Ridge Regression is a regularization technique used to reduce overfitting by imposing a penalty on the size of coefficients in a linear regression model. While standard linear regression can provide accurate predictions when there are minimal correlations among features, its performance declines when the dataset experiences multicollinearity (i.e., high correlations among independent variables). This makes Ridge Regression a valuable tool, especially when working with complex datasets.
In machine learning and statistical modeling, Ridge Regression plays a crucial role in improving model stability and generalization. By applying a penalty (L2 regularization) on large coefficients, the algorithm ensures that even highly correlated variables are retained, but with reduced influence. This property makes Ridge Regression ideal for datasets with multiple, highly correlated predictors.
What is Ridge Regression?
Ridge Regression is a linear regression model that includes a regularization term (L2 penalty) to prevent overfitting and reduce the impact of multicollinearity. In standard linear regression, the objective is to minimize the sum of squared errors between predicted and actual values. However, when the model encounters highly correlated features, the coefficients can become unstable, leading to poor generalization on new data.
Ridge Regression modifies the objective function by adding a penalty proportional to the square of the coefficients:
$$Loss = \sum_{i=1}^{n} (y_i – \hat{y}_i)^2 + \lambda \sum_{j=1}^{p} \beta_j^2$$
In this equation:
- $\lambda$ is the regularization parameter controlling the strength of the penalty.
- $\beta_j$ are the model coefficients.
The addition of the L2 penalty encourages the model to keep the coefficients small, making it more robust to overfitting and noisy data. Unlike Lasso Regression, Ridge Regression retains all predictors by shrinking their coefficients instead of eliminating them, making it useful when all features contribute to the target variable.
The Problem: Multicollinearity
Multicollinearity occurs when two or more independent variables in a regression model are highly correlated, meaning they convey redundant information. This makes it challenging to determine the unique effect of each predictor on the target variable. As a result, standard linear regression produces unstable coefficients, which can vary significantly with small changes in the data, reducing the model’s predictive power.
Multicollinearity also leads to overfitting, where the model fits the training data well but performs poorly on unseen data. This happens because the regression algorithm assigns large coefficients to highly correlated features, amplifying errors when making predictions.
Ridge Regression addresses multicollinearity by applying a penalty on large coefficients through L2 regularization. This forces the model to shrink the coefficients of correlated variables, distributing the predictive power more evenly across all features. Even when two variables carry similar information, Ridge Regression assigns smaller but non-zero weights, ensuring more stable predictions and better generalization.
How Ridge Regression Works: The Regularization Algorithm
Ridge Regression applies L2 regularization by adding a penalty equal to the sum of squared coefficients to the objective function. The goal is to minimize the loss function, which balances the error between predicted and actual values, while discouraging large coefficients. The penalty term helps control the model’s complexity, ensuring better generalization on new data.
The mathematical formulation of Ridge Regression is:
$$Loss = \sum_{i=1}^{n} (y_i – \hat{y}_i)^2 + \lambda \sum_{j=1}^{p} \beta_j^2$$
Here:
- $y_i$ is the actual value, and $\hat{y}_i$ is the predicted value.
- $\lambda$ is the regularization parameter.
- $\beta_j$ represents the coefficients of the model.
The Ridge estimator can be derived as:
$$\hat{\beta} = (X^T X + \lambda I)^{-1} X^T y$$
Where:
- $X$ is the matrix of input features.
- $I$ is the identity matrix.
This formula shows how Ridge Regression modifies the ordinary least squares (OLS) approach by adding $\lambda I$, making the matrix invertible even when multicollinearity exists.
The value of $\lambda$ plays a critical role:
- When $\lambda = 0$, Ridge Regression behaves like standard linear regression.
- As $\lambda$ increases, the coefficients shrink, reducing model complexity but potentially introducing bias.
Finding the optimal $\lambda$ is essential to ensure the model performs well on both training and test data, preventing overfitting or underfitting.
Bias-Variance Tradeoff in Ridge Regression
The bias-variance tradeoff is a key concept in machine learning. A model with high bias tends to underfit the data, leading to poor performance on both training and unseen data. On the other hand, a model with high variance may overfit the training data, performing well on it but poorly on new data.
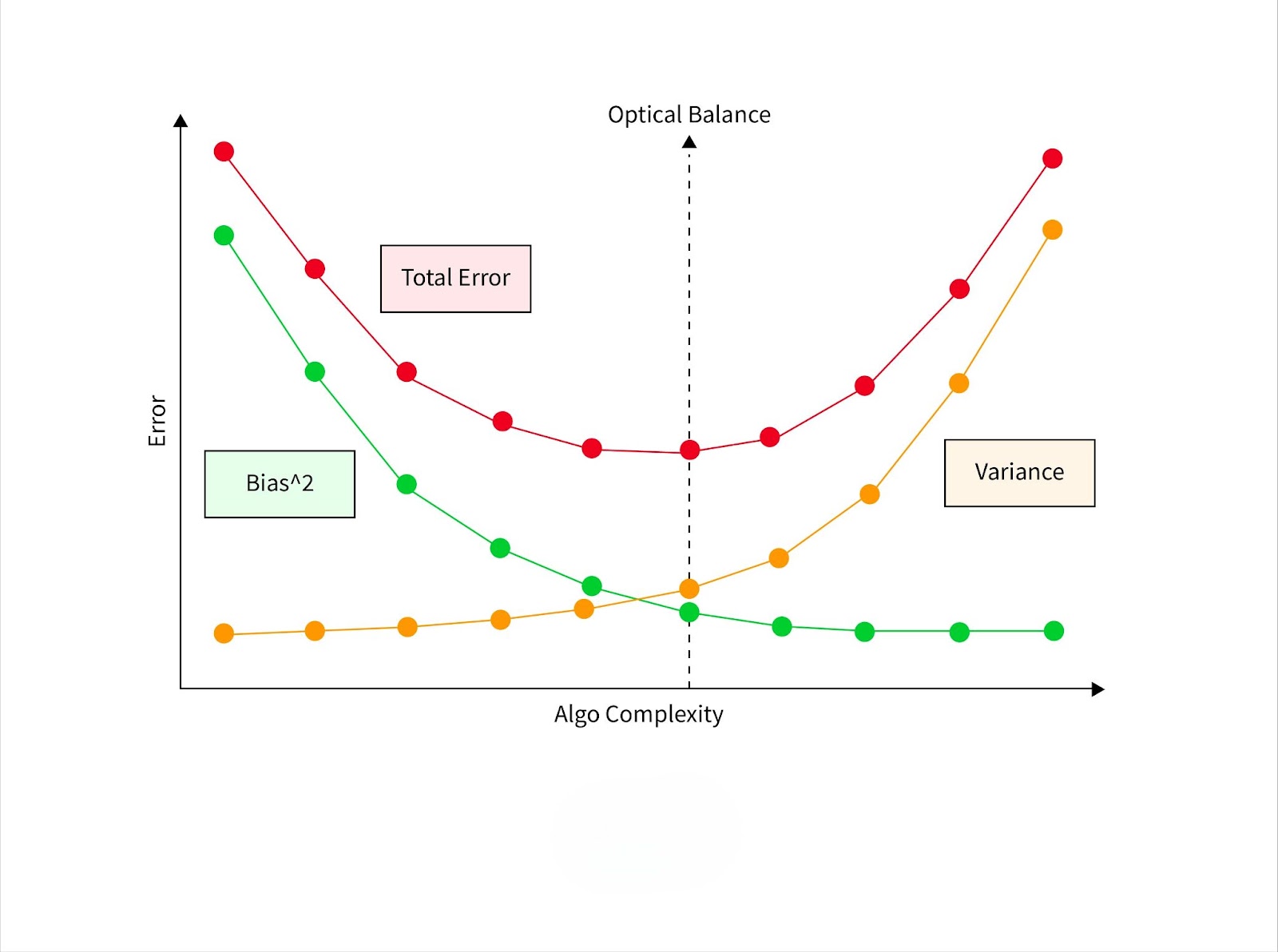
Ridge Regression helps balance bias and variance by introducing a penalty on large coefficients. The regularization parameter λ\lambdaλ determines this balance:
- A small $\lambda$ results in lower bias but higher variance, making the model prone to overfitting.
- A large $\lambda$ increases bias but reduces variance, leading to a simpler model that generalizes better.
By shrinking the coefficients, Ridge Regression reduces the impact of individual predictors, especially when they are highly correlated. This allows the model to find the optimal tradeoff, ensuring good performance on unseen data while avoiding both underfitting and overfitting.
Thus, the success of Ridge Regression depends on tuning $\lambda$ through techniques like cross-validation to achieve the best balance between bias and variance.
Selection of the Ridge Parameter in Ridge Regression
Choosing the optimal value of lambda (λ) is crucial for Ridge Regression to strike the right balance between bias and variance. Various techniques help identify the best regularization parameter, ensuring the model neither overfits nor underfits the data.
1. Cross-Validation
Cross-validation is a widely used technique for selecting the optimal lambda value. The data is divided into K-folds, where the model is trained on K-1 folds and validated on the remaining fold. This process repeats for all folds, and the average performance across all folds helps determine the best lambda.
By evaluating the model on multiple validation sets, cross-validation ensures robust parameter selection, minimizing the risk of overfitting or underfitting.
2. Generalized Cross-Validation (GCV)
Generalized Cross-Validation (GCV) is an extension of standard cross-validation but is computationally more efficient. It avoids the need to split data into folds by computing a metric based on the leave-one-out cross-validation approach. GCV estimates the predictive error using all data points, providing an unbiased estimate for selecting lambda.
The advantage of GCV is that it requires fewer computations, making it well-suited for large datasets.
