Apache Hive is an open-source data warehouse infrastructure built on top of the Hadoop ecosystem. Developed initially by Facebook to manage and analyze massive volumes of data, Hive provides a SQL-like interface—known as HiveQL—for querying and managing large datasets stored in the Hadoop Distributed File System (HDFS). Instead of requiring users to write complex MapReduce programs, Hive translates SQL queries into MapReduce jobs, allowing users to interact with big data using familiar, declarative syntax.
Hive is designed for batch processing and is optimized for querying, analyzing, and summarizing large, structured datasets. Its architecture supports schema-on-read, meaning data can be loaded from various sources—including CSV files, JSON, and ORC/Parquet formats—without needing upfront transformation.
Functioning both as a data warehouse system and a query engine, Apache Hive plays a critical role in enabling analysts, data engineers, and business users to run analytical queries over petabytes of data efficiently. It supports complex queries, joins, and aggregations, making it especially valuable in enterprise environments where fast, scalable data access is essential.
How Does Apache Hive Work?
Apache Hive simplifies big data processing by allowing users to write SQL-like queries, which Hive automatically translates into MapReduce jobs executed on a Hadoop cluster. This abstraction enables users to leverage Hadoop’s distributed computing power without needing to write low-level Java or MapReduce code.
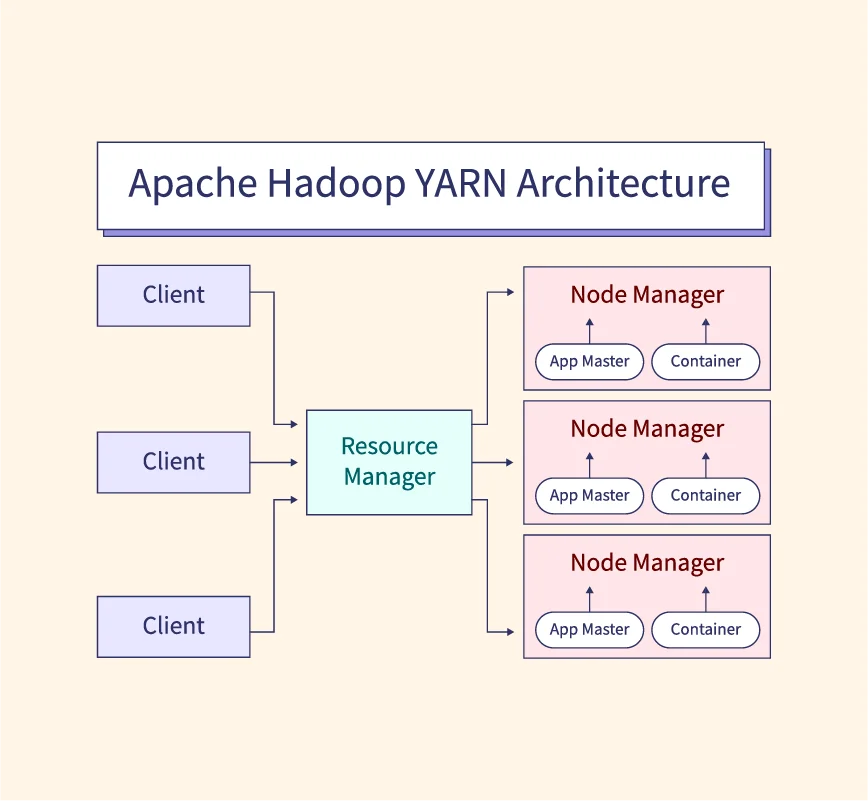
Hive’s architecture consists of several core components that work together to process queries:
- Metastore: This is the central repository that stores metadata about tables, partitions, and schemas. It enables Hive to manage and query data efficiently by keeping track of where and how data is stored in HDFS.
- Driver: The driver acts as the controller. It manages the lifecycle of a HiveQL statement, including parsing, compiling, optimizing, and executing queries. It coordinates query execution and maintains session information.
- Compiler: Hive’s compiler converts HiveQL queries into a directed acyclic graph (DAG) of stages. Each stage corresponds to a MapReduce job or another execution unit, depending on the query’s complexity.
- Execution Engine: This component handles the actual execution of jobs. It interacts with Hadoop’s resource manager (like YARN) to submit and monitor tasks on the cluster.
