In machine learning, regression is a core technique used to model the relationships between variables and predict continuous outcomes. From forecasting stock prices to estimating housing costs, regression helps in data-driven decision-making by identifying trends and patterns in data, making it essential for predictive modeling.
What is Regression?
Regression is a statistical method used in machine learning to model and analyze the relationships between a dependent variable (target) and one or more independent variables (predictors). The primary purpose of regression is to predict a continuous outcome based on input features.
Regression allows us to quantify the relationship between variables and use that information to predict future outcomes. The regression line or curve represents the best fit for the observed data points, minimizing the difference between the actual values and the predicted values.
Difference between Regression and Classification
While regression predicts continuous values (e.g., predicting house prices), classification is used to categorize data into distinct classes (e.g., spam or non-spam emails). Regression deals with numerical outputs, while classification works with categorical outputs.
In regression analysis, models can be built for both linear and nonlinear relationships between variables. The most common regression method is linear regression, but there are several other types, including logistic regression, polynomial regression, and regularization techniques like Ridge and Lasso regression.
Types of Regression in Machine Learning
There are several types of regression techniques used in machine learning, each with its own applications and strengths:
1. Linear Regression
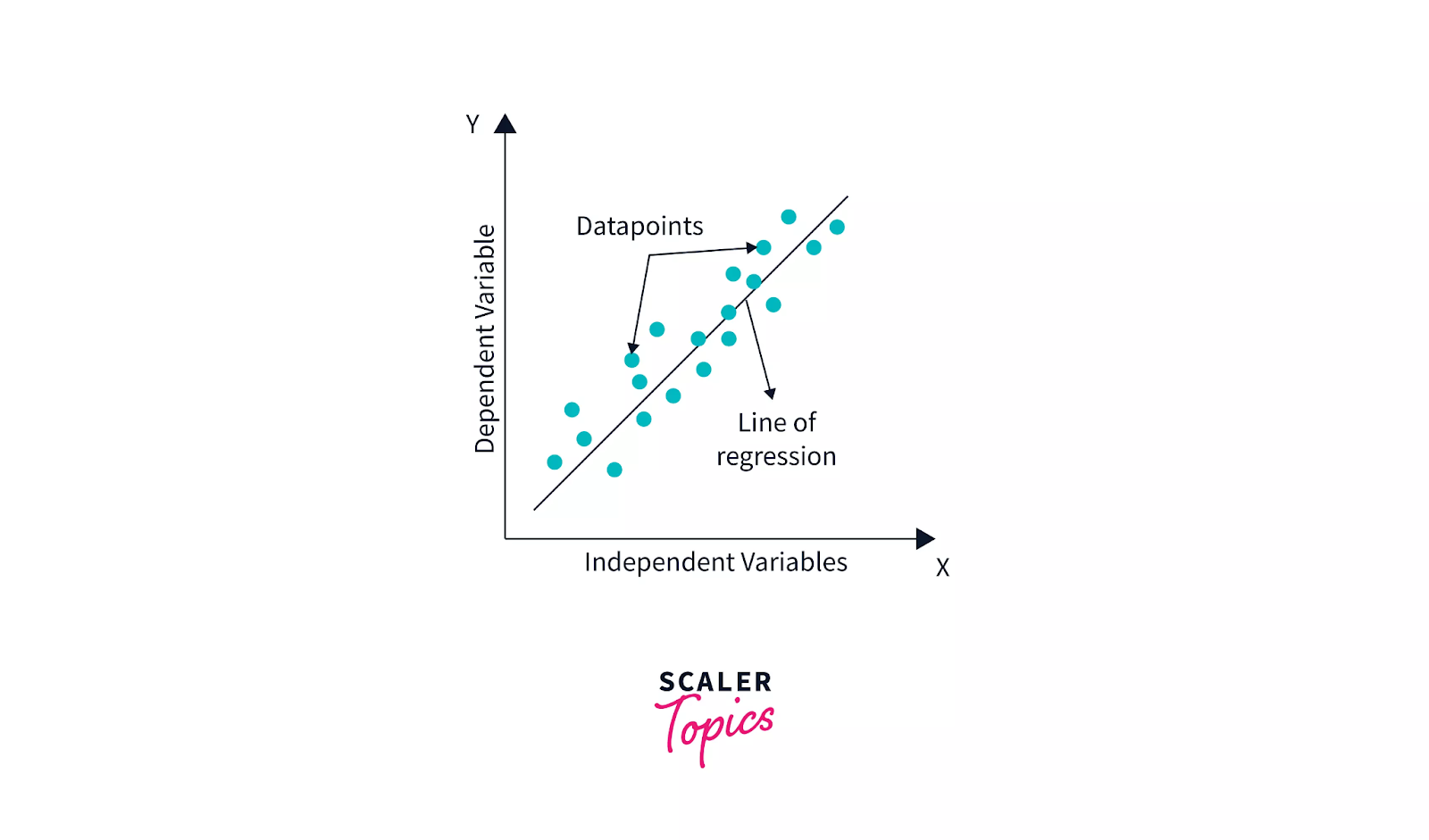
Linear regression is one of the simplest and most widely used techniques for predicting the relationship between a dependent variable and one or more independent variables. In simple linear regression, there is one independent variable, while multiple linear regression involves two or more predictors.
- Use Cases: Predicting house prices, stock prices, or sales based on multiple factors like location, interest rates, and marketing spend.
2. Logistic Regression
Logistic regression is a classification algorithm that predicts the probability of a binary outcome (e.g., yes/no, true/false). Despite its name, logistic regression is used for classification tasks, not regression. It uses the logistic function to output probabilities that can be mapped to binary categories.
- Use Cases: Predicting whether a customer will buy a product (yes/no), whether a patient has a disease (yes/no), or spam detection in emails.
3. Polynomial Regression
Polynomial regression is used when the relationship between the dependent and independent variables is nonlinear. It fits a polynomial equation (e.g., quadratic, cubic) to the data points, making it suitable for datasets with curves.
- Use Cases: Modeling complex relationships in data, such as predicting the progression of diseases or analyzing the impact of multiple factors on temperature changes.
4. Ridge and Lasso Regression
Ridge regression and Lasso regression are regularization techniques that prevent overfitting by adding a penalty to the regression coefficients. Ridge uses L2 regularization, while Lasso uses L1 regularization.
- Use Cases: These methods are useful in scenarios where we have many predictors, and some of them may not be significant. Ridge and Lasso help in selecting important features and improving model generalization.
Key Terminologies in Regression
Understanding key terminologies is crucial to grasp how regression works. Here are some of the important concepts:
Dependent and Independent Variables
- Dependent Variable (Y): The target variable we aim to predict.
- Independent Variables (X): The input features or predictors that influence the dependent variable.
Coefficients and Intercepts
- Coefficients: These represent the strength and direction of the relationship between each independent variable and the dependent variable.
- Intercept: The value of the dependent variable when all independent variables are zero.
Residuals and Errors
- Residuals: The difference between the observed value and the predicted value of the dependent variable.
- Errors: The terms used to describe the deviation of the predicted values from the true values.
R-Squared and Adjusted R-Squared
- R-Squared: A metric that shows the percentage of variance in the dependent variable explained by the independent variables.
- Adjusted R-Squared: A modified version of R-Squared that adjusts for the number of predictors used in the model.
Overfitting and Underfitting
- Overfitting: A model is overfitting when it performs well on training data but poorly on unseen data due to learning noise or irrelevant details.
- Underfitting: A model is underfitting when it is too simple and fails to capture the underlying patterns in the data.
How Regression Works in Machine Learning
In machine learning, regression algorithms work by fitting a line or curve to the data in such a way that the difference between the actual and predicted values is minimized. The objective is to find the best-fitting model that can accurately predict future outcomes based on input features.
Cost Function
The performance of a regression model is evaluated using a cost function, which measures the error between the predicted values and the actual values. The most commonly used cost function is mean squared error (MSE), which calculates the average squared difference between the actual and predicted values.
Optimization Techniques
To minimize the cost function, optimization algorithms like gradient descent are used. Gradient descent iteratively updates the model’s parameters (coefficients and intercept) to reduce the error. By calculating the gradient (slope) of the cost function, the algorithm adjusts the parameters in the direction that minimizes the error.
In summary, regression models aim to find the relationship between input features and the target variable by minimizing prediction errors using cost functions and optimization techniques.
Evaluating Regression Models
Evaluating a regression model is crucial for understanding its performance and reliability. There are several metrics and concepts used to measure how well the model fits the data and how accurately it can predict future outcomes.
Metrics for Regression Evaluation
- Mean Absolute Error (MAE)
MAE measures the average magnitude of errors between the predicted and actual values, regardless of direction. It provides a straightforward interpretation of how far off predictions are from the true values.- Formula:
$$\text{MAE} = \frac{1}{n} \sum_{i=1}^{n} |y_i – \hat{y}_i|$$
- Formula:
- Mean Squared Error (MSE)
MSE squares the error before averaging, placing a higher penalty on large errors. This metric emphasizes larger errors more than MAE, making it useful when significant deviations are undesirable.- Formula:
$$\text{MSE} = \frac{1}{n} \sum_{i=1}^{n} (y_i – \hat{y}_i)^2$$
- Formula:
- Root Mean Squared Error (RMSE)
RMSE is the square root of the MSE, providing an error metric in the same units as the target variable. It’s useful for interpreting the magnitude of errors in context with the data.- Formula:
$$\text{RMSE} = \sqrt{\frac{1}{n} \sum_{i=1}^{n} (y_i – \hat{y}_i)^2}$$
- Formula:
The Bias-Variance Trade-off
The bias-variance trade-off is a key concept in machine learning. Bias refers to the error introduced by approximating a real-world problem with a simplified model, while variance refers to the model’s sensitivity to fluctuations in the training data.
