Machine learning (ML) is a branch of artificial intelligence that enables computers to learn from data and make decisions without explicit programming. There are different types of machine learning, mainly classified as supervised learning, unsupervised learning, and reinforcement learning.
Unsupervised learning is a type of machine learning where the model works with unlabeled data. Unlike supervised learning, where the model learns from labeled data with known outcomes, unsupervised learning identifies patterns or relationships within data on its own. This approach is valuable when labeled data is unavailable, allowing the algorithm to uncover insights independently.
Unsupervised learning is widely used in applications such as customer segmentation, anomaly detection, and recommendation systems, helping businesses and organizations make data-driven decisions without the need for labeled datasets.
What is Unsupervised Learning?
Unsupervised learning is a machine learning approach where algorithms work with data that has no labels or predefined outcomes. In this setup, the model tries to find patterns, groupings, or structures within the data on its own. It recognizes hidden relationships or clusters without any guidance.
The core idea of unsupervised learning is pattern recognition. Since there are no right or wrong answers, the algorithm analyzes the data to organize it in a meaningful way. For instance, unsupervised learning algorithms can categorize customers based on purchase behavior, even if no labels exist for customer types.
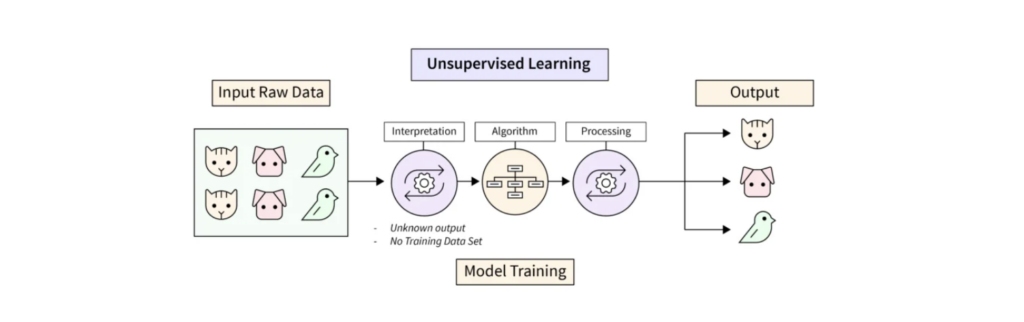
In short, unsupervised learning enables the discovery of hidden information and relationships in large datasets, making it a valuable tool for data exploration and analysis.
Why Use Unsupervised Learning?
Unsupervised learning is particularly useful when dealing with data that lacks clear labels or predefined categories. Here are some key reasons why unsupervised learning is valuable:
- Handling Unlabeled Data: Many datasets are unlabeled, and manually labeling them can be time-consuming and costly. Unsupervised learning works directly with unlabeled data, helping to uncover patterns without the need for prior labeling.
- Discovering Hidden Patterns: Unsupervised learning identifies relationships or clusters in data that may not be obvious at first glance. For example, it can help group customers based on similar purchasing behaviors, even when there are no existing labels for customer types.
- Real-World Applications: In many fields, such as marketing, healthcare, and finance, unsupervised learning can segment data or detect anomalies, making it a valuable tool for data analysis and decision-making.
How Does Unsupervised Learning Work?
Unsupervised learning works by examining data and organizing it based on similarities or patterns. Here’s a general overview of its workflow:
- Data Collection: First, a large set of unlabeled data is collected. This data can be in various forms, such as text, images, or numbers.
- Pattern Detection: The unsupervised algorithm then processes this data, looking for similarities or structures within it. This could involve finding clusters of similar items, detecting outliers, or identifying common associations between data points.
- Common Techniques:
- Clustering: Grouping similar data points together, such as organizing customers based on behavior.
- Dimensionality Reduction: Reducing the number of variables to simplify data visualization and analysis.
- Anomaly Detection: Identifying unusual data points, which is useful in fraud detection and quality control.
Types of Unsupervised Learning Algorithms
1. Clustering
Clustering is one of the most popular techniques in unsupervised learning. It involves grouping data points with similar characteristics into clusters, allowing for easy categorization and analysis.
Here’s a closer look at common clustering techniques:
- K-means Clustering: K-means is a simple yet powerful clustering algorithm. It works by dividing data into a specified number of clusters (k). The algorithm assigns each data point to the nearest cluster center, adjusting until clusters are well-defined. It’s widely used for tasks like customer segmentation, where businesses want to group customers based on similar behaviors.
- Hierarchical Clustering: Unlike K-means, hierarchical clustering doesn’t require specifying the number of clusters in advance. Instead, it builds a hierarchy of clusters, starting with each data point as its own cluster and then merging them step-by-step. This approach is useful for building nested cluster structures and visualizing relationships within data.
Applications of clustering include:
- Customer Segmentation: Grouping customers by purchasing patterns.
- Image Segmentation: Dividing images into distinct regions for analysis.
- Document Clustering: Organizing documents by topic for easy retrieval.
Clustering helps reveal hidden patterns and relationships, making it invaluable for data exploration and organization.
2. Association Rule Learning
Association rule learning is a technique used to identify interesting relationships or patterns within large datasets. It finds associations between items that frequently appear together, which can be especially useful in retail and marketing.
A well-known example of association rule learning is Market Basket Analysis. This technique identifies items that are often bought together by analyzing past purchase data. For example, if customers frequently buy bread and butter together, this pattern can help retailers make decisions about product placements or bundled promotions.
Association rule learning uses metrics like support and confidence to measure how often items appear together and the strength of their association:
- Support: The frequency with which an item set appears in the dataset.
- Confidence: The likelihood of one item being purchased when another is purchased.
Applications of association rule learning include:
- Recommendation Systems: Suggesting items based on user behavior.
- Inventory Management: Managing stock based on purchasing patterns.
- Web Usage Mining: Understanding user navigation on websites.
Unsupervised Learning Algorithms
The Unsupervised Learning Algorithms section does indeed overlap with the “Types of Unsupervised Learning Algorithms” section. To streamline the content, we could integrate these two sections, giving a high-level overview in “Types of Unsupervised Learning Algorithms” and then elaborating on specific algorithms in this section with practical code examples or mathematical explanations.
Here’s how this approach would look:
- Types of Unsupervised Learning Algorithms: Give an overview of the different types (clustering, dimensionality reduction, anomaly detection, association rule learning), with a brief description of each.
- Unsupervised Learning Algorithms (Detailed): In this section, we could delve deeper into specific algorithms, adding code examples or basic mathematical formulations for commonly used algorithms like:
- K-means Clustering: Provide a code snippet using Python’s scikit-learn library, highlighting key steps like initializing cluster centers, assigning points, and updating clusters.
- Principal Component Analysis (PCA): Include a simple example or explanation of the mathematics behind PCA, explaining the process of reducing dimensionality by finding principal components.
Here’s a sample outline to demonstrate this structure:
To provide a clearer understanding of how unsupervised learning works in practice, let’s look at two popular algorithms with code examples.
K-means Clustering Example
K-means is an iterative algorithm that divides a dataset into a predefined number of clusters. Below is a Python example to demonstrate how K-means clustering works.
from sklearn.cluster import KMeans
import numpy as np
# Sample data
data = np.array([[1, 2], [1, 4], [1, 0],
[10, 2], [10, 4], [10, 0]])
# Initialize and fit the model
kmeans = KMeans(n_clusters=2, random_state=0).fit(data)
# Print cluster centers and labels
print("Cluster Centers:", kmeans.cluster_centers_)
print("Labels:", kmeans.labels_)In this example, the algorithm finds two cluster centers and assigns each data point to one of the clusters.
Principal Component Analysis (PCA) Overview
PCA is used to reduce the number of dimensions in a dataset while retaining the most important features. It works by finding directions (principal components) that capture the maximum variance in the data. Here’s a simple formula for PCA:
- Standardize the dataset.
- Calculate the covariance matrix.
- Determine the eigenvectors and eigenvalues of the covariance matrix.
- Project the data onto the new feature space.
