Machine learning models are powerful tools for extracting patterns from data and making predictions. However, two critical challenges—overfitting and underfitting—can significantly impact a model’s performance. In this article, we’ll explore what overfitting and underfitting are, their causes, and practical techniques to address them. Whether you’re a beginner or experienced practitioner, understanding these concepts is essential for building robust machine learning models.
Understanding Bias and Variance
Bias and variance are two fundamental concepts that influence the performance of machine learning models. Bias refers to errors introduced by oversimplifying a model, while variance refers to the model’s sensitivity to fluctuations in the training data. Overfitting and underfitting arise from imbalances between bias and variance, known as the bias-variance trade-off. High bias can lead to underfitting, while high variance often results in overfitting.
Visualizing the Bias-Variance Trade-off
To better understand this trade-off, imagine a target. A model with high bias produces predictions far from the bullseye (low accuracy), while one with high variance may scatter predictions widely across the target. The key is to find a balance between these two, ensuring the model is neither too simple (underfitting) nor too complex (overfitting).
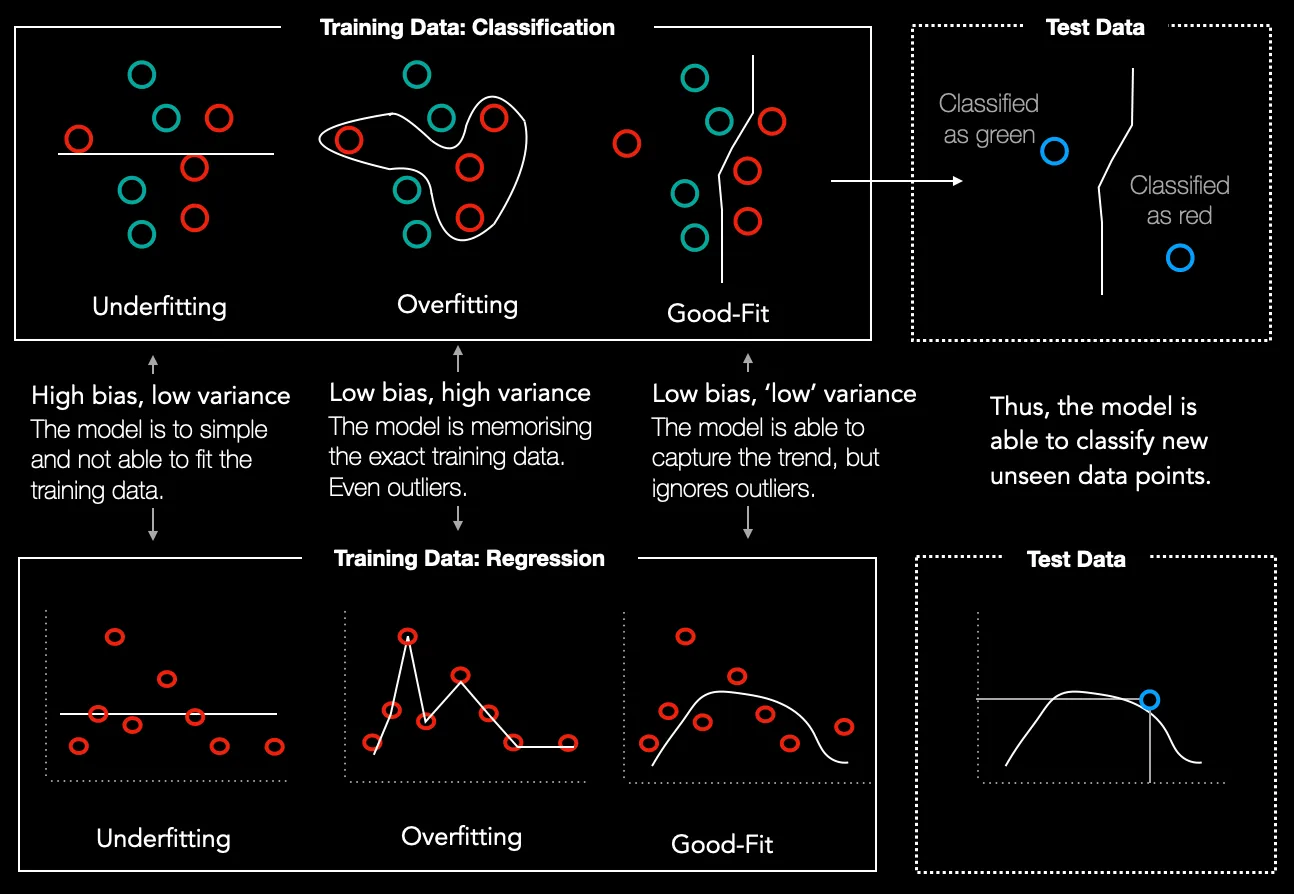
Overfitting: When Your Model Knows Too Much
What is Overfitting?
Overfitting occurs when a machine learning model learns the noise in the training data rather than the actual patterns. As a result, it performs exceptionally well on the training data but struggles to generalize to unseen data. For instance, a model trained to recognize images of cats may memorize every detail in the training set, but fail when presented with new, slightly different images.
Common Signs of Overfitting:
- High accuracy on training data but poor performance on validation/test data.
- Complexity in model architecture that doesn’t translate to general improvements.
Causes of Overfitting
Several factors contribute to overfitting:
- Complex models with too many parameters or layers.
- Excessive features that introduce noise.
- Insufficient data that forces the model to overcompensate.
- Noise or outliers in the dataset.
- Overtraining, especially with too many epochs in neural networks.
Techniques to Reduce Overfitting
To combat overfitting, several strategies can be implemented:
- Regularization: Techniques like L1 and L2 regularization penalize large coefficients, encouraging the model to simplify itself.
- Cross-validation: Split the dataset into multiple folds to ensure the model generalizes well across different subsets of data.
- Early stopping: Monitor performance on a validation set and stop training when performance starts to deteriorate.
- Simpler models: Use fewer features or a simpler model architecture to avoid over-complication.
- Data augmentation: In domains like image classification, artificially increase the size of your dataset by transforming the input images (rotations, flips, etc.).
Python Code
# Example of L2 Regularization in Python (using scikit-learn)
from sklearn.linear_model import Ridge
model = Ridge(alpha=1.0) # L2 Regularization
model.fit(X_train, y_train)Underfitting: When Your Model Knows Too Little
What is Underfitting?
Underfitting happens when a machine learning model is too simple to capture the underlying patterns in the data. This results in low accuracy on both the training and test sets. For example, a linear regression model may underfit data that has a complex, non-linear relationship.
Common Signs of Underfitting:
- Low accuracy on both training and test data.
- Underwhelming performance regardless of adjustments.
Causes of Underfitting
Common reasons include:
- Simple models that cannot capture the complexity of the data.
- Insufficient features that fail to represent the problem adequately.
- Lack of training data, leading to poor learning.
- Noisy data that confuses the model.
- Inappropriate hyperparameters, such as a learning rate that’s too small.
Techniques to Reduce Underfitting
- Increase model complexity: Use more sophisticated models, like decision trees or deep learning architectures.
- Add more features: Introduce additional relevant features that can help the model capture complex relationships.
- Gather more data: A larger training set improves model learning.
- Adjust hyperparameters: Increase the learning rate or number of epochs for better results.
Python Code
# Example of Adjusting Learning Rate in TensorFlow
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.01),
loss='categorical_crossentropy',
metrics=['accuracy'])Achieving the Goldilocks Zone: Optimal Model Fitting
To build an effective machine learning model, the goal is to achieve the perfect balance between bias and variance. This is often referred to as finding a good fit—a model that performs well on both the training and test data.
What is a Good Fit?
A well-fitted model strikes a balance between overfitting and underfitting:
- Balanced bias and variance.
- High accuracy on both training and validation/test datasets.
- Generalizability to new, unseen data.
Strategies for Optimal Fitting
- Experimentation with different models: Compare models like decision trees, random forests, or neural networks to find the best fit.
- Tuning hyperparameters: Use grid search or random search to find the ideal parameters for your model.
- Performance metrics: Evaluate your model using metrics such as accuracy, precision, recall, and F1-score to assess its generalization ability.
- Iterative tuning: Continuously fine-tune and evaluate your model using cross-validation and other metrics.
Real-World Applications of Overfitting and Underfitting
In practice, machine learning applications from different domains face overfitting and underfitting challenges. Let’s look at two prominent areas:
Image Classification
In deep learning-based image classification tasks, overfitting can occur when the model memorizes specific images in the training set rather than learning general features of objects, such as edges or textures. Techniques like data augmentation and dropout are commonly used to mitigate this.
Natural Language Processing (NLP)
In NLP, overfitting is a frequent issue due to the high-dimensional nature of text data. Methods like regularization and the use of pre-trained models like BERT help to alleviate this issue by providing robust generalization.
Conclusion
Overfitting and underfitting are critical issues that can hinder the success of machine learning models. By understanding and addressing these problems through strategies such as regularization, cross-validation, and hyperparameter tuning, you can improve your model’s performance and generalizability. Ultimately, mastering the balance between bias and variance is key to achieving a well-fitted model.
As you continue your machine learning journey, experiment with different models, datasets, and techniques to find the optimal balance for your specific projects.