- Underfitting (High Bias): A model with high bias pays little attention to the training data and oversimplifies the problem, leading to underfitting.
- Overfitting (High Variance): A model with high variance is too closely tied to the training data, leading to overfitting, where it performs well on the training data but poorly on unseen data.
Balancing bias and variance is essential for creating a model that generalizes well.
Applications of Regression
Regression techniques are widely used in various industries for predictive modeling. Here are some real-world applications:
1. Predicting Housing Prices
In the real estate industry, regression models are used to predict housing prices based on factors like location, square footage, and nearby amenities.
- Example: A linear regression model can predict the price of a house based on historical data and property features.
2. Forecasting Stock Prices
Financial analysts use regression models to forecast stock prices by analyzing historical stock performance and external market factors.
- Example: Multiple regression can help predict stock prices by considering multiple economic indicators like interest rates, market trends, and company performance.
3. Marketing and Sales Prediction
In marketing, regression models predict future sales based on advertising spend, customer demographics, and other marketing metrics.
- Example: Companies can use regression analysis to forecast how an increase in marketing budget might impact future sales.
4. Medical Research
In healthcare, regression is used in medical research to identify the relationship between risk factors and disease outcomes.
- Example: Logistic regression can help predict the likelihood of developing a disease based on factors such as age, lifestyle, and family history.
Advantages and Disadvantages of Regression
Advantages of Regression
Regression offers several advantages, making it a popular tool for predictive modeling:
- Simplicity: Regression is easy to implement and interpret. The relationship between variables can be quantified, and the resulting model is straightforward to understand.
- Interpretability: The coefficients in a regression model provide direct insights into the effect of each independent variable on the dependent variable.
- Predictive Power: Regression models can be used for prediction and forecasting in various industries, from finance to healthcare.
Disadvantages of Regression
Despite its advantages, regression also has some limitations:
- Sensitivity to Outliers: Regression models can be highly sensitive to outliers, which can distort the predictions.
- Assumes Linearity: Linear regression assumes that relationships between variables are linear, which may not always be the case in real-world data.
- Overfitting in Complex Models: Without regularization techniques like Ridge or Lasso, regression models with too many predictors may overfit the training data, resulting in poor generalization on unseen data.
Python Implementation of Regression
Simple Linear Regression Code in Python
Here’s a basic implementation of simple linear regression in Python using the scikit-learn library:
# Importing libraries
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
# Generating some data
X = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]).reshape(-1, 1)
y = np.array([2, 4, 5, 4, 5, 6, 7, 8, 9, 10])
# Splitting data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Creating and fitting the model
model = LinearRegression()
model.fit(X_train, y_train)
# Making predictions
y_pred = model.predict(X_test)Visualizing the Regression Line
After building the model, you can visualize the regression line to see how well it fits the data:
# Plotting the regression line
plt.scatter(X_test, y_test, color='blue')
plt.plot(X_test, y_pred, color='red')
plt.xlabel('Independent Variable (X)')
plt.ylabel('Dependent Variable (y)')
plt.show()Evaluating the Python Model
After fitting the model, you can evaluate its performance using metrics like MAE, MSE, and RMSE:
from sklearn.metrics import mean_absolute_error, mean_squared_error
# Mean Absolute Error
mae = mean_absolute_error(y_test, y_pred)
print(f'Mean Absolute Error: {mae}')
# Mean Squared Error
mse = mean_squared_error(y_test, y_pred)
print(f'Mean Squared Error: {mse}')
# Root Mean Squared Error
rmse = np.sqrt(mse)
print(f'Root Mean Squared Error: {rmse}')Conclusion
Regression is a key technique in machine learning, providing a powerful tool for predictive modeling and data analysis. By understanding the relationships between variables, regression allows for accurate forecasting in various fields such as finance, healthcare, and marketing. While regression models are simple and interpretable, they are sensitive to outliers and can overfit complex datasets without regularization. With the right approach and evaluation metrics, regression remains an essential method for deriving insights and making data-driven decisions.
References:
- Regression in Machine Learning: Definition and Examples | Built In
- Regression in Machine Learning – Scaler Topics


