Data collection is a fundamental step in the data science pipeline, setting the stage for meaningful analysis and model development. Without accurate and relevant data, even the most sophisticated algorithms will produce unreliable results. As the volume and variety of data grow, collecting high-quality data becomes critical for the success of data-driven projects.
In this article, we’ll explore what data collection entails, its importance in the data science workflow, and the methods and best practices that ensure the accuracy and reliability of data used in modeling and decision-making.
What is Data Collection?
Data collection is the systematic process of gathering, measuring, and analyzing information to extract insights and make informed decisions. It plays a crucial role in research, business, and data science by ensuring accurate and reliable data is available for decision-making.
Data collection in data science refers to the systematic gathering of information from a range of sources to be used for analysis, modeling, and decision-making. It plays a pivotal role in the data science process as it provides the raw material for deriving insights and predictions.
Accurate data collection is critical because poor-quality data leads to biased models and incorrect conclusions. High-quality data allows data scientists to develop models that accurately reflect real-world scenarios, ensuring that decisions based on these models are both effective and reliable. The relationship between data quality and model performance is direct—better data leads to better models and, consequently, better outcomes.
Key Terms Related to Data Collection
Understanding essential data collection terms ensures clarity in research, analytics, and AI-driven applications. Below are key concepts that play a crucial role in data quality and interpretation.
Population vs. Sample
- Population: The entire group from which data is collected. Example: A survey conducted on all customers of an e-commerce platform.
- Sample: A subset of the population used for analysis. Example: Surveying 1,000 customers from a million-user database.
A well-chosen sample ensures that conclusions are representative of the entire population, reducing time and costs while maintaining accuracy.
Raw Data vs. Processed Data
- Raw Data: Unstructured, unfiltered information directly collected from sources. Example: Sensor readings, survey responses, or web traffic logs.
- Processed Data: Cleaned, structured, and analyzed data ready for use. Example: Formatted reports, dashboards, and machine learning datasets.
Processed data removes inconsistencies and enhances insights for decision-making and predictive analytics.
Accuracy, Reliability, and Validity
- Accuracy: How close data is to the actual or true value.
- Reliability: Consistency in results when data is collected repeatedly.
- Validity: Whether the data measures what it’s intended to measure.
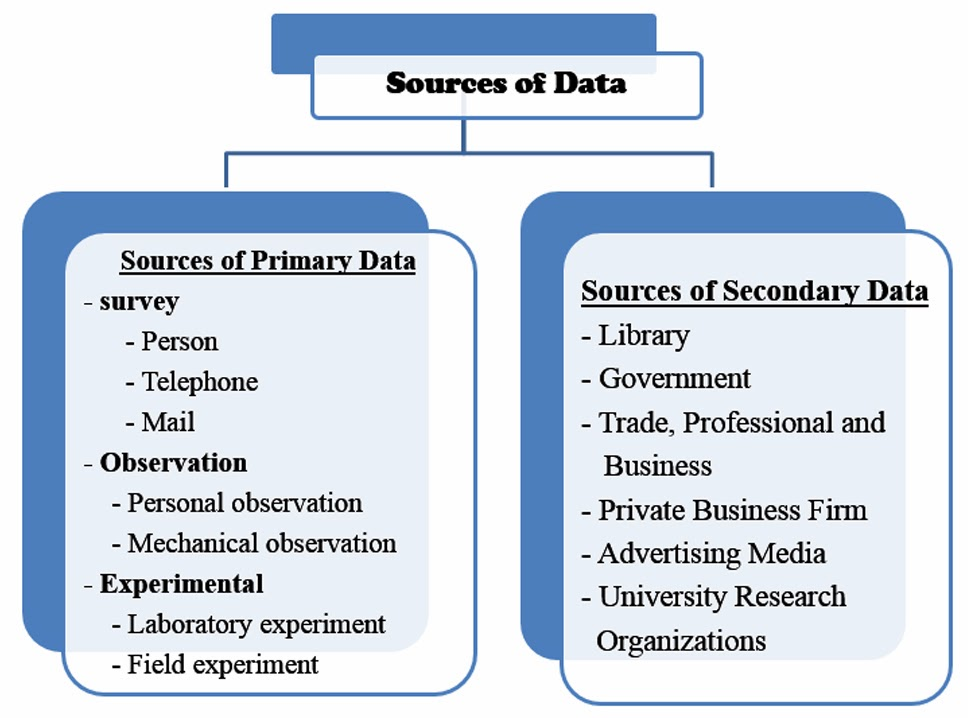
Types of Data Sources
Data can come from a variety of sources, each with its own advantages and use cases. Here are the key types of data sources commonly used in data science:
Sources: AnalysisProject
1. Primary Data
Primary data is collected firsthand through surveys, experiments, or observations. This type of data is highly specific to the problem at hand and allows for greater control over the data-gathering process.