Together, these components enable Hive to bridge the gap between relational databases and Hadoop’s distributed storage, making big data processing more accessible through familiar SQL-like commands.
Key Components of Hive
- HiveQL is Hive’s native query language, modeled after SQL. It allows users to perform data queries, aggregations, joins, and transformations using familiar syntax. HiveQL supports subqueries, user-defined functions (UDFs), and data definition operations like CREATE, DROP, and ALTER, making it accessible for those with SQL backgrounds.
- The Metastore is a critical component that stores metadata about Hive tables, such as schema details, data types, and table locations in HDFS. It acts as the central catalog that enables Hive to manage and retrieve data efficiently.
- The Driver receives HiveQL queries and initiates their processing. The Compiler then parses the query, performs semantic analysis, and converts it into an execution plan—typically represented as a DAG of MapReduce stages or other execution units.
- Hive’s Execution Engine coordinates with Hadoop to run the compiled execution plan. It manages task execution, monitors progress, and ensures the final results are written back to HDFS or returned to the user.
Modes of Hive
Apache Hive operates in two primary modes depending on the environment and scale of data processing:
- Local Mode: In local mode, Hive runs on a single machine where the metadata, data, and execution engine are all hosted locally. This mode is ideal for development, testing, or processing small datasets, as it eliminates the need for a full Hadoop cluster setup.
- Distributed Mode: In distributed mode, Hive runs on a Hadoop cluster, utilizing HDFS for storage and YARN (or MapReduce) for resource management and execution. This mode is used in production environments to handle large-scale, distributed data processing efficiently.
Features and Characteristics of Hive
- Apache Hive offers a range of features that make it well-suited for big data environments. One of its defining traits is schema-on-read, which means data does not need to be transformed before loading. Instead, the schema is applied at the time of query execution, allowing flexibility with diverse data sources.
- Hive is extensible, supporting user-defined functions (UDFs) for custom logic and processing. This enables developers to tailor queries to their specific needs beyond built-in functions.
- Hive is fully compatible with HDFS and supports various file formats including Text, ORC, Parquet, Avro, and JSON, enhancing performance and interoperability. It can also integrate with compression codecs to reduce storage overhead.
- Designed for batch processing, Hive excels at querying and analyzing large datasets across distributed clusters. It’s optimized for complex queries, aggregations, and long-running jobs, making it a preferred tool in data warehousing and analytics workflows within Hadoop ecosystems.
Advantages
- Familiar Interface: Hive’s SQL-like query language (HiveQL) makes it accessible to users with traditional RDBMS experience.
- Scalability: Built on Hadoop, Hive can process petabytes of data across clusters, making it highly scalable.
- Cost-Effective: Works with commodity hardware and open-source tools, reducing infrastructure costs.
- Ideal for Reporting: Excellent for batch analytics, reporting, and summarization tasks.
Disadvantages
- Not Real-Time: Hive is not designed for real-time data processing or interactive queries.
- Latency: Queries translate into MapReduce jobs, which can introduce high latency compared to in-memory engines like Apache Spark.
Apache Hive vs Apache HBase
While both Hive and HBase operate within the Hadoop ecosystem, they serve very different purposes. Apache Hive is designed for batch processing and analytics, using HiveQL to query structured data stored in HDFS. It’s ideal for long-running queries and generating reports from large datasets.
Apache HBase, on the other hand, is a NoSQL database that supports real-time read/write access to big data. It is optimized for low-latency operations and random access to rows.
In summary, choose Hive for analytical workloads and HBase for transactional or real-time use cases requiring fast data retrieval.
Use Cases of Apache Hive
Apache Hive is widely used in log analysis, where large volumes of server or application logs are parsed, filtered, and aggregated to extract meaningful insights. It’s also a popular choice for building ETL (Extract, Transform, Load) pipelines, enabling structured transformation of raw data into analyzable formats.
In business intelligence, Hive supports the creation of dashboards and reports by querying massive datasets efficiently. Its ability to handle batch querying of structured data makes it ideal for organizations dealing with petabyte-scale information in industries such as finance, retail, telecom, and healthcare, where high-volume data analysis is crucial.
Read More:
References: