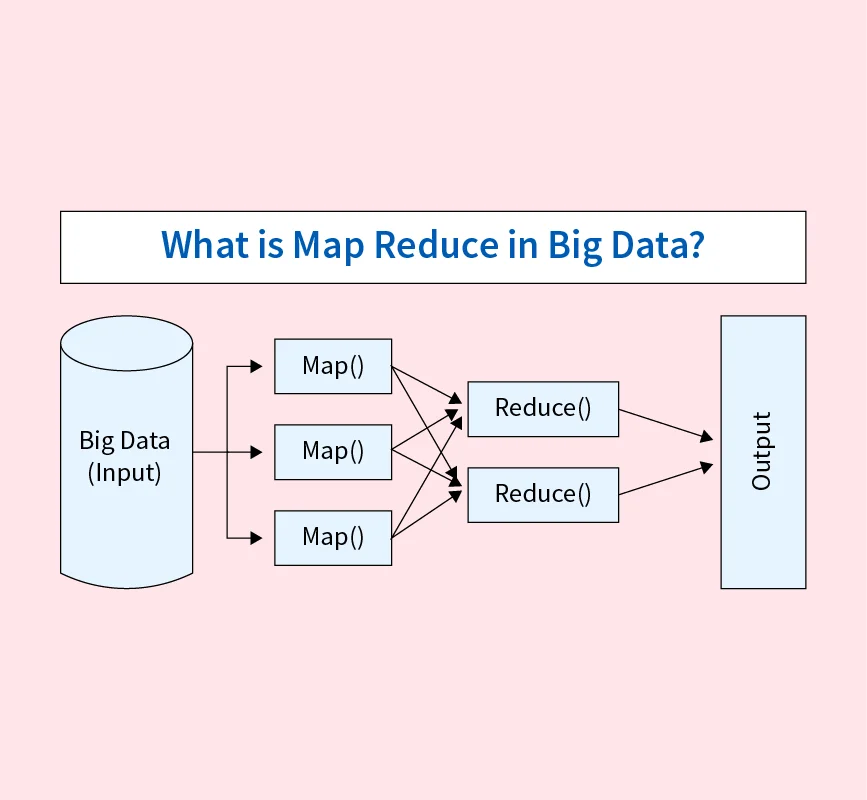
Machine learning (ML) is a branch of artificial intelligence that enables computers to learn from data, recognize patterns, and make predictions without being explicitly programmed. By using algorithms that improve through experience, machine learning has transformed industries, powering applications like fraud detection, recommendation systems, medical diagnosis, and autonomous vehicles.
The significance of machine learning lies in its ability to automate decision-making, enhance efficiency, and uncover insights from vast datasets. Businesses leverage ML to improve customer experience, optimize operations, and drive innovation. In healthcare, ML assists in predicting diseases and personalizing treatments, while in finance, it enhances risk assessment and fraud prevention.
A structured ML process is crucial for building accurate, reliable, and scalable models. The machine learning workflow involves multiple key steps, including data collection, preprocessing, model selection, training, evaluation, and deployment. By following a systematic approach, organizations can develop robust and efficient machine learning solutions that drive real-world impact.
Key Steps in the Machine Learning Process
The machine learning process involves a series of well-defined steps that transform raw data into a trained model capable of making accurate predictions. Each step plays a critical role in ensuring that the model is reliable, efficient, and generalizable to real-world applications.
1. Collecting Data
The foundation of any machine learning project is data. High-quality data is essential for training models that can make accurate predictions. The better the data, the more effective the model will be.
Machine learning models rely on different data types, including:
- Structured Data: Organized data stored in databases, spreadsheets, or CSV files (e.g., sales records, customer transactions).
- Unstructured Data: Raw data such as images, videos, and text (e.g., social media posts, scanned documents).
- Labeled Data: Data with predefined labels (e.g., email marked as spam or not spam).
- Unlabeled Data: Data without explicit labels, requiring unsupervised learning techniques (e.g., clustering).
Data can be sourced from multiple channels, including APIs, sensors, web scraping, surveys, and government repositories. Selecting relevant and diverse datasets is crucial to minimize bias and improve model generalization.
2. Preparing the Data
Raw data is often incomplete, inconsistent, or noisy, making data preprocessing a critical step. This phase ensures that the dataset is clean, structured, and suitable for analysis.
Key preprocessing steps include:
- Handling Missing Values: Using techniques like mean/median imputation or removing incomplete records.
- Removing Duplicates and Outliers: Identifying and eliminating data points that could skew the model.
- Feature Engineering: Creating new relevant features from existing data to improve model accuracy.
- Feature Selection: Choosing the most relevant features while removing redundant or irrelevant ones.
Proper data preparation significantly enhances model performance, reduces training time, and prevents errors.
3. Choosing the Right Model
Selecting the appropriate machine learning model depends on the nature of the problem and the type of data available.
Common machine learning models include:
- Regression Models (e.g., Linear Regression, Decision Trees): Used for predicting continuous values like stock prices.
- Classification Models (e.g., Logistic Regression, Support Vector Machines, Neural Networks): Used for categorical predictions, such as spam detection.
- Clustering Models (e.g., K-Means, DBSCAN, Gaussian Mixture Models): Used for grouping similar data points in an unsupervised manner.
