In the world of Data Science, data is the raw material – the numbers, text, images, and other observations that we collect and analyze. It’s the foundation upon which insights are built, predictions are made, and actions are taken. Without data, Data Science would be a field without substance, unable to unlock the hidden patterns and trends that shape our world.
Data vs. Information vs. Knowledge
While often used interchangeably, data, information, and knowledge represent distinct stages in the journey of understanding.
Data is simply raw facts and figures, devoid of context or meaning. Information is created when data is processed and organized, giving it structure and relevance. Knowledge, the highest level, emerges when information is interpreted and understood, leading to insights and the ability to make informed decisions.
Think of it like baking a cake. The ingredients are the data, the recipe is the information, and the delicious cake itself is the knowledge. Data Science is the baker, skillfully transforming raw ingredients into a delectable final product. Through a combination of statistical analysis, machine learning algorithms, and domain expertise, Data Scientists extract valuable knowledge from vast amounts of data, empowering businesses and individuals to make smarter choices and achieve their goals.
The Diverse World of Data
Data comes in various shapes and sizes, each with its unique characteristics and challenges.
1. Structured vs. Unstructured Data
Structured data is neatly organized and easily searchable, like information in a spreadsheet or database. It has predefined categories and formats, making it straightforward to analyze using traditional tools. Unstructured data, on the other hand, lacks this predefined structure. Examples include social media posts, emails, images, and videos. While rich in potential insights, extracting value from unstructured data often requires advanced techniques like natural language processing and image recognition.
2. Quantitative vs. Qualitative Data
Quantitative data deals with numbers and measurements. It’s objective and can be analyzed statistically. Think of things like age, height, temperature, or sales figures. Qualitative data, in contrast, describes qualities or characteristics. It’s subjective and often captured through text, images, or audio recordings. Examples include customer reviews, interview transcripts, or social media sentiment analysis.
3. Other Data Types
Beyond structured and unstructured, quantitative and qualitative, several other data types are encountered in Data Science:
- Big Data: Refers to massive datasets that are too large or complex to be handled by traditional data processing tools.
- Time-Series Data: Data collected over a period, such as stock prices or weather patterns.
- Geospatial Data: Data linked to specific locations, used in mapping and location-based analysis.
4. Data Sources in Data Science
Data Scientists gather data from various sources, including:
- Databases: Structured repositories of information.
- APIs: Interfaces that allow access to data from external sources.
- Web Scraping: Extracting data from websites.
- Social Media: Platforms like Twitter and Facebook offer a wealth of user-generated data.
- Sensors and IoT Devices: Collect data from the physical world.
Understanding the diverse types of data and their sources is crucial for Data Scientists. It allows them to select the appropriate tools and techniques to extract meaningful insights and drive informed decision-making.
The Data Processing Cycle
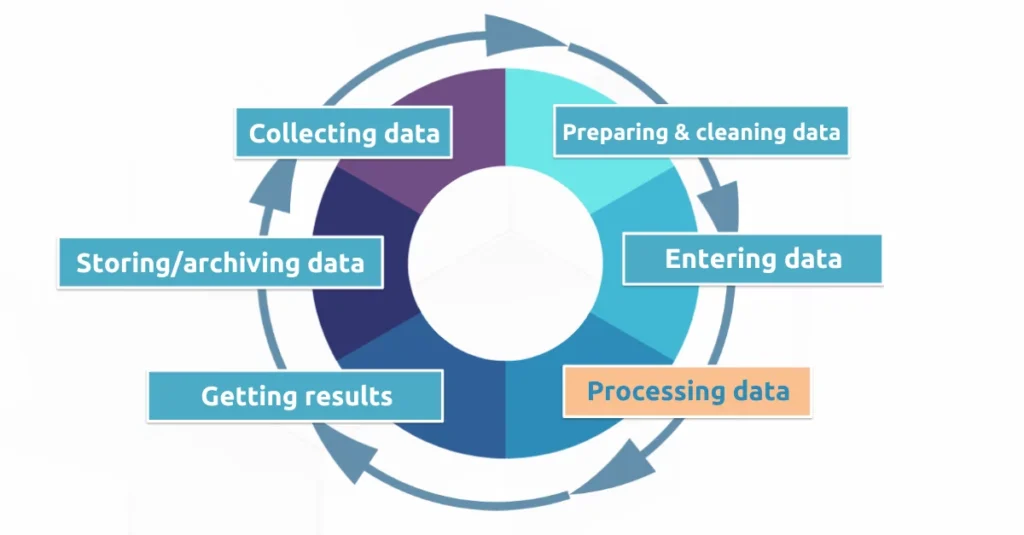
Data doesn’t magically transform into insights. It undergoes a series of stages, collectively known as the data processing cycle. This cycle is iterative, meaning the output of one stage often becomes the input for the next, leading to a continuous refinement of data and knowledge.
