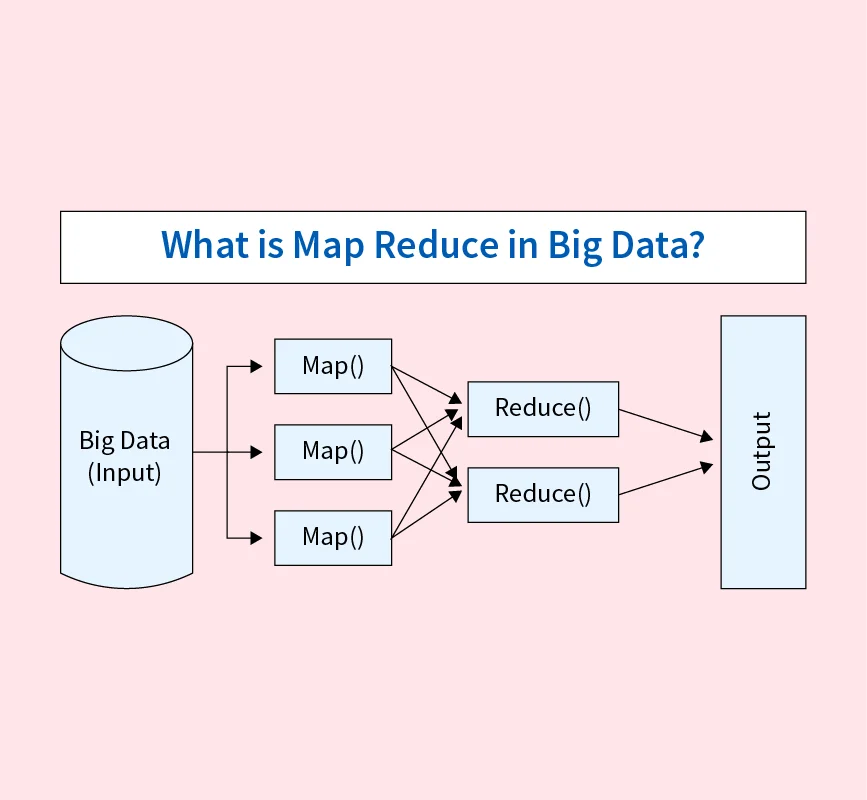
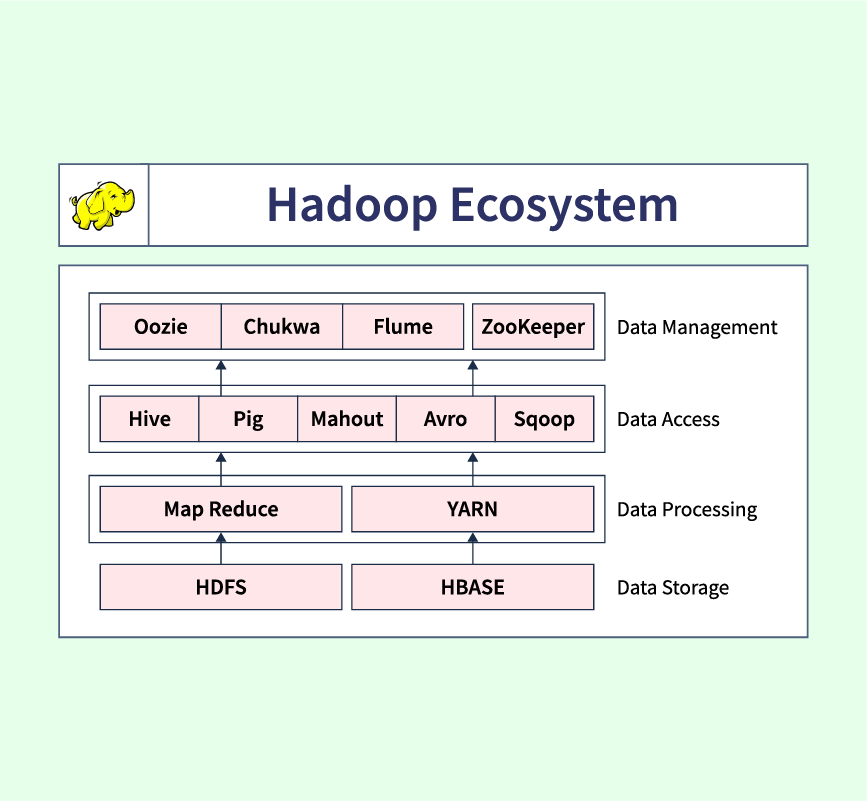
Preparing for a machine learning interview can be challenging, especially for those new to the field. To help you succeed, this guide covers over 100 machine learning interview questions, categorized by experience level: Beginner, Intermediate, and Advanced. Whether you’re starting your journey or advancing your career, these questions provide a solid foundation across various machine learning topics. We’ll explore key concepts like algorithms, evaluation metrics, model tuning techniques, and advanced frameworks, ensuring you’re well-prepared for any machine learning role.
Beginner Level Machine Learning Interview Questions
These questions focus on fundamental concepts, basic algorithms, and essential techniques suitable for entry-level candidates. They form the foundation for understanding machine learning and are crucial for acing beginner-level interviews.
1. What is Machine Learning, and how is it different from traditional programming?
- Machine Learning (ML) is a field of computer science where algorithms are designed to learn from data and make predictions or decisions without being explicitly programmed for each task. Unlike traditional programming, where rules and logic are explicitly coded, ML models identify patterns from data and adapt their behavior accordingly.
2. What are the different types of Machine Learning?
- The three main types of ML are:
- Supervised Learning: The model is trained using labeled data (data with known outcomes) to make predictions.
- Unsupervised Learning: The model learns patterns from unlabeled data (data without outcomes) to group or cluster information.
- Reinforcement Learning: The model learns by interacting with an environment and receiving feedback in the form of rewards or penalties.
3. Explain the concepts of a training set, validation set, and test set.
- These are subsets of data used to train and evaluate a machine learning model:
- Training Set: The data used to train the model.
- Validation Set: Data used to fine-tune the model’s hyperparameters.
- Test Set: A separate dataset used to evaluate the final model’s performance.
4. What is the difference between classification and regression?
- Classification is when the output is a category (e.g., spam or not spam). Regression is when the output is a continuous value (e.g., predicting the price of a house).
5. What is logistic regression?
- Logistic regression is a classification algorithm used to predict binary outcomes (e.g., 0 or 1). It uses a logistic function (sigmoid function) to model the probability of an event occurring.
6. Explain overfitting and underfitting.
- Overfitting occurs when a model learns too much detail from the training data, leading to poor performance on new data. Underfitting happens when the model is too simple and fails to capture the underlying patterns in the data.
7. How do you handle missing or corrupted data in a dataset?
- Some common methods include:
- Removing rows with missing values.
- Imputing missing values using mean, median, or mode.
- Using algorithms that can handle missing data directly.
8. What is feature engineering, and why is it important?
- Feature engineering involves creating new features or modifying existing ones to improve a model’s performance. It’s crucial because well-engineered features help the model understand patterns better, leading to more accurate predictions.
9. Explain data normalization and standardization.
- Normalization scales data to a range of [0, 1], while standardization scales data to have a mean of 0 and a standard deviation of 1. These techniques help models converge faster and perform better.
10. What is supervised learning?
- In supervised learning, the model learns from labeled data (input-output pairs) to predict outcomes for new, unseen data. Examples include regression and classification tasks.
11. What is a decision tree, and how does it work?
- A decision tree is a flowchart-like structure used for classification and regression tasks. It splits the dataset into branches based on features, with each node representing a decision point. The model makes predictions by following the path of decisions from the root node to a leaf node.
12. Explain the K-Nearest Neighbors (KNN) algorithm.
- KNN is a simple classification algorithm that predicts the category of a data point based on the categories of its ‘k’ nearest neighbors. It calculates the distance (e.g., Euclidean) between data points and assigns the majority class among the closest neighbors.
13. What is the Naive Bayes classifier, and why is it called ‘naive’?
- The Naive Bayes classifier is based on Bayes’ Theorem, assuming that all features are independent of each other (which is often not true in real-life data). It’s called ‘naive’ because of this assumption of independence. It’s widely used for tasks like spam detection.
14. What is a recommendation system, and how does it work?
- A recommendation system suggests products or content based on user behavior and preferences. It uses techniques like collaborative filtering (suggesting items similar to those liked by similar users) and content-based filtering (suggesting items similar to what the user has interacted with before).
15. What is deep learning?
- Deep learning is a subset of machine learning that uses neural networks with many layers (deep neural networks) to model complex patterns in data. It’s commonly used for tasks like image and speech recognition.
16. What are some real-life applications of supervised learning?
- Some examples include:
- Spam detection: Identifying if an email is spam or not.
- Fraud detection: Flagging suspicious transactions in banking.
- Medical diagnosis: Classifying diseases based on medical records.
17. Explain the clustering algorithm.
- Clustering algorithms group data points based on their similarities. An example is the K-means algorithm, which partitions the data into ‘k’ clusters where each point belongs to the cluster with the nearest mean.
18. What is the confusion matrix, and how is it used?
- A confusion matrix is a table used to evaluate the performance of a classification model. It shows the true positives, true negatives, false positives, and false negatives, helping calculate metrics like accuracy, precision, and recall.
19. Define precision, recall, and F1 score.
- Precision: The ratio of correctly predicted positive observations to the total predicted positives.
- Recall: The ratio of correctly predicted positive observations to all actual positives.
- F1 Score: The harmonic mean of precision and recall, balancing the two.
20. What is the difference between accuracy and precision?
- Accuracy measures the overall correctness of predictions (both positive and negative), while precision focuses on the correctness of positive predictions.
21. What is the ROC-AUC curve?
- The ROC (Receiver Operating Characteristic) curve shows the true positive rate (sensitivity) versus the false positive rate. The AUC (Area Under the Curve) measures the overall performance; a higher AUC indicates a better model.
22. Explain the concept of Type I and Type II errors.
- A Type I error (false positive) occurs when the model incorrectly predicts a positive outcome, while a Type II error (false negative) occurs when it misses a positive outcome.
23. What is cross-validation, and why is it important?
- Cross-validation involves splitting the data into multiple parts to train and test the model multiple times, ensuring it generalizes well. It helps to prevent overfitting and provides a better evaluation of the model’s performance.
24. What is data preprocessing, and why is it necessary?
- Data preprocessing involves cleaning and preparing raw data before feeding it into a model. This step includes handling missing values, scaling features, and encoding categorical variables, ensuring that the model works effectively with the data.
25. How do you handle imbalanced datasets?
- Techniques to handle imbalanced datasets include:
- Resampling: Oversampling the minority class or undersampling the majority class.
- Using algorithms like SMOTE: Synthetic Minority Over-sampling Technique to create synthetic samples.
- Adjusting model metrics: Focusing on precision, recall, or using the F1 score.
26. What is dimensionality reduction?
- Dimensionality reduction reduces the number of features (dimensions) in a dataset to simplify the model and remove noise. It helps in improving model performance and visualization.
27. Explain Principal Component Analysis (PCA).
- PCA is a dimensionality reduction technique that transforms the original features into a new set of uncorrelated features called principal components. It captures the maximum variance in the data while reducing the number of dimensions.
28. What is feature scaling?
- Feature scaling standardizes or normalizes the range of features so they have similar scales. It is essential for algorithms like KNN and SVM that depend on distance calculations.
29. What is one-hot encoding?
- One-hot encoding converts categorical variables into binary vectors. For example, if a column contains values like “Red,” “Green,” and “Blue,” it creates separate columns for each value (e.g., “Red: 1/0,” “Green: 1/0,” “Blue: 1/0”).
30. What is a hypothesis in machine learning?
- A hypothesis is an assumption made by a model about the relationship between input features and the output. Models use training data to test and refine this hypothesis to make accurate predictions.
31. Explain the difference between covariance and correlation.
- Covariance measures the direction of the relationship between two variables, while correlation measures both the direction and strength of the relationship, with values ranging from -1 to 1.
32. How is feature selection done in machine learning?
- Feature selection involves choosing relevant features for the model to reduce complexity and enhance performance. Techniques include:
- Filter methods: Correlation-based filtering.
- Wrapper methods: Using algorithms like Recursive Feature Elimination (RFE).
- Embedded methods: Features selected during the model training process (e.g., LASSO).
33. What is overfitting, and how can it be avoided?
- Overfitting occurs when the model performs well on training data but poorly on new data. To avoid it:
- Use cross-validation.