Examples: Surveys conducted via online platforms, laboratory experiments, and field observations.
2. Secondary Data
Secondary data refers to information that has already been collected by others and is made available for analysis. It is often used to complement primary data or provide a broader context.
Examples: Public datasets from government databases, research publications, and data shared by organizations like the World Bank.
3. Real-time Data
Real-time data is continuously generated and collected from sources like IoT devices, live feeds, or streaming platforms. This data is invaluable in applications requiring up-to-the-minute information.
Examples: IoT sensor data, live social media feeds, and streaming weather data.
Methods of Data Collection in Data Science
There are various methods for collecting data in data science, each suited to different types of projects and data needs. Here are the most common methods:
1. Surveys and Questionnaires
Surveys and questionnaires are among the most widely used methods for gathering data directly from individuals or groups. These tools are particularly effective for collecting qualitative data such as opinions, preferences, and feedback.
When and How to Use: Surveys should be carefully designed to minimize bias, ensuring that the questions asked are relevant, clear, and objective. Surveys can be distributed digitally through platforms like Google Forms, SurveyMonkey, or Typeform. Proper design and deployment of surveys can lead to meaningful insights from targeted demographics.
Challenges: The accuracy of survey data heavily depends on the quality of the questions and the honesty of the respondents. Sampling bias and low response rates are common challenges that can skew the results.
2. Web Scraping
Web scraping is the process of automatically extracting data from websites. This method is particularly useful when data is not readily available through APIs or structured databases.
Tools and Techniques: Popular web scraping tools include Beautiful Soup, Selenium, and Scrapy. These tools allow for automated extraction of data from web pages, which can then be processed and analyzed.
Challenges: Web scraping comes with legal and ethical considerations, as some websites may restrict data extraction. Moreover, scraping often requires cleaning and structuring the data before it can be analyzed.
3. APIs (Application Programming Interfaces)
APIs provide a structured way to access data from various platforms. They are a popular method for collecting real-time data from social media platforms, financial markets, and other online services.
Using APIs: APIs such as the Twitter API, Google Maps API, and OpenWeather API are widely used in data science projects for collecting data. APIs provide a standardized format, making data collection easier and more efficient than web scraping.
Challenges: API data collection often involves handling rate limits, formatting issues, and processing large amounts of data, all of which can slow down the analysis process.
4. IoT and Sensor Data
IoT and sensor data are collected from physical devices connected to the internet. This type of data collection is particularly relevant for real-time applications such as predictive maintenance, health monitoring, and environmental tracking.
Overview: IoT sensors generate continuous streams of data that can be used to monitor conditions, detect anomalies, and predict future outcomes. For example, smart home devices can collect data on energy consumption or room temperature in real-time.
Challenges: The large volume of data generated by IoT devices requires robust infrastructure for storage, processing, and analysis. Additionally, ensuring the accuracy and security of IoT data is a common concern.
Step-by-Step Guide to Data Collection
Conducting effective data collection requires a systematic approach. Below is a step-by-step guide to ensure the data you collect is useful and accurate:
- Define the Problem Statement: Begin by clearly defining the business or research problem. Understanding what you aim to solve will help guide the entire data collection process, ensuring that only relevant data is gathered.
- Determine the Type of Data Needed: Decide whether you need qualitative or quantitative data, or perhaps a mix of both. Additionally, you should determine whether you need structured data (e.g., tabular data) or unstructured data (e.g., text, images).
- Select Data Sources: Based on the type of data needed, identify whether primary, secondary, or real-time data sources are most appropriate. For example, if you need data on customer behavior, web scraping or API data may be more suitable than surveys.
- Create a Timeline for Data Collection: Establish a clear timeline for when and how the data will be collected. Define specific checkpoints to track progress and address any issues that arise during the data collection process.
- Collect and Validate Data: As you collect data, ensure that it is clean and valid. Validation techniques include checking for inconsistencies, correcting errors, and handling missing data to avoid issues during the analysis phase.
