Speech recognition plays a crucial role in artificial intelligence (AI), allowing machines to understand and respond to human speech. It bridges the communication gap between humans and machines, making interactions seamless and efficient. With advancements in AI, speech recognition has become essential in technologies like virtual assistants, chatbots, and smart devices.
The ability to convert spoken words into text or commands empowers industries ranging from healthcare to automotive. As voice interfaces become more popular, speech recognition continues to shape how we interact with technology, enhancing accessibility, efficiency, and user experience across various applications.
What is Speech Recognition?
Speech recognition is the technology that enables machines to interpret spoken language and convert it into text or actionable commands. This process involves analyzing sound waves from speech, recognizing phonetic patterns, and mapping them to words and phrases. It uses complex algorithms to identify the spoken input and match it with pre-defined data sets for accurate recognition.
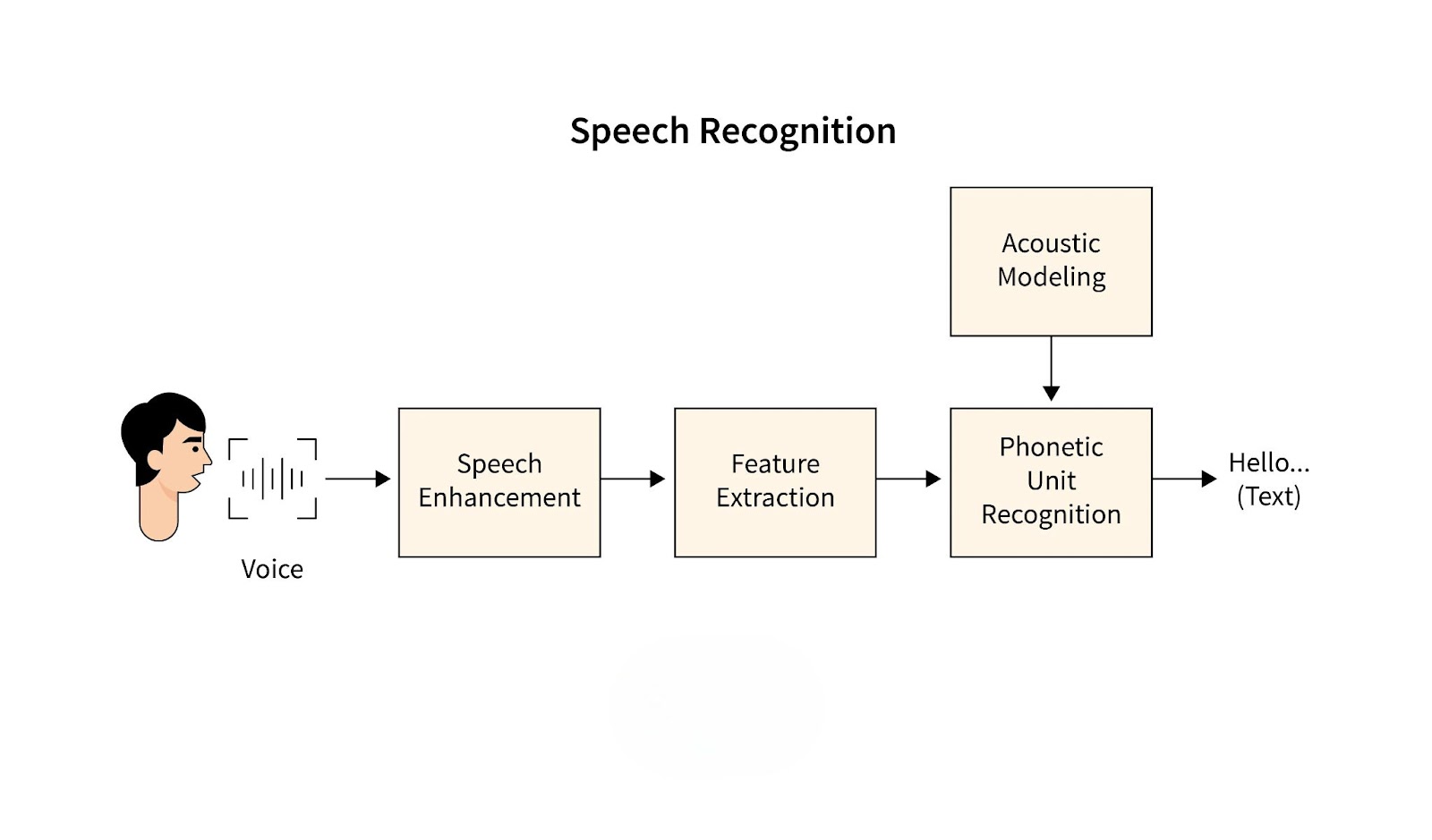
The evolution of speech recognition dates back to the 1950s with early experiments in phoneme-based systems. Over time, advancements in computational power and machine learning have transformed it into a powerful technology. Milestones include the introduction of Hidden Markov Models (HMM) in the 1980s and deep learning algorithms in recent years.
Modern speech recognition systems can now process continuous speech with high accuracy, overcoming limitations that plagued earlier models. These systems are integrated into various devices, providing smooth, hands-free interaction in areas such as virtual assistants, smartphones, and voice-enabled applications.
Key Features of Effective Speech Recognition
Accuracy
Accuracy refers to how well a speech recognition system can transcribe spoken language correctly. High precision ensures fewer errors in recognizing words, even with variations in pronunciation. Accurate recognition is essential for applications like virtual assistants and customer service bots, where incorrect responses can affect user experience.
Speed
Speed determines how quickly a system can process and convert speech into text or commands. Real-time recognition is critical for seamless interaction, especially in conversational AI tools like chatbots and voice assistants. Faster response times also improve user engagement and satisfaction in time-sensitive environments.
Adaptability
A robust speech recognition system must be adaptable, capable of handling multiple languages, accents, and tonal variations. This adaptability ensures inclusivity and usability across diverse user bases. Systems designed to recognize different dialects and languages can cater to a global audience, enhancing accessibility.
Integration with Other AI Technologies
Effective speech recognition systems often integrate with Natural Language Processing (NLP) technologies to understand context and intent. This integration enhances the system’s ability to respond intelligently, creating a more human-like interaction. For example, virtual assistants rely on both speech recognition and NLP to provide accurate responses to user queries.
Speech Recognition Algorithms
Speech recognition relies on several algorithms to convert speech into text efficiently. Below are the most commonly used algorithms:
Hidden Markov Models (HMM)
HMM is one of the earliest and most widely used algorithms in speech recognition. It models speech as a series of probabilistic events, capturing variations in phonemes and word sequences. HMM-based systems are effective in recognizing continuous speech patterns but have limitations in handling ambiguity and noise.
Natural Language Processing (NLP)
NLP enhances speech recognition by enabling systems to understand the meaning and context behind spoken words. It helps disambiguate homophones—words that sound the same but have different meanings—by analyzing the sentence structure and context. NLP also supports language translation in speech-based applications.
Deep Neural Networks (DNN)
DNNs use layers of interconnected nodes to process audio signals and identify patterns in speech. They are particularly effective at learning complex features from large datasets, improving recognition accuracy. DNN-based systems are commonly employed in applications like voice assistants and transcription software.
End-to-End Deep Learning
End-to-end deep learning eliminates the need for traditional pre-processing stages by processing raw audio inputs directly. These models use deep neural architectures to convert speech into text in a single step, making the process faster and more efficient. This approach is becoming popular due to its simplicity and improved accuracy.
Together, these algorithms power modern speech recognition systems, enabling them to understand and respond to spoken language effectively across a wide range of applications.
Speech Recognition and Natural Language Processing (NLP)
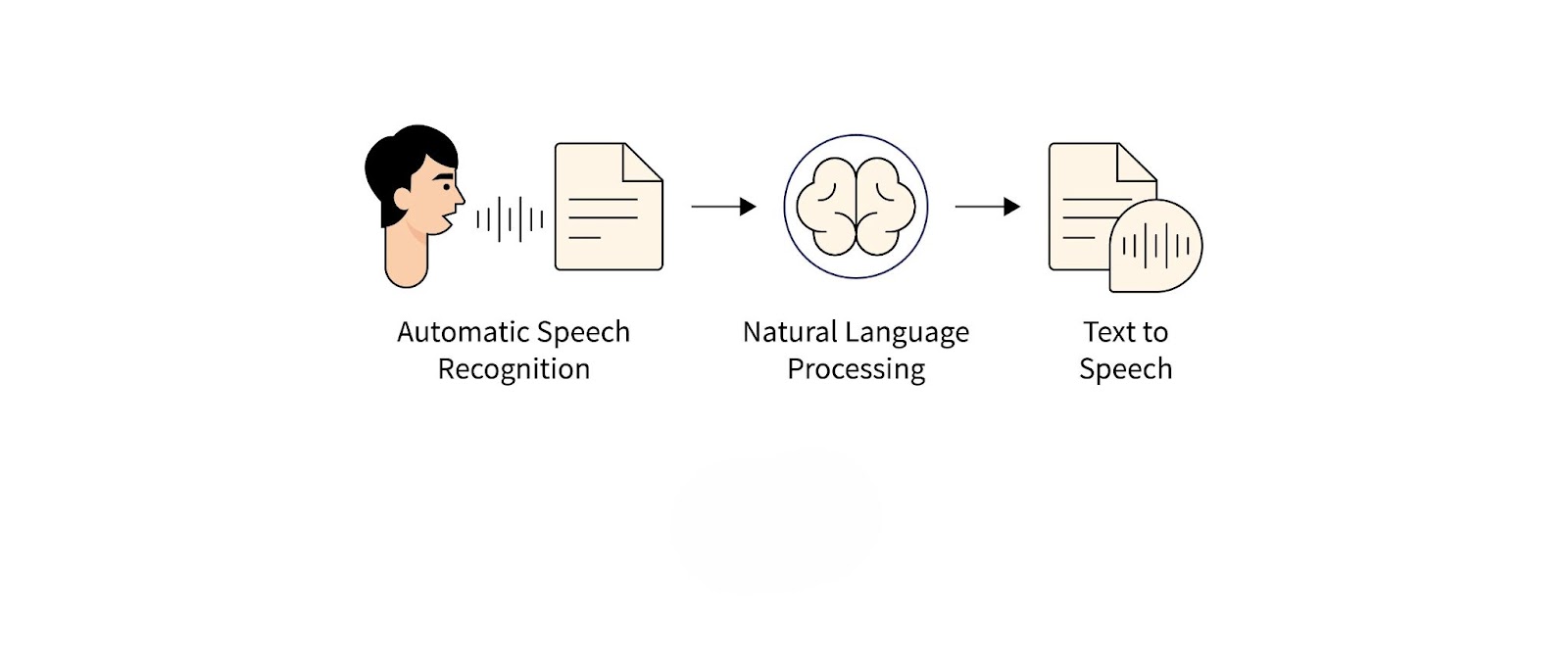
Natural Language Processing (NLP) plays a crucial role in enhancing speech recognition systems. While speech recognition focuses on transcribing spoken words, NLP helps the system understand the meaning and intent behind the words. This combination enables more meaningful interactions with users.
NLP allows speech recognition systems to handle contextual nuances. For example, virtual assistants like Alexa or Google Assistant rely on NLP to interpret user queries accurately and provide relevant responses. Without NLP, speech recognition would be limited to literal transcriptions, reducing its effectiveness in real-world applications.
Additionally, NLP helps manage homophones and ambiguous words by analyzing sentence structure and context. For instance, it distinguishes between “write” and “right” based on how they are used in a sentence. NLP-powered speech systems are commonly integrated into chatbots, customer service tools, and virtual assistants, making them more intuitive and user-friendly.
Challenges with Speech Recognition
Accents and Dialects
Speech recognition systems often struggle with accurately recognizing accents and regional dialects, leading to misinterpretation. Variations in pronunciation across different regions present a significant challenge for creating universally effective systems.
Noisy Environments
Background noise can interfere with speech recognition, making it difficult to accurately capture spoken words. Systems designed for use in noisy environments, such as vehicles or public spaces, require advanced noise-cancellation algorithms.
Homophones and Ambiguity in Speech
Words that sound alike but have different meanings—like “two” and “too”—can confuse speech recognition systems. Without context, these systems may generate incorrect transcriptions or responses.
Language Barriers
Handling multiple languages and code-switching (switching between languages mid-sentence) remains challenging. Speech recognition systems must be trained on diverse linguistic datasets to perform accurately across different languages.
Solutions such as advanced NLP models, noise-canceling technology, and multi-language datasets are being developed to overcome these challenges, improving the performance and reliability of speech recognition systems.
Use Cases of Speech Recognition
Virtual Assistants
Voice-activated virtual assistants like Siri, Alexa, and Google Assistant rely on speech recognition to interact with users. These assistants perform tasks such as setting reminders, answering questions, and controlling smart devices through voice commands.
Healthcare
Speech recognition streamlines medical transcription, allowing healthcare professionals to record patient notes hands-free. It also aids in patient monitoring by converting spoken health updates into electronic records, improving care delivery.
Automotive
In the automotive industry, speech recognition powers voice commands, enabling drivers to control navigation, make calls, and adjust settings without distractions. This enhances safety and convenience during driving.
Customer Service
Many companies use AI-powered voice response systems to manage customer inquiries. Speech recognition helps route calls efficiently, reducing wait times and enhancing customer service experiences.
Accessibility
Speech recognition technology plays a critical role in assisting individuals with disabilities. It enables hands-free interaction with devices, helping people with mobility impairments or visual disabilities access information and control technology effortlessly.
Conclusion
Speech recognition is transforming how we interact with technology, making communication more natural and efficient. As advancements continue, the integration of AI and NLP will further enhance speech systems. With applications spanning multiple industries, speech recognition holds immense potential for improving accessibility, convenience, and user experiences in the future.
References:
- What Is Speech Recognition? | IBM
- Speech Recognition AI: What is it and How Does it Work|Gnani
- Speech Recognition in AI – Scaler Topics