- Apply regularization techniques.
- Simplify the model or reduce the number of features.
34. What is underfitting, and how can it be identified?
- Underfitting happens when the model is too simple and fails to capture patterns in the data. It can be identified when both the training and test errors are high. Increasing model complexity or adding more features may help.
35. How do you evaluate a machine learning model?
- Common evaluation methods include:
- Accuracy, precision, recall, and F1 score for classification models.
- Mean Squared Error (MSE) for regression models.
- Cross-validation to assess the generalizability of the model.
Intermediate Level Machine Learning Interview Questions
This section covers more in-depth topics like model optimization, performance metrics, and a variety of algorithms and their applications. These questions are suitable for those with some experience in machine learning, aiming to expand their knowledge beyond the basics.
36. What is the bias-variance tradeoff?
- The bias-variance tradeoff is a balance between two types of errors:
- Bias: Error due to overly simplistic assumptions in the model.
- Variance: Error due to the model being too complex and sensitive to small fluctuations in the training data.
- The goal is to find a model that minimizes both, ensuring it performs well on both training and unseen data.
37. What are hyperparameters, and how do you tune them?
- Hyperparameters are settings used to control the learning process (e.g., learning rate, number of trees in a random forest). They are different from parameters, which are learned during training. Hyperparameter tuning involves finding the best combination using methods like grid search or random search.
38. Explain grid search and random search for hyperparameter tuning.
- Grid Search tests all possible combinations of hyperparameters within a predefined range, while Random Search tests a random set of combinations. Random search is faster and can be more efficient when the search space is large.
39. What is gradient descent, and how does it work?
- Gradient Descent is an optimization algorithm used to minimize a model’s cost function. It updates model parameters by moving in the direction that reduces the error, based on the gradient (slope) of the cost function.
40. What is stochastic gradient descent?
- Stochastic Gradient Descent (SGD) is a variant of gradient descent where the model updates parameters using a single or a small batch of data points, instead of the whole dataset. It speeds up the optimization process but may lead to more fluctuations in the parameter updates.
41. Explain mini-batch gradient descent.
- Mini-batch gradient descent combines the benefits of both standard and stochastic gradient descent. It updates the model parameters using a small batch of data points, balancing the stability of full-batch gradient descent and the speed of SGD.
42. What is regularization, and why is it used?
- Regularization adds a penalty to the model’s cost function to discourage overly complex models (e.g., with too many parameters), helping to prevent overfitting. Examples include L1 (Lasso) and L2 (Ridge) regularization.
43. What is the difference between L1 and L2 regularization?
- L1 Regularization (Lasso) adds the absolute value of the weights as a penalty, leading to sparse models where some coefficients become zero.
- L2 Regularization (Ridge) adds the squared value of the weights, shrinking them but not setting them to zero, which helps reduce overfitting while maintaining complexity.
44. What is a cost function?
- A cost function measures the difference between the model’s predictions and the actual values. It guides the optimization process, aiming to minimize this difference (error) during training.
45. Explain the concept of early stopping.
- Early stopping is a technique used to prevent overfitting. During training, the model’s performance on the validation set is monitored. Training stops when performance stops improving, ensuring the model doesn’t become overly complex.
46. Compare K-means and KNN algorithms.
- K-means is an unsupervised clustering algorithm that partitions data into ‘k’ clusters based on similarity.
- KNN (K-Nearest Neighbors) is a supervised classification algorithm that predicts a data point’s class based on the classes of its ‘k’ nearest neighbors.
47. What is a support vector machine (SVM)?
- SVM is a classification algorithm that finds the optimal hyperplane to separate data points into different categories. It maximizes the margin between the data points of different classes.
48. Explain the concept of kernel SVM.
- Kernel SVM uses kernel functions to transform data into a higher-dimensional space, allowing it to separate non-linearly separable data by finding an optimal hyperplane in that space.
49. How does the random forest algorithm work?
- Random Forest is an ensemble method that builds multiple decision trees and combines their results to improve accuracy. It selects random features and data subsets for each tree, reducing overfitting and increasing model robustness.
50. What is the difference between decision trees and random forests?
- A decision tree is a single tree that makes predictions based on a set of rules derived from the features, while a random forest is a collection of multiple decision trees that vote on the final prediction, leading to better accuracy and reduced overfitting.