1. Data Collection:
This is where the journey begins. Data is gathered from various sources, including surveys, sensors, web scraping, APIs, and more. The quality of the data collected is paramount; garbage in, garbage out, as they say. Ensuring data accuracy, completeness, and relevance is crucial for subsequent stages.
2. Data Cleaning & Preprocessing:
Raw data is rarely perfect. It often contains errors, missing values, and inconsistencies. Data cleaning involves identifying and rectifying these issues. Preprocessing further prepares the data for analysis, which may include formatting, normalization, and feature engineering.
3. Data Transformation:
Once cleaned, data may need to be converted into a suitable format for analysis. This could involve aggregating data, creating new variables, or transforming data types.
4. Data Storage:
The processed data is then stored in a secure and accessible location, such as a database or cloud storage. Efficient storage allows for easy retrieval and analysis when needed.
Understanding the data processing cycle empowers Data Scientists to navigate the complexities of data handling, ensuring that the raw material is transformed into valuable insights that drive decision-making.
Data Analysis: Unveiling Insights
Data analysis is the beating heart of Data Science. It’s where the magic happens – where raw data is transformed into meaningful insights that drive decision-making. It’s about uncovering hidden patterns, trends, and relationships that might not be immediately apparent.
Key Techniques
Several powerful techniques are employed in data analysis:
- Exploratory Data Analysis (EDA): This initial step involves summarizing the main characteristics of the data, often through visualization. It helps Data Scientists understand the data’s distribution, identify outliers, and uncover potential patterns.
- Statistical Analysis: This encompasses a range of methods used to test hypotheses, quantify relationships, and make inferences about populations based on sample data. Common techniques include regression analysis, hypothesis testing, and ANOVA.
- Machine Learning: A subset of artificial intelligence, machine learning algorithms enable systems to learn from data and improve their performance on a specific task without being explicitly programmed. This is invaluable for prediction, classification, and pattern recognition.
- Data Visualization: Visual representations, such as charts, graphs, and maps, bring data to life, making it easier to understand and communicate findings to both technical and non-technical audiences.
Real-world Examples
Data analysis has a profound impact across industries, solving complex problems and driving innovation. For instance:
- In e-commerce, data analysis can predict customer churn, allowing businesses to take proactive measures to retain valuable customers.
- In finance, machine learning models detect fraudulent transactions, protecting both businesses and consumers.
- In healthcare, data analysis helps identify disease patterns and predict patient outcomes, leading to more personalized treatment plans.
Data analysis empowers organizations to make data-driven decisions, optimize operations, and gain a competitive edge. It’s the key to unlocking the full potential of data and transforming it into actionable knowledge.
Data Challenges and Ethical Considerations
Data Science isn’t without its hurdles. Ensuring data quality, maintaining privacy, and navigating ethical dilemmas are paramount.
1. Data Quality Issues
Incomplete, inaccurate, or biased data can skew analysis and lead to faulty conclusions. Identifying and addressing these issues is essential for reliable insights. Missing values, outliers, and inconsistencies must be handled carefully during the preprocessing stage.
2. Data Privacy & Security
As data collection grows, protecting sensitive information becomes critical. Data breaches can have devastating consequences, both for individuals and organizations. Implementing robust security measures, anonymizing data, and obtaining informed consent are crucial steps in safeguarding privacy.
3. Ethical Dilemmas
Data Science raises ethical questions that require thoughtful consideration. Algorithmic bias can perpetuate discrimination, while the misuse of data can have harmful consequences. Transparency, fairness, and accountability must be at the forefront of data practices. Data Scientists have a responsibility to ensure their work benefits society and doesn’t contribute to harm.
Conclusion
Data is the bedrock of Data Science, the raw material from which knowledge is extracted. Its various forms, sources, and processing stages culminate in powerful insights that drive innovation and decision-making. As our world becomes increasingly data-driven, the importance of Data Science will only continue to grow. If you’re ready to embark on a journey of discovery, countless online resources and courses can help you delve deeper into this fascinating field. The future belongs to those who can harness the power of data.