3. Information Criteria
Information criteria like Akaike Information Criterion (AIC) and Bayesian Information Criterion (BIC) are useful for model selection and parameter tuning. These criteria penalize models for complexity, helping to avoid overfitting.
- AIC focuses on the goodness of fit and penalizes complex models.
- BIC applies a stricter penalty on complexity, making it more conservative.
These criteria guide the selection of the optimal lambda by balancing model performance and simplicity.
4. Empirical Bayes Methods
Empirical Bayes methods provide a statistical framework for selecting the regularization parameter by treating lambda as a hyperparameter. In this approach, lambda is estimated from the data itself using prior distributions, offering a probabilistic perspective on parameter selection.
This method is particularly helpful when prior knowledge about the data is available, and it improves the interpretability of the regularization process.
5. Practical Considerations for Selecting Ridge Parameter
When selecting lambda, consider data size, model complexity, and prediction goals. Cross-validation is often the go-to method, but for large datasets, GCV offers a more efficient alternative. Depending on the problem, AIC, BIC, or Empirical Bayes methods may also offer valuable insights into setting the optimal lambda.
Ridge Regression vs. Lasso Regression
Ridge Regression (L2 regularization) and Lasso Regression (L1 regularization) are two popular regularization techniques that help prevent overfitting by adding a penalty to the model’s coefficients. While both methods serve similar purposes, they differ in how they apply penalties and handle coefficients.
- Ridge Regression:
- Adds the square of the coefficients as a penalty.
- Shrinks coefficients but does not eliminate any features.
- Suitable when all predictors contribute to the outcome, especially in the presence of multicollinearity.
- Lasso Regression:
- Adds the absolute values of the coefficients as a penalty.
- Can shrink some coefficients to zero, performing feature selection.
- Useful when only a subset of predictors are important for the model.
When to Use Ridge vs. Lasso
- Use Ridge Regression when you expect all variables to have some predictive power, or when multicollinearity is present.
- Use Lasso Regression when feature selection is critical, especially in high-dimensional datasets with many irrelevant features.
Applications of Ridge Regression in Machine Learning
Ridge Regression is widely used in machine learning to enhance model generalization by controlling the impact of correlated features. It is applicable across a variety of fields where predictive accuracy is needed without overfitting.
1. Model Complexity
One of the key strengths of Ridge Regression is its ability to control model complexity by shrinking the coefficients of less important features. As the lambda parameter increases, the influence of smaller coefficients is reduced, simplifying the model without completely eliminating predictors. This makes Ridge Regression particularly effective when all variables carry some predictive information, ensuring they are not discarded like in Lasso Regression.
In scenarios where multicollinearity exists, Ridge Regression distributes the weight across correlated predictors, resulting in more stable models. This approach is crucial when working with datasets where eliminating variables might lead to information loss.
2. Example Use Cases
Ridge Regression is commonly used in various fields for predictive analytics:
- Finance: Forecasting stock prices and credit scoring models, where multiple economic indicators are correlated.
- Healthcare: Predicting patient outcomes using multiple medical factors, ensuring that all relevant variables are accounted for.
- Marketing Analytics: Estimating the effectiveness of advertising campaigns by analyzing correlated marketing channels, ensuring a comprehensive understanding of their combined impact.
Its ability to manage multicollinearity and retain all predictors makes Ridge Regression a preferred choice in these sectors, providing robust and generalizable models that can handle complex, real-world data.
Advantages and Disadvantages of Ridge Regression
Advantages
Ridge Regression offers several benefits that make it a valuable tool in predictive modeling:
- Reduces overfitting by shrinking the coefficients, ensuring the model generalizes well on unseen data.
- Helps manage multicollinearity by distributing the influence of correlated predictors.
- Retains all features, allowing even minor predictors to contribute to the model’s accuracy.
- Improves model stability by ensuring that the coefficients remain consistent, even with highly correlated variables.
These advantages make Ridge Regression ideal for applications where maintaining all predictors is necessary, and the goal is to build a robust and interpretable model.
Disadvantages
Despite its strengths, Ridge Regression has some limitations:
- It does not perform feature selection, meaning all variables remain in the model, even if some contribute minimally.
- Choosing the right lambda can be challenging and requires careful tuning through cross-validation.
- Ridge Regression may struggle with high-dimensional datasets where many predictors are irrelevant, as it cannot shrink coefficients to zero like Lasso Regression.
- When dealing with non-linear relationships, Ridge Regression’s linear approach may not capture all complexities, requiring more sophisticated models.
While Ridge Regression excels in many areas, it may not always be the best fit for every machine learning problem.
Conclusion
Ridge Regression is a powerful regularization technique that helps manage multicollinearity and improve model generalization by shrinking coefficients. Its ability to retain all features and prevent overfitting makes it a reliable choice for various applications. Careful lambda selection ensures optimal model performance across different scenarios.
References:


