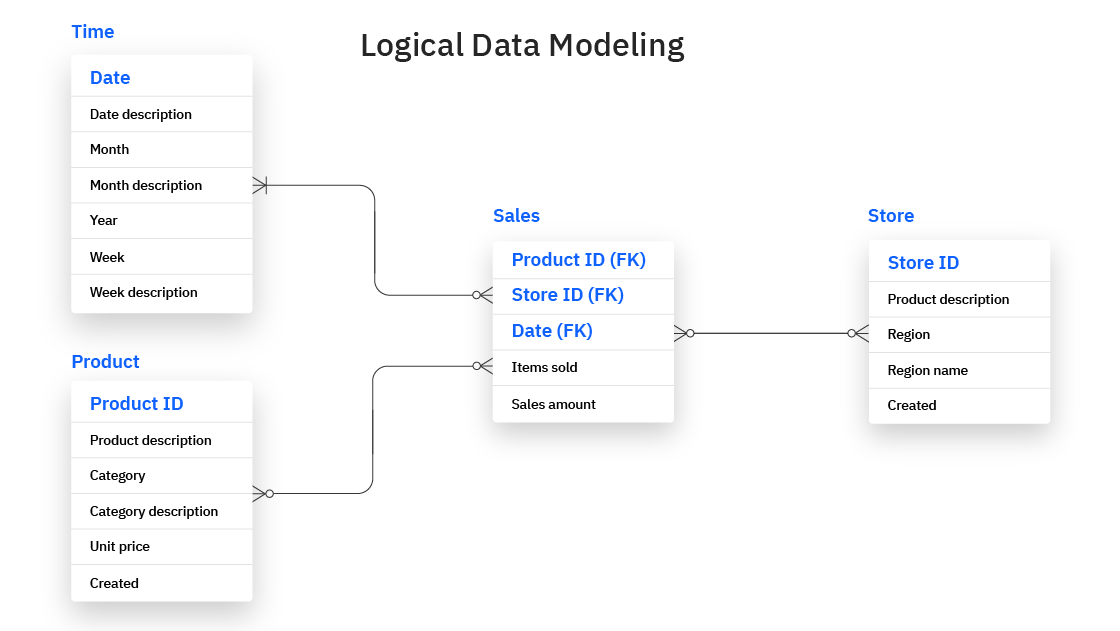
Source: IBM
4. Physical Modeling
Physical modeling is where the logical model is translated into a physical database design. This stage specifies how data will be stored on disk, including table structures, indexes, and partitioning. Physical modeling takes into account the performance and optimization needs of the database system, such as storage space and access speed.

Source: IBM
5. Implementation and Maintenance
Once the physical model is in place, the database or information system is implemented. Data is loaded into the system, and the structure is regularly maintained to ensure optimal performance. This stage also includes monitoring for any necessary updates or adjustments based on changing data requirements or system improvements.
Levels of Data Abstraction
Data abstraction refers to the process of hiding the complexities of how data is stored and managed, focusing instead on different levels of interaction with the data. Data modeling typically involves three levels of abstraction: conceptual, logical, and physical. Each level provides a distinct perspective on the data, catering to different stakeholders and phases of the modeling process.
1. Conceptual Level
The conceptual level is the highest level of abstraction. It represents a high-level, simplified view of the entire system, focusing on the main data entities, their attributes, and the relationships between them. This model is technology-agnostic, providing a general understanding of how data will be organized to meet business requirements. It’s primarily used to communicate with business stakeholders to ensure that the data system aligns with their needs.
2. Logical Level
At the logical level, the focus shifts from business needs to how the data will be structured and organized in the database. Here, the model defines data types, relationships, and constraints, but without specifying how the data will be stored physically. Logical modeling refines the conceptual model, incorporating details such as keys, indexes, and relationships like one-to-many or many-to-many. It is primarily used by database designers and developers to plan the structure of the database.
3. Physical Level
The physical level is the lowest level of abstraction and focuses on how the data is physically stored in the database. This model includes specific details such as tables, columns, indexes, partitioning, and storage formats. It also considers performance factors like disk space and access speeds. The physical model translates the logical model into a working database system that can store, retrieve, and manage data efficiently.
Data Modeling Examples
Data models come in various forms, each tailored to meet specific data management needs. One of the most commonly used models is the Entity-Relationship (ER) Model, which helps represent entities and their relationships within a system. This section explores how the ER model works and how it can be applied in different scenarios.
ER (Entity-Relationship) Model
The Entity-Relationship (ER) Model is a conceptual data model that represents the key entities in a system, the attributes that define them, and the relationships between these entities. It visually depicts how data elements are interconnected, making it easier to design and understand the structure of the database.
Key components of an ER Model include:
- Entities: Objects or concepts, such as “Customer” or “Order,” that are stored in the database.
- Attributes: Properties of entities, like “Customer Name” or “Order Date,” that describe each entity in detail.
- Relationships: Associations between entities, such as a customer placing an order, depicted as a relationship between the “Customer” and “Order” entities.
For example, in an e-commerce system, you might have entities such as Customer, Order, and Product. The relationships between these entities could indicate which customers have placed orders and which products are part of each order.
ER models are a vital tool for translating business requirements into database designs, making them popular in both small and large-scale database development.
Benefits of Data Modeling
Data modeling provides a wide range of advantages for organizations by offering a clear framework for managing, storing, and retrieving data. Proper data modeling enhances the quality and usability of data, leading to better decision-making and operational efficiency.
1: Improved Data Quality
By creating a structured representation of data, data modeling helps ensure accuracy, consistency, and completeness. This reduces the likelihood of data errors, duplicates, and inconsistencies, leading to cleaner, more reliable datasets.
2: Enhanced Data Consistency
Data models standardize the way data is organized and processed across systems, ensuring that all stakeholders are working with the same definitions and formats. This consistency improves collaboration and communication across departments, reducing confusion and errors.
3: Facilitated Communication
Data models act as a bridge between technical teams (like database developers) and non-technical stakeholders (like business analysts). They provide a clear and visual way to represent complex data structures, ensuring that everyone involved understands how data flows within the system.
4: Improved Decision-Making
With structured, well-organized data, businesses can make more informed decisions based on accurate and timely insights. Data models ensure that data is accessible and easy to retrieve, enabling faster analysis and more effective decision-making.
5: Enhanced Data Management
Data models provide a blueprint for how data should be stored and managed, improving overall data governance. They make it easier to manage data throughout its lifecycle, from creation to archiving, and ensure that databases are optimized for performance.
Limitations of Data Modeling
While data modeling offers numerous advantages, there are some challenges and drawbacks associated with the process. It’s important to understand these limitations to effectively plan and manage data modeling efforts.
1: Complexity
Data modeling can become highly complex, especially in large organizations with vast amounts of data. Designing a model that accurately represents all data elements, relationships, and business rules can be a time-consuming and intricate process. The complexity can also lead to difficulties in maintaining and updating the model as data requirements evolve.
2: Time-Consuming
The process of creating detailed data models requires significant time and effort. From gathering requirements to designing, implementing, and validating the model, each stage demands attention to detail. This time investment can delay projects, particularly in fast-paced environments where data needs are constantly changing.
3: Potential for Inconsistencies
Despite the benefits of data modeling, inconsistencies can arise if models are not properly maintained. Changes to the business requirements or data can lead to discrepancies between the model and the actual data. Additionally, if multiple teams are working on different parts of the model without proper coordination, inconsistencies can emerge in how data is defined and managed.
Evolution of Data Modeling
Data modeling has evolved significantly over the years, adapting to the changing needs of data management and advancements in technology. From its early stages to modern developments, data modeling continues to play a crucial role in how organizations store and utilize data.
1: Early Development
Data modeling began as a way to represent and organize data in the early days of database management systems (DBMS). Early models, such as the Hierarchical and Network Models, focused on establishing clear relationships between data elements in structured systems. These early models provided a foundation for the development of more sophisticated modeling approaches.
2: Relational Model
The introduction of the Relational Model by Edgar F. Codd in the 1970s revolutionized data modeling. The relational model emphasized the organization of data into tables, allowing for more flexibility and scalability. It became the foundation for most modern databases and is still widely used today.
3: Emergence of NoSQL and Big Data
With the rise of Big Data and unstructured data in recent decades, new types of databases emerged, such as NoSQL databases. These databases, including document, graph, and columnar databases, required new data modeling techniques to handle semi-structured and unstructured data. The focus shifted toward greater flexibility and scalability to accommodate the growing volume and variety of data
Current Trends
Today, data modeling continues to evolve with the integration of AI and machine learning, driving automation in the modeling process. Automated data modeling tools now assist in creating complex models more efficiently, reducing manual effort. Additionally, cloud-based data storage and processing have influenced data modeling approaches, promoting scalability and real-time access to data.
Types of Data Modeling
There are three primary types of data modeling, each serving a specific purpose in the data modeling process. These types—conceptual, logical, and physical—represent different levels of abstraction, helping to structure data at varying degrees of detail.
1. Conceptual Model
The Conceptual Model is the highest level of abstraction in data modeling. It provides an overview of the system’s data, focusing on the main entities and relationships between them, without including technical details. This model is primarily used to communicate with non-technical stakeholders, such as business users, to ensure the data structure aligns with business goals.
- Purpose: Captures the overall structure and key relationships of the system.
- Audience: Business stakeholders and data architects.
- Key Components: Entities, attributes, relationships.