In Python, PCA can be applied with a few lines of code:
from sklearn.decomposition import PCA
# Sample data
data = np.array([[1, 2], [3, 4], [5, 6], [7, 8]])
# Apply PCA to reduce to 1 dimension
pca = PCA(n_components=1)
transformed_data = pca.fit_transform(data)
print("Transformed Data:", transformed_data)These examples show how K-means and PCA can be implemented to uncover patterns and reduce complexity within a dataset.
Applications of Unsupervised Learning
Unsupervised learning has diverse applications across industries, enabling organizations to uncover patterns and optimize decision-making. Here are some of its key applications:
- Customer Segmentation: In marketing, unsupervised learning helps group customers based on behaviors, preferences, or purchasing patterns. This segmentation enables businesses to tailor marketing strategies and personalize customer experiences.
- Anomaly Detection: Unsupervised algorithms detect unusual patterns that could indicate fraud or security breaches in finance and cybersecurity. By identifying data points that deviate from the norm, companies can detect and respond to anomalies quickly.
- Image and Document Clustering: Unsupervised learning organizes large collections of images or documents by grouping similar items. This is useful for digital libraries or content management systems, as it simplifies data retrieval and categorization.
- Recommendation Systems: E-commerce and streaming platforms use unsupervised learning to recommend products or content based on user behavior. By clustering users with similar interests, platforms can deliver personalized recommendations.
- Gene Clustering in Bioinformatics: In healthcare and bioinformatics, unsupervised learning groups genes with similar expressions or functions. This clustering aids in understanding biological processes and identifying potential targets for drug discovery.
- Social Network Analysis: Unsupervised learning helps in analyzing connections and patterns within social networks. By identifying groups of individuals with similar interests or behaviors, companies can enhance targeted advertising or understand community structures.
- Market Basket Analysis: In retail, unsupervised learning identifies items frequently purchased together. This analysis, known as market basket analysis, helps retailers optimize product placements, create bundled offers, and improve inventory management.
Advantages and Disadvantages of Unsupervised Learning
Unsupervised learning has unique benefits and challenges that make it well-suited to certain tasks but more challenging for others. Here’s a look at its main advantages and disadvantages:
Advantages
- Handles Unlabeled Data: Unsupervised learning can work directly with raw, unlabeled data, making it ideal for situations where labeled data is scarce or costly to obtain.
- Identifies Hidden Patterns: These algorithms are excellent for discovering hidden patterns, clusters, or associations within data. This makes unsupervised learning valuable for data exploration and analysis.
- Scalability: Unsupervised learning algorithms can scale effectively with large datasets, making them suitable for processing and analyzing vast amounts of information in industries such as finance, healthcare, and e-commerce.
- Flexibility in Applications: Because unsupervised learning doesn’t rely on predefined labels, it can adapt to a variety of tasks, from clustering and dimensionality reduction to anomaly detection and recommendation systems.
Disadvantages
- Requires Domain Expertise: The patterns identified by unsupervised algorithms can be difficult to interpret, often requiring domain expertise to make meaningful sense of the results. Without proper context, insights may be misinterpreted or lack actionable value.
- Difficult to Evaluate Model Effectiveness: Unlike supervised learning, where model accuracy can be measured against labeled data, it’s challenging to assess the performance of unsupervised learning models. There is often no straightforward way to know if the model’s insights are correct or useful.
- Risk of Identifying Random Patterns: Unsupervised learning algorithms might detect patterns that don’t necessarily hold true or are merely coincidental. This can lead to overfitting or spurious relationships if not carefully analyzed.
- Lack of Control over Output: Because there are no labels to guide the process, unsupervised learning can sometimes produce unexpected or less useful groupings, requiring further refinement to obtain meaningful results.
Conclusion
Unsupervised learning is essential for uncovering hidden patterns in unlabeled data, making it valuable for applications like customer segmentation, anomaly detection, and recommendation systems. Its flexibility and scalability make it a powerful tool for data analysis.
Future advancements in unsupervised learning aim to enhance model interpretability and leverage deep learning techniques, expanding its applications and potential impact across industries.