Using APIs for Data Collection
APIs are one of the most effective ways to collect real-time data. Here’s how they work and why they are so popular in data science:
What are APIs?
APIs (Application Programming Interfaces) are protocols that allow different software applications to communicate with one another. In data science, APIs are often used to access large, dynamic datasets that would be difficult or time-consuming to collect manually.
Popular APIs for Data Science
- Twitter API: Used for collecting social media data, including tweets, hashtags, and user engagement.
- Google Maps API: Provides geolocation data, including coordinates, routes, and places.
- OpenWeather API: Offers real-time and historical weather data, making it useful for projects that require environmental insights.
Challenges in API Data Collection
While APIs simplify data collection, they come with challenges such as rate limits, which restrict the number of requests you can make in a given time. Additionally, API data often needs to be cleaned and formatted before it can be analyzed, adding extra steps to the workflow.
Example of Data Collection in Practice
Consider an e-commerce company looking to improve customer experience. The company collects data through:
- Primary Data Collection: Conducting customer surveys to gather direct feedback on shopping experience, website usability, and product preferences.
- Secondary Data Collection: Analyzing existing data sources, such as Google Analytics, purchase history, and social media reviews, to identify trends and customer behavior.
By combining primary and secondary data, the company gains comprehensive insights into customer satisfaction and areas for improvement.
Case Study: Data-Driven Decision-Making
A retail chain used data collection and analytics to optimize store layouts and inventory management.
Process:
- Installed smart sensors to track foot traffic patterns.
- Collected POS (Point-of-Sale) transaction data to identify high-demand products.
- Analyzed customer purchase behavior using AI-driven predictive models.
Results:
- Rearranged store aisles to maximize accessibility to popular products.
- Adjusted inventory to reduce overstocking and shortages.
- Increased sales by 15% through personalized promotions based on collected data.
Data Storage and Management in Data Science
Effective data collection is only part of the process—managing and storing that data is equally important.
- Storing Collected Data: Collected data must be securely stored to prevent loss or corruption. Options for storage include traditional databases, cloud-based solutions like Amazon S3, Google Cloud Storage, and Azure Data Lake, and on-premises servers for more secure or sensitive projects.
- Data Governance and Management: Data governance involves managing the availability, integrity, and security of data used in an organization. Best practices include ensuring controlled access, employing encryption techniques, and regularly auditing data usage to comply with privacy regulations.
Conclusion
Accurate and efficient data collection is essential for the success of any data science project. The quality of the data directly impacts the models and decisions that follow. By adhering to best practices and leveraging the right tools, data scientists can ensure that the data they collect is reliable, compliant with regulations, and ready for insightful analysis.
Whether collecting data through surveys, web scraping, APIs, or IoT devices, following these structured processes will lead to more informed decision-making and better outcomes for future projects.
FAQs
1. What is data collection, and why is it important?
Data collection is the process of gathering, measuring, and analyzing information for decision-making in various fields. It is crucial for businesses, research, and AI applications, enabling organizations to extract valuable insights, improve strategies, and optimize operations.
2. What are the different methods of data collection?
Data collection is categorized into:
- Primary Data Collection – Direct sources like surveys, interviews, observations, and experiments.
- Secondary Data Collection – Pre-existing data from research papers, online databases, and government reports.
3. What are the key tools used in data collection?
Tools include:
- Software: Google Analytics, SQL databases, Tableau, Python.
- Technologies: IoT sensors, AI-driven web scrapers, biometric devices.
- Manual Methods: Field surveys, interviews, and observations.
4. How do I choose the right data collection method for my research?
Consider:
- Research Goals: Qualitative vs. quantitative study.
- Data Sources: Primary vs. secondary data.
- Resource Constraints: Time, budget, and personnel.
5. What are the main differences between qualitative and quantitative data collection?
- Qualitative: Non-numerical data (opinions, behaviors). Example: Focus groups.
- Quantitative: Numerical data (statistics, metrics). Example: Sales figures.
6. What ethical considerations should be followed in data collection?
Data collection must ensure privacy, informed consent, security compliance (GDPR, HIPAA), and transparency to protect sensitive information.
7. What industries rely the most on data collection?
Industries like healthcare, marketing, finance, AI, logistics, and social sciences depend on data collection for research and informed decision-making.
References: