What is Supervised Learning?
Supervised learning is a type of machine learning where a model is trained using labeled data. In labeled data, each input is paired with a known output, allowing the model to learn patterns and relationships between them. This structured approach enables the model to make accurate predictions for new, unseen data.
Think of supervised learning as similar to a teacher guiding a student. The labeled data acts like a teacher, providing correct answers so the model (the student) can learn over time. Through repeated exposure to this labeled data, the model gradually becomes better at predicting the correct outcome on its own.
The main goal of supervised learning is to generalize from the labeled data so that it can make reliable predictions or decisions for unknown data in the future.
How Does Supervised Learning Work?
The process of supervised learning involves several key steps to train a model effectively:
- Data Preparation – The first step is preparing the data by cleaning and pre-processing it. This includes removing any irrelevant information, handling missing values, and organizing the data into labeled pairs, where each input has a corresponding output.
- Training the Model – The model is then trained using this labeled data. During training, the model analyzes the patterns in the input data and learns to map these inputs to their correct outputs. This involves adjusting the model’s parameters to improve accuracy.
- Model Evaluation – Once trained, the model is tested on unseen data (data it hasn’t encountered before) to evaluate its performance. This helps determine how well the model can generalize beyond the training data.
- Making Predictions – Finally, after the model has been trained and tested, it can be used to make predictions on new data. The better it learned during training, the more accurate its predictions will be.
Supervised Learning Algorithms
Supervised learning includes a variety of algorithms, each suited for different types of tasks. Here are some common supervised learning algorithms with a brief description:
- Neural Networks – Inspired by the human brain, neural networks are complex models that learn patterns in data, making them suitable for tasks like image and speech recognition.
- Naive Bayes – This algorithm is based on probability and is used for classification tasks. It assumes that all features are independent, making it fast and effective for tasks like spam detection.
- Linear Regression – A simple algorithm that predicts continuous values by finding a linear relationship between input features and the target variable. It’s commonly used in predicting prices, like housing costs.
- Logistic Regression – Despite its name, logistic regression is used for classification, not regression. It predicts binary outcomes (e.g., yes/no) and is widely used for problems like email spam detection.
- Support Vector Machines (SVM) – SVMs create a hyperplane that separates data into different classes. They are effective in tasks where the data is clearly separated, such as image classification.
- K-Nearest Neighbors (KNN) – KNN classifies data based on the majority label among its nearest neighbors, making it a simple but effective choice for tasks like recommendation systems.
- Random Forest – This algorithm combines multiple decision trees to improve accuracy and robustness. It’s effective for both classification and regression tasks and is commonly used in finance and healthcare.
Types of Supervised Learning
Supervised learning generally falls into two main types, each designed to handle different kinds of problems:
- Classification – In classification, the model predicts discrete categories or classes. For example, an email can be classified as “spam” or “not spam,” or an image can be categorized as “cat” or “dog.” Classification is useful for tasks where outcomes fall into specific groups or labels.
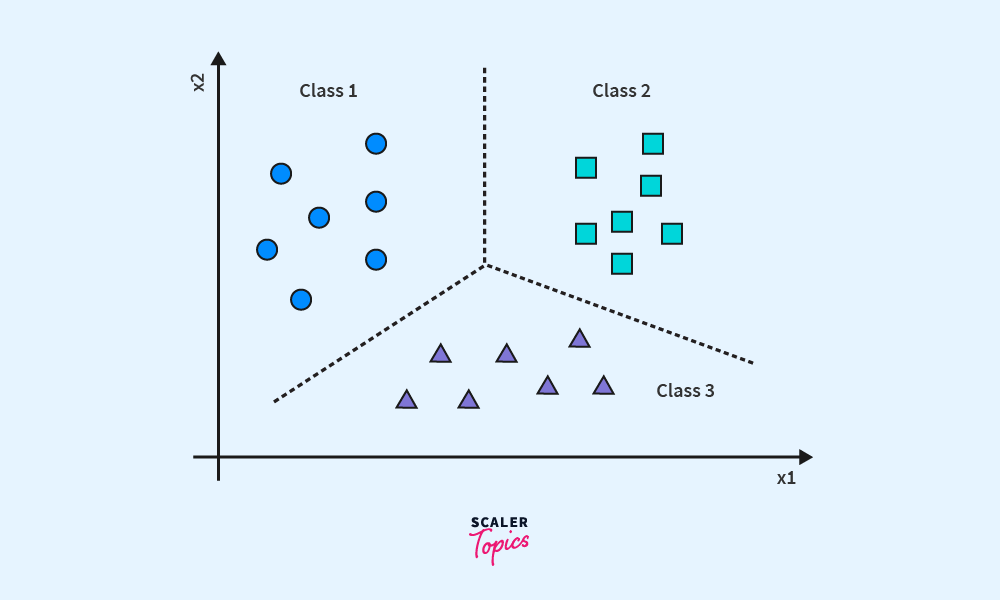
- Regression – In regression, the model predicts continuous values. For instance, it might predict the price of a house based on features like location, size, and age. Regression is used when the output is a range of values, rather than distinct categories.
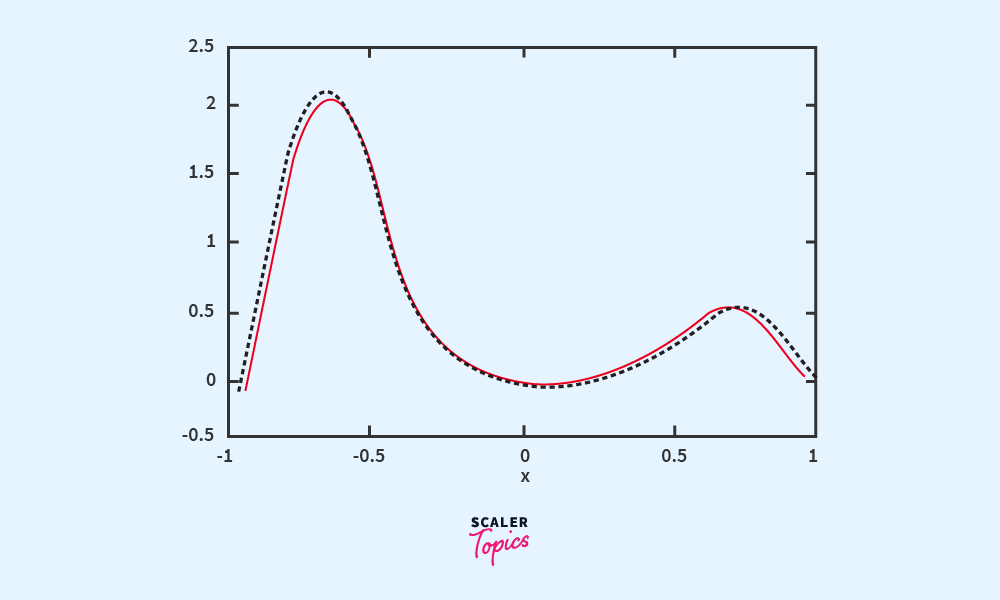
These two types help tackle a wide range of problems, from predicting sales figures to identifying objects in images, making supervised learning highly versatile across different fields.
Real-World Supervised Learning Examples
Supervised learning is widely applied across various fields to solve complex problems. Here are some real-world examples:
- Spam Filtering – Email services like Gmail use supervised learning to classify incoming emails as “spam” or “not spam” based on patterns in labeled email data.
- Image Recognition – In healthcare, supervised learning is used to analyze medical images, helping detect diseases like tumors in X-rays or MRIs. It’s also used in applications like facial recognition on smartphones.
- Stock Price Prediction – Financial institutions apply supervised learning to forecast stock prices using historical and current data, supporting better investment decisions.
- Customer Churn Prediction – Businesses predict which customers are likely to leave their services. By identifying at-risk customers, companies can offer personalized incentives to retain them.
- Recommender Systems – Platforms like Netflix, Amazon, and Spotify use supervised learning to recommend content based on users’ past behaviors, improving the user experience and engagement.
- Fraud Detection – Banks and credit card companies use supervised learning to detect fraudulent transactions. By analyzing patterns in labeled data, these systems can flag suspicious activities in real time.
- Sentiment Analysis – Businesses monitor social media and customer reviews using supervised learning to gauge public sentiment toward their products or services, helping them adjust marketing strategies.
- Document Classification – Companies use supervised learning to categorize documents, such as sorting legal documents, news articles, or customer feedback, making information easier to manage and access.
- Disease Prediction – In healthcare, supervised learning helps predict the likelihood of diseases based on patient data, enabling early interventions and personalized treatments.
- Credit Scoring – Banks assess loan applicants by using supervised learning to predict creditworthiness, based on historical data like income, credit history, and debt.
Unsupervised vs Supervised vs Semi-Supervised Learning
Machine learning includes several approaches, and each one serves different types of tasks. Here’s a quick comparison:
| Type | Description | Data Type | Example Use Cases |
| Supervised Learning | The model is trained using labeled data, where each input has a known output. | Labeled Data | Spam detection, stock price prediction |
| Unsupervised Learning | The model identifies patterns and relationships in data without labeled outcomes. | Unlabeled Data | Customer segmentation, anomaly detection |
| Semi-Supervised Learning | The model is trained with a mix of labeled and a large amount of unlabeled data. | Partially Labeled Data | Image classification with limited labeled images |
- Supervised Learning focuses on predicting specific outcomes using labeled data. It’s highly accurate but requires large amounts of labeled data, which can be costly and time-consuming to obtain.
- Unsupervised Learning discovers hidden patterns in data without labeled outcomes. It’s useful for tasks where labeled data isn’t available but is generally less precise for prediction tasks.
- Semi-Supervised Learning strikes a balance between the two, using a smaller labeled dataset alongside a larger unlabeled dataset. This method is often applied when labeling data is difficult or expensive, like in image recognition.
Challenges of Supervised Learning
While supervised learning is powerful, it faces several challenges that can impact model performance and usability:
- Data Quality and Availability – Supervised learning requires large amounts of labeled data, which can be expensive and time-consuming to obtain. Additionally, if the data is incomplete or has errors, it can lead to poor model performance.
- Overfitting – Overfitting occurs when a model learns the training data too well, including noise and specific details, resulting in poor performance on new data. Overfitted models are not generalizable and struggle to make accurate predictions on unseen data.
- Model Selection – Choosing the right algorithm for a specific task can be challenging. Each algorithm has strengths and weaknesses, and selecting the wrong one can lead to suboptimal results.
- Bias in Data – If the training data is biased, the model’s predictions will reflect that bias, potentially leading to unfair or inaccurate results. Addressing data bias is essential, especially in sensitive areas like hiring or lending.
- Computational Resources – Some supervised learning algorithms, particularly complex ones like neural networks, require significant computational power, which can be a limitation for smaller organizations.
Conclusion
Supervised learning is a core machine learning technique that uses labeled data to make accurate predictions, enabling applications like spam detection, fraud prevention, and medical diagnosis. Despite challenges like data quality and overfitting, supervised learning remains essential for data-driven decision-making and automation across various fields. As machine learning advances, supervised learning’s role in driving insights and innovation will continue to grow.