Factors to consider when selecting a model:
- Size and quality of the dataset
- Computational complexity
- Interpretability vs. performance trade-offs
- Handling of missing data and categorical variables
Choosing the right model is crucial for achieving high accuracy while maintaining efficiency.
4. Training the Model
Once the model is selected, it must be trained using historical data. The dataset is typically split into training and validation sets to assess performance.
Key concepts in training:
- Supervised Learning: Training the model on labeled data with known outputs (e.g., spam detection).
- Unsupervised Learning: Discovering patterns in unlabeled data (e.g., customer segmentation).
- Semi-Supervised Learning: A combination of both, where a small portion of labeled data assists in learning.
Proper training ensures the model learns the underlying patterns while avoiding memorization of the training data.
5. Evaluating the Model
Evaluating the model’s performance is essential to ensure accuracy and reliability before deployment. Several performance metrics help assess how well the model generalizes to unseen data.
Common evaluation metrics include:
- Accuracy: The percentage of correct predictions (best for balanced datasets).
- Precision & Recall: Precision measures correctness among positive predictions, while recall assesses how well positive cases are identified.
- F1-Score: The harmonic mean of precision and recall, balancing both metrics.
- RMSE (Root Mean Square Error): Commonly used in regression models to measure prediction errors.
Additionally, cross-validation techniques like K-Fold Cross-Validation help validate model performance by training and testing the model on different subsets of data.
6. Hyperparameter Tuning
Hyperparameters are model settings that control learning behavior and directly impact performance. Tuning these parameters ensures optimal model accuracy and efficiency.
Popular hyperparameter tuning techniques:
- Grid Search: Systematically tests different parameter combinations.
- Random Search: Randomly selects parameter combinations for quicker optimization.
- Bayesian Optimization: Uses probability-based techniques to refine hyperparameters.
Another challenge is avoiding overfitting and underfitting:
- Overfitting: The model learns noise instead of patterns, performing well on training data but poorly on unseen data. Solutions include regularization (L1/L2), dropout techniques, and data augmentation.
- Underfitting: The model is too simple and fails to capture complex patterns. Solutions involve using a more complex model, adding more features, or reducing bias.
Proper hyperparameter tuning ensures that the model generalizes well across diverse datasets.
7. Making Predictions and Deploying the Model
Once a machine learning model has been trained and optimized, it is ready for real-world use. The final step involves deploying the model in a production environment where it can make predictions on new data.
Key deployment strategies include:
- Batch Processing: Running predictions on stored datasets at scheduled intervals.
- Real-Time Processing: Using APIs to provide instant predictions for applications like chatbots and recommendation engines.
- Edge Computing: Deploying models on edge devices like smartphones or IoT devices for low-latency applications.
- Cloud Deployment: Hosting models on cloud services like AWS, Google Cloud, or Microsoft Azure, ensuring scalability and accessibility.
Maintaining and updating the model post-deployment is crucial. Retraining on new data, monitoring performance, and addressing drift in model accuracy are essential practices to ensure long-term reliability.
Implementing Machine Learning Steps in Python
Implementing machine learning in Python involves multiple steps, including data preprocessing, model training, and evaluation. Popular libraries like Pandas, Scikit-learn, and NumPy simplify this process. Below are Python code examples for key steps in the machine learning workflow.
Data Preprocessing Using Pandas
Before training a model, data must be cleaned and structured properly.
import pandas as pd
from sklearn.model_selection import train_test_split
# Load dataset
data = pd.read_csv("data.csv")
# Handling missing values
data.fillna(data.mean(), inplace=True)
# Converting categorical variables to numerical values
data = pd.get_dummies(data, drop_first=True)
# Splitting dataset into features (X) and target variable (y)
X = data.drop("target", axis=1)
y = data["target"]
# Splitting into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)Training a Model Using Scikit-learn
from sklearn.ensemble import RandomForestClassifier
# Initialize model
model = RandomForestClassifier(n_estimators=100, random_state=42)
# Train the model
model.fit(X_train, y_train)Evaluating the Model Using Performance Metrics
from sklearn.metrics import accuracy_score, classification_report
# Make predictions
y_pred = model.predict(X_test)
# Calculate accuracy
accuracy = accuracy_score(y_test, y_pred)
print(f"Model Accuracy: {accuracy:.2f}")
# Generate classification report
print(classification_report(y_test, y_pred))By following these steps, machine learning models can be developed, trained, and evaluated efficiently in Python.
Conclusion
The machine learning process follows a structured approach that includes data collection, preprocessing, model selection, training, evaluation, and deployment. Each step is essential in ensuring that the model is accurate, scalable, and reliable for real-world applications. From handling raw data to fine-tuning model hyperparameters, a systematic workflow improves efficiency and decision-making across various industries.
One of the most critical aspects of machine learning is iterative model improvement. As new data becomes available, models must be continuously retrained and optimized to maintain accuracy and relevance. Techniques like cross-validation, hyperparameter tuning, and model monitoring help improve performance over time.
To master machine learning, hands-on practice is key. Experimenting with datasets, implementing models in Python using Scikit-learn and TensorFlow, and working on real-world projects enhance understanding and technical skills. By consistently refining models and exploring new AI advancements, machine learning practitioners can drive innovation in AI-powered solutions.
References: