Support Vector Machine (SVM) is a widely-used supervised learning algorithm for classification and regression tasks in machine learning. Known for its robustness and ability to handle both linear and non-linear data, SVM has applications in fields ranging from healthcare to finance. Whether it’s classifying images or detecting fraud, SVM offers a powerful solution by finding the optimal hyperplane to separate data into distinct classes. This guide will explore the fundamentals of SVM, including how it works, its types, kernel functions, and real-world applications, with a hands-on Python implementation.
What is a Support Vector Machine (SVM)?
A Support Vector Machine (SVM) is a supervised machine learning algorithm primarily used for classification tasks, although it can also be applied to regression problems. The core idea behind SVM is to find a hyperplane in an N-dimensional space (N representing the number of features) that best separates the data points into different classes. SVM is versatile enough to handle both binary and multi-class classification problems.
In classification tasks, SVM seeks to identify the optimal hyperplane that maximizes the margin between different classes. This margin represents the distance between the hyperplane and the closest data points from each class, known as support vectors. The goal is to maximize the margin to ensure better generalization of the model.
A real-world application of SVM can be found in email spam detection, where the algorithm classifies emails into “spam” or “not spam” based on various features extracted from the email content.
How Does the Support Vector Machine Algorithm Work?
The SVM algorithm works by finding the best hyperplane that divides the data points into distinct classes. The step-by-step process can be broken down as follows:
- Identify the Hyperplane
The first step is to identify a hyperplane that separates the classes. In two-dimensional space, this hyperplane is a straight line, but in higher-dimensional spaces, it can be a plane or a hyperplane. The goal is to select the hyperplane that maximizes the distance between the classes, ensuring that future data points are classified correctly. - Margins and Support Vectors
The margin refers to the distance between the hyperplane and the nearest data points from each class, which are called support vectors. Support vectors are critical data points that influence the position and orientation of the hyperplane. SVM seeks to maximize this margin, making the classification more robust. - Maximizing the Margin
The optimal hyperplane is the one that maximizes the margin between the support vectors. A larger margin results in better generalization of the model, as it reduces the likelihood of misclassification when new data points are introduced. - Decision Boundary
The decision boundary is defined by the hyperplane, and it is used to classify new data points. Any point that falls on one side of the hyperplane is assigned to one class, while points on the other side are assigned to the other class. For multi-class problems, SVM uses strategies like one-vs-one or one-vs-all to handle more than two classes.
Visual Representation
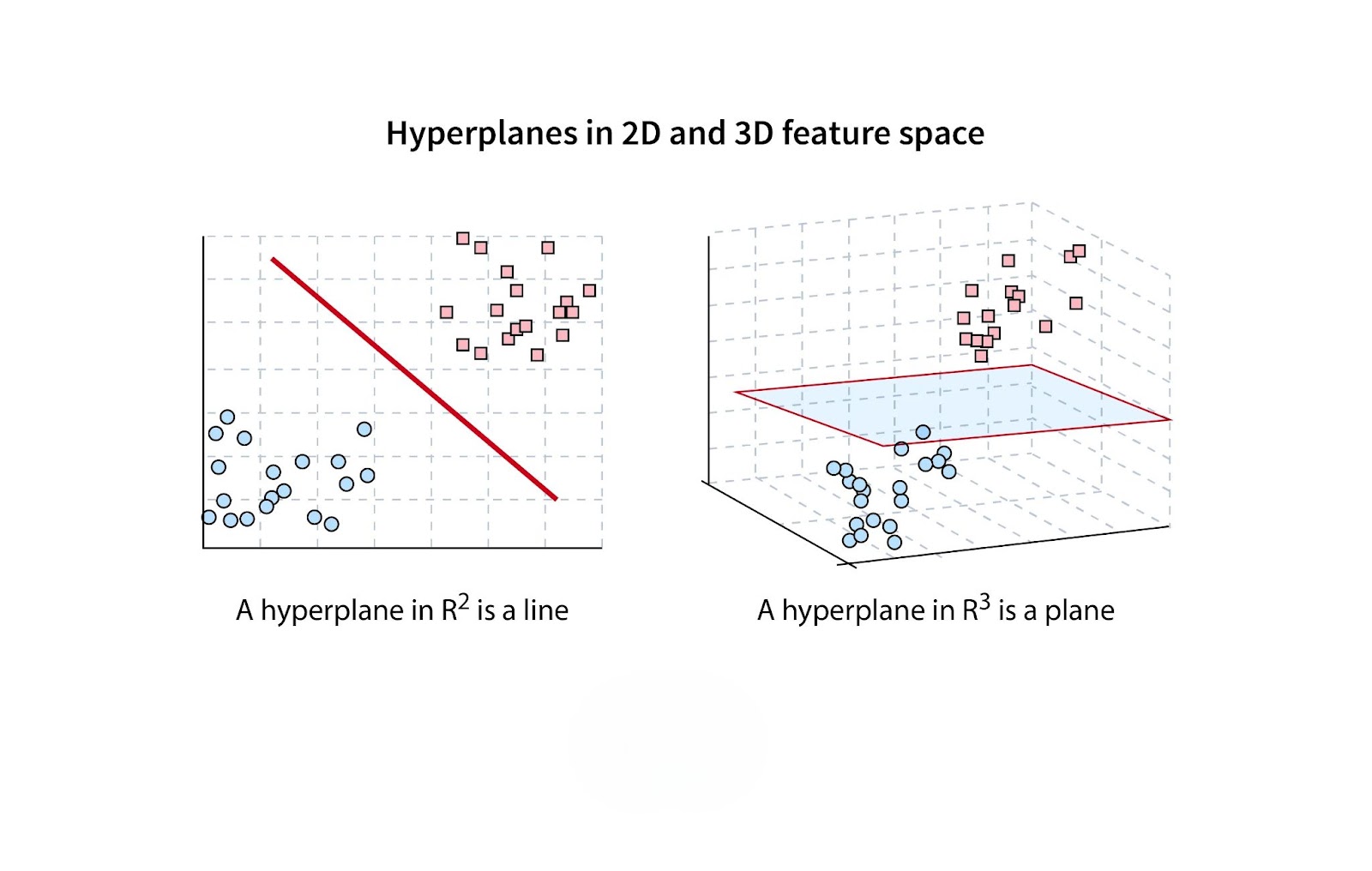
In a visual representation, the hyperplane is a line that divides the data points into two classes, with the support vectors positioned close to the hyperplane. The distance between the support vectors and the hyperplane represents the margin, which SVM seeks to maximize.
Support Vectors in Classification
Support vectors are the key data points that determine the positioning of the hyperplane. Removing or altering these points can change the hyperplane, making them crucial for the classification task.
Types of Support Vector Machines
1. Linear SVM
Linear SVM is used when the data is linearly separable, meaning that a straight line (or hyperplane) can effectively separate the classes. The advantage of linear SVM is that it is computationally efficient and works well with high-dimensional datasets where the data points are easily separable by a straight line.
However, linear SVMs are limited by their inability to handle non-linearly separable data, where the classes cannot be separated by a straight line. This is where non-linear SVMs come into play.
2. Non-linear SVM
Non-linear SVM is used when the data cannot be separated by a straight line. To handle this, SVM applies a technique known as the kernel trick, which transforms the data into a higher-dimensional space where it becomes linearly separable. The kernel function plays a crucial role in transforming non-linear data into a linear form.
Kernel Functions in Non-linear SVM
The kernel function transforms the data into a higher-dimensional space where a hyperplane can effectively separate the classes. Popular kernel functions include the Radial Basis Function (RBF), Polynomial kernel, and Sigmoid kernel, each with its specific applications depending on the nature of the data.
Real-life Use Cases
- Linear SVM: Commonly used in text classification, such as classifying documents as spam or non-spam.
- Non-linear SVM: Used in image classification tasks where data is often non-linearly separable.
Mathematical Computation of SVM
Optimization Problem in SVM
The primary objective in SVM is to maximize the margin between the support vectors while minimizing classification errors. This optimization problem can be formulated as a quadratic programming problem, where the goal is to find the optimal hyperplane that separates the classes with the maximum margin.
The equation of the hyperplane can be written as:
$w \cdot x + b = 0$
Where:
- w represents the weight vector.
- x is the input feature vector.
- b is the bias term.
The margin is calculated as the distance between the support vectors and the hyperplane, and the goal is to maximize this margin while ensuring that no data points fall within the margin area.
Lagrange Multipliers
In the SVM optimization problem, Lagrange multipliers are used to handle the constraints of the optimization. They are applied to ensure that the optimization problem satisfies both the margin maximization and the minimization of classification errors.
Kernel Functions and Their Mathematical Representation
Kernel functions play a crucial role in SVM, particularly in non-linear classification tasks. By applying a kernel function, the algorithm can transform data into a higher-dimensional space where it becomes easier to separate the classes. The most common kernel functions include:
Linear Kernel:
$K(x, y) = x \cdot y$
Polynomial Kernel:
$K(x, y) = (x \cdot y + c)^d$
RBF Kernel:
$K(x, y) = \exp(-\gamma ||x – y||^2)$
These kernel functions allow SVM to handle complex classification tasks with non-linearly separable data.
C Parameter and Regularization
The C parameter controls the trade-off between maximizing the margin and minimizing misclassification errors. A high value of C places more emphasis on classifying all data points correctly, while a lower value of C allows for a softer margin, which may tolerate some misclassifications to achieve better generalization.
Popular Kernel Functions in SVM
Linear Kernel
The linear kernel is the simplest and most efficient kernel for linearly separable data. It is commonly used in high-dimensional spaces, such as in text classification tasks where the number of features is large.
Polynomial Kernel
The polynomial kernel is useful for datasets where the relationship between the features is non-linear. It maps the data into a higher dimension and can handle more complex relationships between features.
Radial Basis Function (RBF) Kernel
The RBF kernel is the most commonly used kernel for non-linear classification tasks. It works by mapping the data into an infinite-dimensional space, making it ideal for complex datasets where the data cannot be separated by a linear hyperplane.
Sigmoid Kernel
The sigmoid kernel is similar to the activation function used in neural networks, making it suitable for certain types of classification tasks. However, it is less commonly used compared to the other kernels.
Each kernel function has its own strengths and is suited to specific types of data and problems. Choosing the right kernel is critical for achieving optimal performance with SVM.
Implementing the SVM Algorithm in Python
Steps to Implement SVM
Implementing SVM in Python is straightforward, thanks to libraries like scikit-learn. The basic steps for implementing SVM include:
1. Installing Required Libraries
Install scikit-learn and other necessary libraries using pip:
$$pipinstallscikit−learnpip install scikit-learnpipinstallscikit−learn$$
2. Loading the Dataset
Load a dataset, such as the iris dataset:
from sklearn import datasets
iris = datasets.load_iris()3. Splitting the Dataset
Split the dataset into training and testing sets:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.3)4. Fitting the SVM Model
Fit the SVM model to the training data:
from sklearn.svm import SVC
model = SVC(kernel='linear')
model.fit(X_train, y_train)5. Making Predictions and Evaluating Accuracy
Make predictions and evaluate the accuracy of the model:
predictions = model.predict(X_test)
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y_test, predictions)
print("Accuracy:", accuracy)Hyperparameter Tuning
Hyperparameters such as the C parameter and kernel choice can be tuned using GridSearchCV to optimize the model’s performance:
from sklearn.model_selection import GridSearchCV
param_grid = {'C': [0.1, 1, 10], 'kernel': ['linear', 'rbf']}
grid = GridSearchCV(SVC(), param_grid, refit=True)
grid.fit(X_train, y_train)Advantages of SVM
SVM offers several advantages, including:
- High effectiveness in high-dimensional spaces: SVM performs well in situations where the number of features exceeds the number of samples.
- Memory efficiency: SVM only uses a subset of the training data (support vectors), making it memory-efficient.
- Clear margin separation: SVM works well when there is a clear margin of separation between classes.
- Effectiveness with non-linear data: The kernel trick allows SVM to handle non-linearly separable data efficiently.
Disadvantages of SVM
Despite its advantages, SVM also has some drawbacks:
- Complex model interpretation: In non-linear cases, interpreting the model becomes difficult.
- Training time: SVM can take longer to train on large datasets compared to other algorithms like decision trees.
- Sensitivity to kernel choice: The performance of SVM is highly dependent on the choice of kernel and regularization parameters.
- Performance with overlapping classes: SVM may perform poorly when classes overlap significantly.
Important Support Vector Machine Vocabulary
Hyperplane
The hyperplane is the decision boundary that separates the classes in SVM. In higher-dimensional spaces, it can be represented as a plane or hyperplane.
Margin
The margin is the distance between the support vectors and the hyperplane. SVM aims to maximize this margin to ensure better generalization of the model.
Support Vectors
Support vectors are the critical data points that influence the position of the hyperplane. These are the data points closest to the hyperplane.
Kernel Trick
The kernel trick allows SVM to transform non-linearly separable data into a higher-dimensional space where it can be linearly separated.
Regularization
Regularization in SVM controls the trade-off between maximizing the margin and minimizing misclassification errors. The C parameter plays a key role in this trade-off.
One-vs-All and One-vs-One
These are strategies used by SVM to handle multi-class classification problems. One-vs-all creates one classifier for each class, while one-vs-one creates a classifier for every pair of classes.
C Parameter
The C parameter controls the trade-off between achieving a larger margin and minimizing misclassification errors. A smaller C results in a wider margin, but allows for some misclassification, while a larger C narrows the margin but reduces errors.
Grid Search
Grid search is a hyperparameter tuning technique that tests various combinations of hyperparameters (such as C and kernel) to find the best combination for optimizing the model’s performance.
Conclusion
Support Vector Machines (SVMs) are a versatile and powerful tool in machine learning, particularly for classification tasks. They work well in high-dimensional spaces, efficiently handle non-linear data through the kernel trick, and are widely used in industries ranging from finance to healthcare. However, like all algorithms, SVM has its limitations, particularly in terms of model complexity and training time for large datasets. Despite these challenges, SVM remains a popular and effective choice for many machine learning applications.
References:


