Ensemble learning is a popular approach in machine learning where multiple models are combined to improve the accuracy and robustness of predictions. Often, individual models may have limitations, such as overfitting or underfitting. By combining several models, ensemble methods can reduce these issues and produce better results.
Stacking (stacked generalization) is an ensemble technique that uses several base models and combines their outputs through a meta-model to enhance overall performance. It integrates predictions from diverse models, making it effective when a single model doesn’t perform well. Stacking is applied in areas like customer behavior prediction and image classification for improved results.
What is Stacking?
Stacking, or stacked generalization, is an ensemble learning technique that combines the predictions of multiple models (base models) to create a more accurate final prediction. The idea is to utilize the strengths of different models by blending their outputs using another model called the meta-model.
Stacking differs from other ensemble methods like bagging and boosting:
- Bagging (Bootstrap Aggregating) involves training multiple versions of the same model on different subsets of the data and averaging their predictions to reduce variance and prevent overfitting.
- Boosting trains models sequentially, where each new model focuses on correcting the mistakes of the previous ones, improving the overall accuracy but increasing the risk of overfitting.
Unlike bagging and boosting, stacking combines different types of models rather than the same type. The meta-model in stacking learns the best way to integrate their outputs, leading to a more balanced and accurate result.
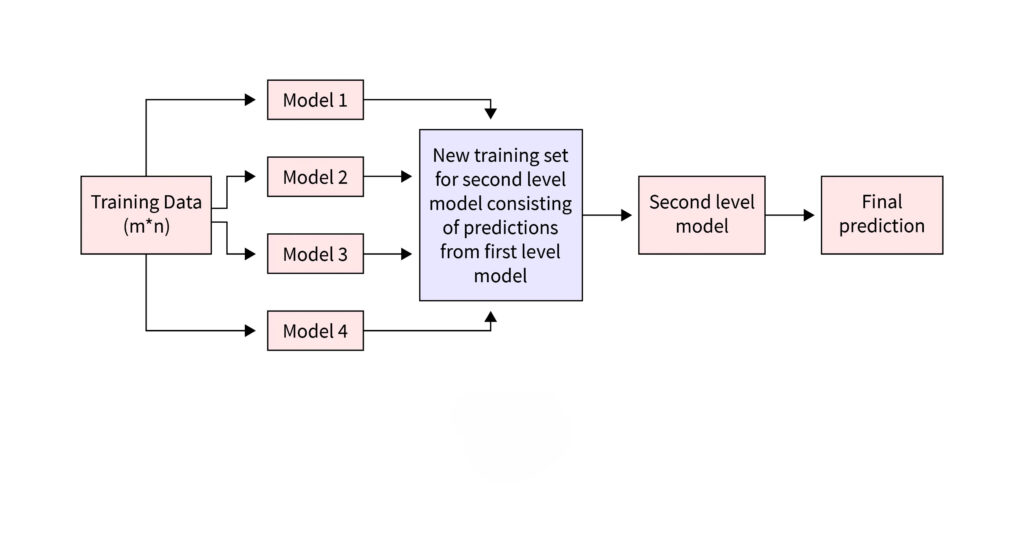
How Stacking Works?
Stacking involves combining the outputs of different models to enhance predictive performance. Here’s how the process typically works:
- Data Preparation: The dataset is divided into training and testing sets. The training data is used to build the models, while the testing data evaluates the performance.
- Training the Base Models: Multiple base models (e.g., decision trees, logistic regression) are trained independently using the training set. These models are diverse, ensuring varied perspectives on the data.
- Generating Base Model Predictions: The trained base models make predictions on the same training data. These predictions form a new set of features, representing each model’s view of the data.
- Training the Meta-Model: A meta-model is trained using these new features (base model predictions) and the original features. The meta-model, often a simpler algorithm like linear regression, learns to find patterns in the base models’ outputs.
- Final Prediction: For the test set, base models generate predictions, which are then used by the meta-model to produce the final output. This way, the meta-model combines the strengths of all base models.
This multi-layered structure allows stacking to achieve better performance by leveraging different models’ strengths.
Architecture of Stacking
Stacking consists of two main levels in its architecture:
1. Primary Level (Base Models):
- At this level, multiple base models are trained using the training dataset. These models can vary in type, such as decision trees, support vector machines, or logistic regression. The goal is to create diverse models that offer different perspectives on the data.
- The base models generate predictions on the training data, which are then used as inputs for the next level.
2. Secondary Level (Meta-Model):
- The meta-model, also called the secondary model, is trained using the predictions from the base models and the original dataset features. This model aims to learn how to best combine the outputs of the base models for improved accuracy.
- Common meta-model algorithms include logistic regression, random forest, or even neural networks, depending on the complexity and nature of the data.
3. Final Prediction:
- The meta-model makes the final prediction by leveraging the combined insights from the base models and the original features. This output is expected to be more accurate than any of the base models alone, as it integrates their strengths.
This architecture allows stacking to achieve higher predictive performance by combining diverse models and optimizing their collective output.
What is Blending and How Does it Work?
Blending is another ensemble learning technique, similar to stacking, but with a simpler approach. It combines predictions from multiple models, often averaging them, to achieve better performance. Here’s how blending differs from stacking and how it works:
1. Blending vs. Stacking:
- While stacking uses predictions from base models as input for a meta-model, blending generally averages the predictions from base models directly without the need for a meta-model.
- Blending typically splits the training data into two parts. The first part is used to train the base models, and the second part is used to generate predictions, which are averaged to produce the final output.
2. How Blending Works:
- The training dataset is divided into two subsets: one for training the base models and another (a holdout set) for making predictions.
- Base models are trained using the first subset, and their predictions are collected on the holdout set.
- These predictions are then averaged or combined using a simple model to produce the final prediction. This straightforward approach reduces the risk of overfitting that sometimes occurs in stacking.
3. Advantages and Disadvantages of Blending:
- Advantages: Blending is simpler to implement and requires less computation since it avoids training an additional meta-model.
- Disadvantages: It may not achieve the same level of performance improvement as stacking because it doesn’t learn how to best combine the predictions from the base models.
Blending is often used as a quick way to boost model performance without the complexity of stacking, but stacking usually yields more refined and accurate results when properly implemented.
Conclusion
Stacking is a powerful ensemble technique in machine learning that enhances model performance by combining predictions from multiple models through a meta-model. By leveraging the strengths of diverse models, stacking produces a more accurate and reliable final output than any single model alone.
While stacking offers significant benefits, such as improved accuracy and robustness, it also has some drawbacks, including increased complexity and the need for more computational resources. In contrast, blending provides a simpler alternative but may not achieve the same level of improvement.
In practice, stacking is widely applied in areas like customer behavior prediction, image classification, and financial forecasting, demonstrating its versatility across different domains.


