Big data analytics tools help organizations extract insights from massive datasets, guiding decisions that drive business growth. As traditional methods can’t handle the complexity or size of today’s data, these tools ensure efficient processing of structured and unstructured data.
From customer behavior predictions to operational improvements, choosing the right tool empowers businesses to stay competitive. In this article, we’ll explore 10 popular big data analytics tools, highlighting their features and how they support data-driven strategies.
List of Big Data Analytics Tools
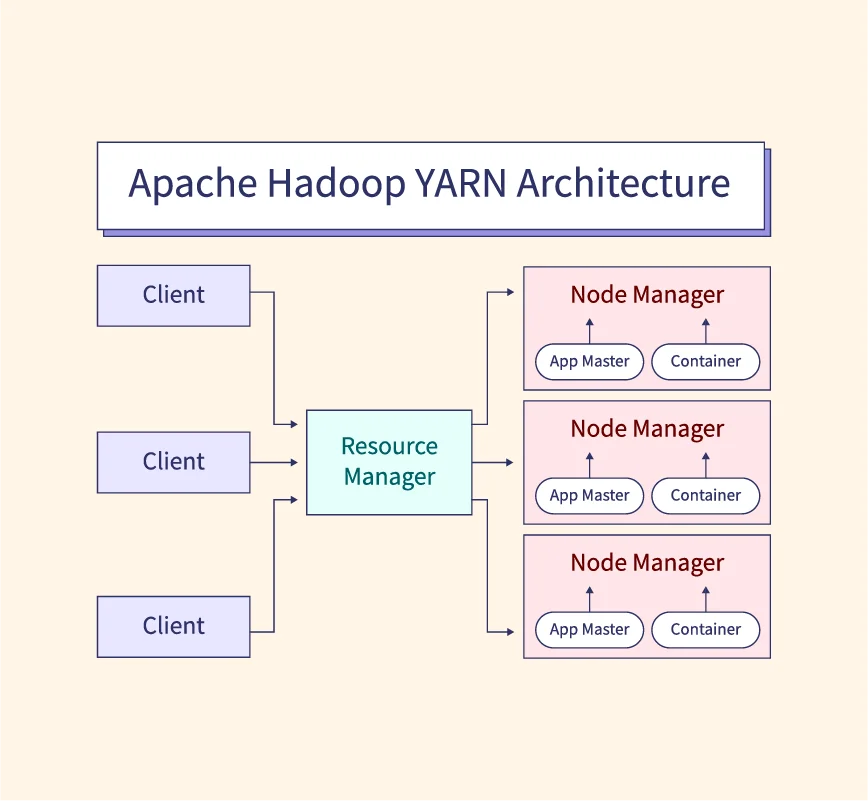
1. Apache Hadoop
Apache Hadoop is an open-source framework designed to process and store vast amounts of data across distributed systems. It excels at handling structured and unstructured data, making it ideal for big data applications.
- Key Features:
- Distributed storage and processing: Uses Hadoop Distributed File System (HDFS) to manage data across multiple nodes.
- Fault tolerance: Automatically replicates data across nodes to prevent data loss.
- Highly scalable: Can be expanded to thousands of nodes without performance loss.
- Ecosystem support: Works with tools like Hive, Pig, and Spark for advanced analytics.
- Benefits:
- Cost-efficient: Open-source and compatible with commodity hardware.
- Reliable data management: Ensures data availability even if a node fails.
- Flexible data processing: Handles multiple formats, including text, images, and videos.
- Widely adopted: Used across industries, ensuring a broad talent pool and community support.
2. Cassandra
Apache Cassandra is a highly scalable, distributed NoSQL database designed to handle large volumes of data across multiple data centers without downtime. It is ideal for high-availability applications where scalability and fault tolerance are critical.
- Key Features:
- Distributed architecture: Ensures high availability by replicating data across multiple nodes and locations.
- Linear scalability: Easily adds new nodes without interrupting operations.
- Fault-tolerant: Supports continuous uptime even during hardware failures.
- Flexible schema: Allows dynamic changes to the data structure without downtime.
- Benefits:
- High performance: Optimized for real-time analytics and transactional workloads.
- Always available: Ensures zero downtime, making it suitable for mission-critical systems.
- Multi-cloud compatibility: Works seamlessly across on-premises and cloud infrastructures.
- Open-source community: Active support with regular updates and new features.
3. Qubole
Qubole is a cloud-based data platform that simplifies big data management and analytics. It automates infrastructure management, enabling faster data processing and insights generation with minimal effort.
- Key Features:
- Auto-scaling clusters: Automatically adjusts computing resources based on workload.
- Multi-cloud support: Compatible with AWS, Azure, and Google Cloud.
- Data integration: Supports multiple data sources, including Hadoop, Spark, and Presto.
- Interactive analytics: Offers real-time insights with tools like SQL Workbench.
- Benefits:
- Cost savings: Optimizes cloud resource usage with auto-scaling.
- Faster time to insights: Reduces the complexity of managing big data workflows.
- User-friendly interface: Enables data teams to perform analytics without heavy coding.
- Seamless collaboration: Allows multiple teams to work on the same platform efficiently.
4. Xplenty
Xplenty is a cloud-based data integration platform that enables organizations to process, transform, and move data between various sources and destinations without the need for coding. It is especially suited for ETL (Extract, Transform, Load) operations.
- Key Features:
- No-code interface: Allows users to build data pipelines with a simple drag-and-drop interface.
- Pre-built connectors: Supports a wide range of data sources, including databases, CRMs, and cloud services.
- Scalable infrastructure: Easily handles both small and large-scale data loads.
- Scheduling and automation: Automates ETL processes for regular data updates.
- Benefits:
- Quick setup: Minimal coding required, enabling faster implementation.
- Seamless integration: Connects with multiple data sources and destinations.
- Flexible deployment: Works across cloud platforms like AWS, Google Cloud, and Azure.
- Improved productivity: Empowers non-technical users to manage data pipelines efficiently.
5. Apache Spark
Apache Spark is a powerful, open-source analytics engine designed for large-scale data processing. It provides lightning-fast cluster computing, making it ideal for both batch and real-time analytics.
- Key Features:
- In-memory computing: Stores intermediate data in memory, speeding up data processing.
- Support for multiple languages: Works with Python, Java, Scala, and R.
- Real-time stream processing: Processes data streams using Spark Streaming.
- Distributed computing: Handles large datasets across multiple nodes seamlessly.
- Benefits:
- High speed: Faster than Hadoop due to in-memory processing.
- Versatile analytics: Supports batch processing, machine learning, and graph computation.
- Scalable: Easily handles growing datasets and workloads.
- Broad ecosystem: Integrates with tools like Hadoop, Kafka, and HDFS for enhanced functionality.
6. MongoDB
MongoDB is a popular NoSQL database designed for handling large volumes of unstructured data. It stores data in a flexible, JSON-like format, making it highly scalable and suitable for modern applications.
- Key Features:
- Document-oriented storage: Stores data as BSON (Binary JSON) documents, supporting complex structures.
- Horizontal scalability: Shards data across multiple servers to maintain performance as data grows.
- Flexible schema: Allows dynamic data structures without predefined schemas.
- High availability: Uses replication to ensure data redundancy and prevent downtime.
- Benefits:
- Easy to use: Developers can quickly build and modify applications using MongoDB.
- Adaptable: Ideal for handling semi-structured or unstructured data, such as social media or IoT data.
- Cloud-ready: Seamlessly integrates with cloud platforms like AWS, Azure, and Google Cloud.
- Community and support: Strong community backing with comprehensive documentation and regular updates.
7. Apache Storm
Apache Storm is a real-time stream processing framework designed to handle massive streams of data. It excels at processing data in real time, making it ideal for applications that require immediate insights.
- Key Features:
- Real-time processing: Processes data streams instantly, enabling fast analytics.
- Distributed computing: Works across clusters to ensure scalability and fault tolerance.
- Fault tolerance: Automatically reassigns tasks in case of node failure.
- Multiple language support: Compatible with Java, Python, and other languages.
- Benefits:
- Fast and efficient: Handles millions of data points per second with low latency.
- Scalable architecture: Easily adapts to growing data and workloads.
- Reliable: Ensures continuous data processing even if parts of the system fail.
- Real-time insights: Used in industries like finance and e-commerce for live data analysis and monitoring.
8. SAS
SAS (Statistical Analysis System) is a powerful analytics platform widely used for data management, advanced analytics, and business intelligence. It is known for its ability to handle complex statistical operations and large datasets.
- Key Features:
- Advanced analytics: Supports statistical modeling, forecasting, and machine learning.
- Data integration: Combines data from multiple sources, including databases and spreadsheets.
- User-friendly interface: Offers a visual point-and-click interface along with coding capabilities.
- Scalable solutions: Handles large datasets for enterprise-level analytics.
- Benefits:
- Reliable and secure: Trusted by industries like banking and healthcare for critical data analysis.
- Comprehensive support: Offers extensive documentation and customer service.
- Versatile usage: Suitable for both technical users and non-programmers.
- Proven industry leader: Long history of delivering robust analytics solutions.
9. DataPine
DataPine is a business intelligence (BI) tool that simplifies data visualization and analytics. It allows users to create interactive dashboards and reports without needing advanced technical skills.
- Key Features:
- Drag-and-drop interface: Easily build dashboards and visualizations without coding.
- Real-time data analysis: Provides up-to-date insights with automated data refresh.
- Customizable reports: Tailors dashboards to fit individual business needs.
- Data integration: Connects with multiple databases, cloud services, and APIs.
- Benefits:
- User-friendly: Empowers non-technical users to analyze data independently.
- Faster insights: Reduces the time to generate business reports.
- Collaboration-ready: Enables teams to share reports and dashboards seamlessly.
- Improved decision-making: Provides actionable insights with interactive visuals.
10. RapidMiner
RapidMiner is a data science and machine learning platform that simplifies predictive analytics. It offers an end-to-end environment for building, deploying, and maintaining data models.
- Key Features:
- No-code and low-code options: Enables users to build models with minimal programming.
- Integrated machine learning workflows: Supports data preparation, modeling, and validation in a single platform.
- Extensive library of algorithms: Provides a wide range of machine learning techniques for various applications.
- Flexible deployment: Models can be deployed on-premises or in the cloud.
- Benefits:
- Easy to use: Ideal for both beginners and experienced data scientists.
- Accelerated model development: Reduces the time from data preparation to deployment.
- Collaboration features: Facilitates teamwork by sharing projects and workflows.
- Enterprise-ready: Trusted by businesses for advanced predictive analytics and real-time decision-making.
Conclusion
Big data analytics tools play a crucial role in helping businesses uncover patterns, make informed decisions, and stay competitive in today’s data-driven world. Tools like Apache Hadoop, Spark, and Cassandra provide robust data management capabilities, while platforms like DataPine and RapidMiner empower users with easy-to-use interfaces for analytics and machine learning.
Choosing the right tool depends on the specific business needs, data complexity, and infrastructure. As more companies adopt big data strategies, these tools will continue to evolve, making analytics more accessible and insightful for organizations across industries.