In machine learning, the quality of your model is heavily influenced by the data it is trained on. One essential step in data preprocessing is ensuring that the data is properly scaled to improve model performance. This is where normalization comes into play.
Normalization is a technique used to scale numerical data features into a common range without distorting the differences in the data’s relative relationships. In machine learning models, especially those that rely on distance metrics like k-Nearest Neighbors (k-NN) and k-means clustering, having features with vastly different scales can hinder model accuracy. By applying normalization, data can be transformed to a specific scale (e.g., 0 to 1) while maintaining its overall structure.
In this article, we will explore various normalization techniques, discuss the difference between normalization and standardization, and explain when each approach is most beneficial for machine learning algorithms.
What is Normalization in Machine Learning?
Normalization in machine learning refers to the process of scaling individual features so that they fall within a specific range, typically between 0 and 1. The main objective is to ensure that numerical features on different scales are adjusted to a common range, allowing machine learning algorithms to perform optimally.
In practice, normalization transforms the data while maintaining the relative distance between data points. Unlike other scaling methods like standardization, which alters the distribution by centering it around a mean, normalization focuses purely on scaling the data to a defined range. This is particularly useful when working with machine learning algorithms that rely on distance metrics, such as k-NN, where large variations in scale can skew results.
Normalization is commonly employed in cases where:
- Features have different units of measurement (e.g., age in years vs. income in dollars).
- The algorithm being used is sensitive to the magnitude of data, such as in neural networks and distance-based algorithms.
By normalizing the data, you make it easier for algorithms to interpret the relationships between features, leading to improved model accuracy and performance.
Normalization Techniques in Machine Learning
There are two widely used techniques for normalizing data in machine learning: Min-Max Scaling and Standardization Scaling. Each method has its advantages and limitations, making it important to choose the right one based on the specific use case.
1. Min-Max Scaling
Min-Max Scaling is one of the most common normalization techniques, where the data is rescaled to a specified range, often between 0 and 1. This method is simple and intuitive, making it ideal for algorithms sensitive to the range of data.
Mathematical Formula:
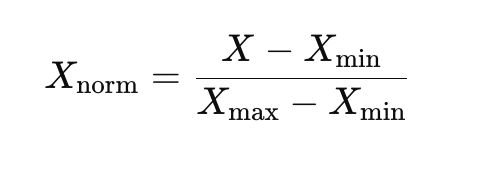
Where:
- Xnorm is the normalized value.
- X is the original value.
- Xmin and Xmax are the minimum and maximum values of the feature, respectively.
Advantages:
- Simple and easy to implement.
- Works well when you know the minimum and maximum values of the feature.
Limitations:
- Sensitive to outliers. A single outlier can significantly distort the scale.
Min-Max scaling is particularly useful when the data has a bounded range and when the model’s algorithm (like neural networks or distance-based algorithms) expects normalized inputs.
2. Standardization Scaling
Standardization (also known as Z-score normalization) transforms the data in such a way that the feature values have a mean of 0 and a standard deviation of 1. Unlike Min-Max Scaling, standardization does not bound the data to a specific range but focuses on the spread of data.
Mathematical Formula:
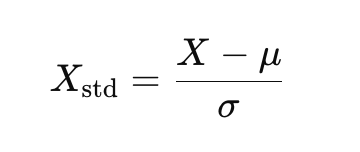
Where:
- Xstd is the standardized value.
- μ is the mean of the feature.
- σ is the standard deviation of the feature.
Advantages:
- Robust to outliers since it focuses on the distribution rather than the range.
- Suitable for algorithms that assume data is normally distributed, such as logistic regression or linear regression.
Limitations:
- It may not be suitable for cases where the data does not follow a normal distribution.
Standardization is beneficial when dealing with algorithms that require features to be normally distributed or centered around zero, such as Principal Component Analysis (PCA) or algorithms that involve gradient-based optimization.
Normalization vs. Standardization: What’s the Difference?
While both normalization and standardization are scaling techniques used to adjust the range of data, they serve distinct purposes and are applied in different contexts. Understanding the key differences between these two methods is essential for selecting the right technique based on the type of machine learning model you are working with.
1. Range
- Normalization: Scales data to a specified range, typically between 0 and 1, or sometimes -1 to 1, depending on the dataset.
- Standardization: Transforms data to have a mean of 0 and a standard deviation of 1, without necessarily bounding the data within a specific range.