2. Logical Model
The Logical Model adds more detail to the conceptual model by defining how data will be logically structured within the system. This model outlines the data types, keys, and relationships but does not include physical storage details. Logical modeling ensures that the system’s data can be organized efficiently and meet business requirements.
- Purpose: Defines the structure of data, including attributes, data types, and relationships.
- Audience: Data architects, database designers, and developers.
- Key Components: Data types, relationships, keys (primary, foreign), constraints.
3. Physical Model
The Physical Model is the most detailed level of data modeling, specifying how the data will be stored in the database. This model includes details about tables, indexes, partitions, and storage formats. It focuses on optimizing performance and ensuring that data is stored in a way that meets technical and business needs.
- Purpose: Describes how data will be physically implemented in a database.
- Audience: Database administrators, IT teams, developers.
- Key Components: Tables, columns, indexes, partitions, storage configurations.
Data Modeling Techniques or Process
Data modeling involves a variety of techniques and processes designed to help organize, structure, and visualize data. These techniques ensure that the data model accurately reflects the needs of the business and supports efficient data management.
Common Data Modeling Techniques
- Entity-Relationship Diagram (ERD) The ERD is one of the most commonly used data modeling techniques. It visually represents the entities in a system and the relationships between them. ERDs help map out how different data elements interact, making it easier to define relationships and avoid redundancy.
- Normalization Normalization is the process of organizing data to reduce redundancy and improve data integrity. It involves dividing a large table into smaller, more manageable tables while maintaining relationships between them. Normalization typically follows a series of steps known as “normal forms.”
- Denormalization The opposite of normalization, denormalization combines data from related tables into a single table to reduce the complexity of queries and improve performance. This technique is often used in systems that prioritize read performance over storage efficiency.
- Dimensional Modeling Dimensional modeling is commonly used in data warehousing and business intelligence environments. It organizes data into fact tables and dimension tables to support complex queries and analysis, especially in OLAP (Online Analytical Processing) systems.
- Hierarchical Modeling Hierarchical modeling represents data as a tree structure, where each record has a single parent and one or more child records. This model is ideal for representing hierarchical relationships, such as organizational structures or file directories.
The Data Modeling Process
- Define Business Requirements: Understand the goals and data needs of the business.
- Create Conceptual Model: Develop a high-level representation of the key entities and relationships.
- Develop Logical Model: Add more detail to define data structures, types, and relationships.
- Create Physical Model: Translate the logical model into a physical database schema.
- Validate and Refine: Ensure the model aligns with business requirements and technical constraints.
Data Modeling Tools
Data modeling tools are essential for helping businesses create, visualize, and manage data models efficiently. These tools provide a user-friendly interface for designing conceptual, logical, and physical data models, streamlining the process and ensuring consistency in data management.
Popular Data Modeling Tools
- ER/Studio ER/Studio is a powerful tool designed for data modeling and database design. It supports various types of data models (conceptual, logical, and physical) and offers collaboration features that allow teams to work together on the same model.
- Key Features: Collaboration, reverse engineering, support for multiple database platforms.
- Oracle SQL Developer Data Modeler Oracle SQL Developer Data Modeler is a free tool that simplifies data modeling tasks. It supports data design at the logical and physical levels, making it easy to generate database schemas from the models.
- Key Features: Forward and reverse engineering, comprehensive data modeling, SQL code generation.
- IBM InfoSphere Data Architect IBM InfoSphere Data Architect is a robust tool that integrates data modeling with enterprise data management. It allows users to create and manage data models, as well as ensure compliance with business rules and standards.
- Key Features: Collaboration, governance, multi-platform support, automation of data models.
- Lucidchart Lucidchart is an easy-to-use, cloud-based tool for data modeling and diagramming. It is especially popular for creating Entity-Relationship Diagrams (ERDs), and it offers templates and drag-and-drop functionality for faster model creation.
- Key Features: Cloud-based, real-time collaboration, pre-built templates.
- PowerDesigner PowerDesigner by SAP is a comprehensive data modeling and database design tool. It supports a wide range of databases and offers strong integration with other SAP tools, making it ideal for enterprises.
- Key Features: Multi-model support, collaboration, strong integration with SAP tools.
Key Considerations for Choosing a Data Modeling Tool
- Platform Compatibility: Ensure the tool supports the database platforms you’re working with.
- Collaboration Features: Look for tools that allow multiple team members to work together seamlessly.
- Automation Capabilities: Tools that offer forward and reverse engineering help automate the creation of database schemas from data models.
Conclusion
Data modeling is a crucial process for structuring and organizing data efficiently. It ensures data consistency, improves quality, and facilitates better communication between business and technical teams. From conceptual to physical models, data modeling helps design databases that meet business needs and optimize data storage and access.
As data complexity grows, mastering data modeling becomes essential for creating scalable, robust systems. Whether you’re a data architect or developer, understanding data modeling ensures that your data infrastructure is efficient and ready for long-term use.