Outliers are data points that significantly deviate from the rest of the dataset. These anomalies can arise due to measurement errors, data entry issues, or natural variations in data. In machine learning, outliers can disrupt model training by introducing noise, leading to skewed predictions and reduced accuracy. Detecting and handling outliers is a crucial step to ensure models perform optimally and generate reliable results. This article will explore various methods and techniques for detecting outliers in a dataset.
What is an Outlier in Machine Learning?
In machine learning, an outlier is a data point that differs significantly from other observations in a dataset. Outliers are often distant from the main cluster of data points, making them stand out. They can arise due to a variety of reasons, such as data entry mistakes, sensor errors, or genuine rare occurrences.
There are three main types of outliers:
- Global Outliers: These are data points that deviate significantly from the entire dataset. They are far away from the central data points, which makes them easy to spot.
- Contextual Outliers: These outliers are considered anomalous based on a specific context. For example, a high temperature may be normal in summer but anomalous in winter.
- Collective Outliers: These are a set of data points that together behave differently from the rest of the dataset. Individually, they might not seem anomalous, but when considered as a group, they form an outlier pattern.
Outliers are important to detect because they can affect the performance of machine learning models, leading to biased predictions and reduced accuracy.
Why do we Need to Detect Outliers?
Outliers can have a significant impact on the performance of machine learning models. Here’s why detecting and addressing outliers is crucial:
- Biased Models: Outliers can distort the underlying patterns in the data, leading to biased models. This results in inaccurate predictions, as the model gives undue weight to these extreme points.
- Reduced Accuracy: Machine learning models, especially those that rely on averages or distances (e.g., linear regression or k-nearest neighbors), can suffer from reduced accuracy if outliers are present.
- Increased Variance: Outliers increase the variance in the dataset, making the model less stable and more prone to overfitting.
- Reduced Interpretability: When outliers are present, the model’s predictions become harder to interpret. It becomes difficult to differentiate between true patterns and noise introduced by outliers.
Outlier Detection Methods in Machine Learning
There are several methods used to detect outliers in machine learning. These techniques range from simple statistical methods to more complex algorithms. Below are some of the most common methods:
- Statistical Methods: Statistical techniques are useful for datasets that follow a normal distribution. The assumption here is that data points lying far away from the mean are considered outliers. Key statistical methods include:
- Standard Deviation: Data points that are more than three standard deviations away from the mean are considered outliers.
- Z-Score: This method calculates how many standard deviations a data point is away from the mean. A Z-score beyond a certain threshold (commonly 3 or -3) indicates an outlier.
- Distance-Based Methods: These methods rely on the distance between data points. Points that are far away from the main cluster of data are classified as outliers. One example is:
- K-Nearest Neighbors (KNN): In this method, data points that have few neighbors within a certain distance can be identified as outliers.
- Clustering-Based Methods: Clustering methods group data points based on their similarities. Outliers are points that do not fit well within any cluster. Examples include:
- Isolation Forest: This algorithm isolates anomalies by randomly selecting a feature and splitting the data. Outliers require fewer splits to be isolated, making them easy to detect.
- One-Class Support Vector Machine (OCSVM): OCSVM is a classification method that learns the normal behavior of the data and identifies points that deviate from this behavior. It is particularly useful for datasets with imbalanced classes, where outliers are rare.
Each of these methods has its strengths and is suitable for different types of data. Understanding the characteristics of your dataset is crucial for choosing the right detection method.
How to Detect Outliers Using Standard Deviation
Standard deviation is one of the simplest and most widely used methods for detecting outliers. In a normally distributed dataset, most data points fall within a certain range around the mean. Data points that are too far from the mean can be considered outliers.
Here’s how you can detect outliers using standard deviation:
- Calculate the Mean (µ): The first step is to calculate the mean (average) of your dataset.
- Calculate the Standard Deviation (σ): The standard deviation tells us how much the data points deviate from the mean.
- Set a Threshold: A common rule of thumb is to mark data points as outliers if they fall more than three standard deviations away from the mean (i.e., beyond µ + 3σ or below µ – 3σ).
For example, if the mean of a dataset is 50 and the standard deviation is 5, then any data point outside the range of 35 to 65 can be considered an outlier.
This method is effective for datasets that follow a normal distribution but may not be suitable for skewed or multimodal data.
Here’s a code example using Python to detect outliers using standard deviation:
import numpy as np
# Sample dataset
data = [10, 12, 12, 13, 12, 11, 10, 9, 12, 13, 100]
# Calculate mean and standard deviation
mean = np.mean(data)
std_dev = np.std(data)
# Set threshold (3 standard deviations)
threshold = 3
# Identify outliers
outliers = [x for x in data if np.abs((x - mean) / std_dev) > threshold]
# Print results
print(f"Mean: {mean}")
print(f"Standard Deviation: {std_dev}")
print(f"Outliers: {outliers}")Explanation:
- Mean and Standard Deviation: The code calculates the mean and standard deviation of the dataset.
- Threshold: We set the threshold to 3 standard deviations.
- Detecting Outliers: We calculate the Z-score for each data point and check if it exceeds the threshold. Any data point more than 3 standard deviations away from the mean is considered an outlier.
For the sample dataset, the output will identify the value 100 as an outlier because it is far from the other values.
How to Detect Outliers Using the Z-Score
The Z-score method is another effective way to detect outliers. It measures how many standard deviations a data point is away from the mean of the dataset. A Z-score beyond a specified threshold indicates an outlier. This method works well for data that is normally distributed.
Here’s how to detect outliers using the Z-score:
- Calculate the Mean (µ) and Standard Deviation (σ): First, calculate the mean and standard deviation of the dataset.
- Calculate the Z-Score: The Z-score for each data point is calculated using the formula:
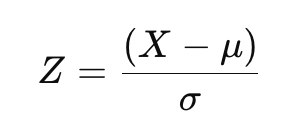
Where X is the data point, μ is the mean, and σ is the standard deviation.
- Set a Threshold: Typically, a Z-score greater than 3 or less than -3 is considered an outlier.
Here’s a code example to demonstrate this:
import numpy as np
from scipy import stats
# Sample dataset
data = [10, 12, 12, 13, 12, 11, 10, 9, 12, 13, 100]
# Calculate Z-scores
z_scores = stats.zscore(data)
# Set threshold for Z-scores
threshold = 3
# Identify outliers
outliers = np.where(np.abs(z_scores) > threshold)
# Print results
print(f"Z-scores: {z_scores}")
print(f"Outliers at positions: {outliers}")
print(f"Outlier values: {[data[i] for i in outliers[0]]}")Explanation:
- Z-Score Calculation: We use stats.zscore() to calculate the Z-scores for each data point.
- Threshold: Any data point with a Z-score beyond the threshold (3 or -3) is considered an outlier.
- Identifying Outliers: The code identifies and prints the positions and values of the outliers.
In this example, the value 100 will be identified as an outlier because it has a Z-score greater than 3.
How to Detect Outliers Using the Interquartile Range (IQR)
The Interquartile Range (IQR) method is a widely used technique to detect outliers, especially for skewed datasets or data that doesn’t follow a normal distribution. It measures the spread of the middle 50% of the data and identifies outliers based on the range between the 1st quartile (Q1) and the 3rd quartile (Q3).
Here’s how you can detect outliers using the IQR method:
- Calculate Q1 and Q3: The 1st quartile (Q1) is the median of the lower half of the dataset, and the 3rd quartile (Q3) is the median of the upper half.
- Calculate the IQR: The IQR is the difference between Q3 and Q1.
IQR=Q3−Q1 - Set the Bounds: To identify outliers, we calculate the upper and lower bounds:
LowerBound=Q1−1.5×IQR
UpperBound=Q3+1.5×IQR - Identify Outliers: Any data point outside these bounds is considered an outlier.
Here’s a code example to demonstrate this:
import numpy as np
# Sample dataset
data = [10, 12, 12, 13, 12, 11, 10, 9, 12, 13, 100]
# Calculate Q1 (25th percentile) and Q3 (75th percentile)
Q1 = np.percentile(data, 25)
Q3 = np.percentile(data, 75)
# Calculate IQR
IQR = Q3 - Q1
# Set bounds for outliers
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
# Identify outliers
outliers = [x for x in data if x < lower_bound or x > upper_bound]
# Print results
print(f"Q1: {Q1}")
print(f"Q3: {Q3}")
print(f"IQR: {IQR}")
print(f"Lower Bound: {lower_bound}")
print(f"Upper Bound: {upper_bound}")
print(f"Outliers: {outliers}")Explanation:
- Percentile Calculation: The code calculates Q1 and Q3 using np.percentile().
- IQR Calculation: The IQR is derived by subtracting Q1 from Q3.
- Bounds for Outliers: The lower and upper bounds are calculated using the 1.5 × IQR rule. Any data points outside these bounds are considered outliers.
In this example, the value 100 will be flagged as an outlier because it exceeds the upper bound.
Techniques for Handling Outliers in Machine Learning
Once outliers are detected, you can manage them using various techniques:
- Removal: Outliers that result from data entry errors or irrelevant noise can be safely removed from the dataset if they don’t provide useful insights.
- Transformation: Methods like scaling, normalization, or logarithmic transformation can reduce the effect of outliers while keeping them in the dataset, making them less disruptive for models sensitive to extreme values.
- Robust Estimation: Algorithms like Decision Trees, Random Forests, and Gradient Boosting are naturally resistant to outliers, as they are less influenced by the distribution of the data.
- Modeling Outliers: In cases where outliers represent valuable information (e.g., fraud detection or rare events), they can be modeled separately as a distinct class.
Importance of Outlier Detection in Machine Learning
Detecting outliers is essential for improving the performance and reliability of machine learning models. Key reasons include:
- Improved Model Accuracy: Removing or managing outliers ensures the model learns from true patterns in the data, leading to more accurate predictions.
- Reduced Bias: Outliers can introduce bias into the model, skewing results. Identifying and handling them helps avoid this.
- Enhanced Interpretability: Models trained on clean, outlier-free data produce results that are easier to interpret and explain.
- Robustness in Real-World Applications: In fields like fraud detection or healthcare, outliers may represent rare but important events. Properly handling them can improve the model’s ability to detect anomalies.
Conclusion
Outliers can significantly impact the performance of machine learning models, leading to biased results, reduced accuracy, and poor interpretability. By understanding and applying various detection methods such as standard deviation, Z-score, and IQR, you can effectively identify and manage outliers. Handling outliers appropriately—whether by removing them, transforming the data, or using robust algorithms—helps improve the overall accuracy and reliability of your models. Ultimately, outlier detection is a crucial step in building models that perform well in real-world scenarios, especially in fields where anomalies hold valuable insights.