Example: In normalization, the data values are directly adjusted to fall within a predetermined range, ensuring consistency in scale across different features. In contrast, standardization is concerned with how the data points spread out around the mean, resulting in values that could extend beyond any set range.
2. Outlier Sensitivity
- Normalization: More sensitive to outliers since extreme values can distort the scaling. An unusually high or low data point can disproportionately affect the entire feature’s scale.
- Standardization: Less affected by outliers because it focuses on the data’s mean and variance. While it may not eliminate the effect of outliers completely, it mitigates their impact compared to normalization.
Example: If your dataset contains an extreme outlier, normalization could significantly skew the results by stretching the data range. Standardization, on the other hand, will center the data, making outliers less impactful on the overall distribution.
3. Algorithm Suitability
- Normalization: Recommended for algorithms that rely on distance metrics, such as k-Nearest Neighbors (k-NN), k-means clustering, or neural networks, where feature scale can significantly affect performance.
- Standardization: Often preferred for algorithms like logistic regression, linear regression, and support vector machines (SVM), where having data centered around 0 with equal variance is advantageous.
Example: For models like k-NN that calculate distances between data points, normalization ensures that no feature disproportionately influences the distance calculation. On the other hand, regression models may perform better when data is standardized, allowing for more balanced parameter estimates.
When to Use Normalization and Standardization
Choosing between normalization and standardization depends on the type of machine learning algorithm you are using, the nature of your dataset, and the specific task at hand. Below are some key scenarios where each technique is recommended:
When to Use Normalization
- Distance-Based Algorithms: Algorithms like k-Nearest Neighbors (k-NN), k-means clustering, and Support Vector Machines (SVM) with RBF kernel rely heavily on the distance between data points. In these cases, it’s crucial that features are normalized to the same range to prevent features with larger scales from dominating the distance metrics.
- Example: When applying k-means clustering on a dataset where age is measured in years and income in dollars, income might overshadow age if not normalized, skewing the cluster assignments.
- Features with Different Scales: If your dataset contains features with vastly different units or scales, such as age, salary, or height, normalization ensures that each feature contributes equally to the model’s performance.
- Example: In a dataset where one feature represents age (in years) and another feature represents annual income (in thousands), normalizing both to a range of 0 to 1 will allow the algorithm to treat them comparably.
- Improving Model Convergence: For gradient-based algorithms like neural networks, normalization can sometimes speed up convergence during training by ensuring that features with larger magnitudes do not dominate the weight updates, leading to more stable training.
- Example: When training a deep learning model, normalized features help ensure that the weights are updated in a more uniform and consistent manner, improving the efficiency of backpropagation.
When to Use Standardization
- Algorithms Requiring Normal Distribution: Certain algorithms, such as logistic regression, linear regression, and Principal Component Analysis (PCA), assume that the input data follows a normal distribution (Gaussian distribution). Standardization helps by centering the data around 0 with a standard deviation of 1, which can improve model performance and interpretability.
- Example: In logistic regression, standardized features ensure that each feature contributes more equally to the model’s predictions, avoiding biased estimates due to feature scale differences.
- Dealing with Outliers: If your dataset contains outliers, standardization is often more robust than normalization, as it reduces the influence of extreme values by focusing on the mean and variance rather than the range of the data.
- Example: In a dataset where one feature has several extreme values (outliers), standardizing the data can limit the impact of these outliers on the model’s predictions.
- Data-Centric Algorithms: Algorithms like SVM (Support Vector Machines) and PCA work best when data is centered around zero with uniform variance. Standardization ensures that each feature is treated similarly, without certain features overshadowing others due to larger scales.
- Example: Standardizing the features in PCA ensures that all components contribute equally when computing principal components, improving dimensionality reduction and the model’s overall performance.
When Scaling May Not Be Necessary
- Already Normalized Data: If your data is already on a similar scale, for instance, probabilities ranging from 0 to 1, scaling may not be necessary, as the features are already suitable for use in most algorithms.
- Algorithms Insensitive to Feature Scaling: Some algorithms, like decision trees, random forests, and gradient boosting machines, are relatively insensitive to feature scaling, meaning that normalization or standardization may not provide any significant improvement in performance.
- Example: Decision trees create splits based on feature values rather than distance, so scaling the features generally doesn’t influence the final model accuracy.
Conclusion
In summary, both normalization and standardization serve to scale data, but the choice of which to use depends on the specific use case and the nature of your machine learning model. By understanding the strengths and weaknesses of each method, you can ensure that your model performs at its best.