51. Explain ensemble learning
- Ensemble learning combines the predictions of multiple models (e.g., decision trees, neural networks) to improve accuracy and robustness. Common techniques include bagging, boosting, and stacking.
52. What is boosting in machine learning?
- Boosting is an ensemble technique that combines multiple weak learners (e.g., shallow decision trees) to create a strong model. Each learner tries to correct the mistakes of the previous one, gradually improving overall accuracy.
53. What is bagging in machine learning?
- Bagging (Bootstrap Aggregating) is an ensemble technique that trains multiple models on different subsets of the training data. The models’ predictions are then averaged (for regression) or voted (for classification) to make the final prediction.
54. What is a neural network?
- A neural network is a series of interconnected nodes (neurons) organized in layers. It is designed to mimic the human brain and is used for tasks like image recognition, speech processing, and language translation.
55. What is data augmentation, and why is it important in deep learning?
- Data augmentation involves creating new training examples by modifying existing data (e.g., rotating or flipping images). It increases the diversity of the training data, helping the model generalize better and reducing overfitting.
56. Explain SMOTE and its role in handling imbalanced datasets.
- SMOTE (Synthetic Minority Over-sampling Technique) is a method that generates synthetic examples for the minority class to balance the dataset, improving the model’s ability to learn from minority examples.
57. What is dimensionality reduction using t-SNE?
- t-SNE (t-distributed Stochastic Neighbor Embedding) is a technique used to reduce high-dimensional data into two or three dimensions for visualization. It preserves the local structure of the data, making it useful for exploring patterns in complex datasets.
58. What is the Central Limit Theorem, and how is it applied in machine learning?
- The Central Limit Theorem states that the distribution of sample means approximates a normal distribution as the sample size increases, regardless of the population’s distribution. It is used in machine learning for statistical analysis and hypothesis testing.
59. How do you handle multicollinearity in a dataset?
- Multicollinearity occurs when features are highly correlated. It can be handled by:
- Removing correlated features or
- Applying dimensionality reduction techniques like PCA to create uncorrelated components.
60. What is feature selection using mutual information?
- Mutual information measures the dependency between two variables. Features with high mutual information with the target variable are selected for the model, ensuring they provide valuable information for predictions.
61. What is the difference between Mean Squared Error (MSE) and Root Mean Squared Error (RMSE)?
- MSE measures the average squared difference between predicted and actual values. It emphasizes larger errors due to squaring.
- RMSE is the square root of MSE, providing a measure in the same units as the predicted variable, making it easier to interpret.
62. Explain Mean Absolute Error (MAE) and its use.
- MAE calculates the average absolute difference between predicted and actual values. It provides a straightforward way to measure model accuracy without squaring the errors, making it less sensitive to outliers compared to MSE.
63. What is the F1 score, and how is it calculated?
- The F1 score is the harmonic mean of precision and recall, providing a balanced measure, especially when dealing with imbalanced datasets. It is calculated as: F1=2×Precision×RecallPrecision+RecallF1 = 2 \times \frac{{\text{{Precision}} \times \text{{Recall}}}}{{\text{{Precision}} + \text{{Recall}}}}F1=2×Precision+RecallPrecision×Recall
64. How do you choose the right evaluation metric for your model?
- The choice of evaluation metric depends on the problem type:
- Classification: Accuracy, precision, recall, F1 score, and ROC-AUC.
- Regression: MSE, RMSE, MAE, and R-squared.
- Imbalanced data: Metrics like F1 score or precision-recall curve are preferred over accuracy.
65. What is the Matthews correlation coefficient (MCC)?
- MCC is a metric used for evaluating binary classification models. It considers all four outcomes (true positives, true negatives, false positives, false negatives) and provides a value between -1 and +1. A value of +1 indicates perfect prediction, 0 indicates random prediction, and -1 indicates total disagreement.
66. Explain how a recommendation engine works.
- A recommendation engine suggests products or content based on user behavior and preferences. It uses techniques such as:
- Collaborative filtering: Finds similarities between users or items based on past behavior.
- Content-based filtering: Recommends items similar to those a user has liked in the past.
67. How do you design an email spam filter using machine learning?
- To design an email spam filter:
- Collect labeled email data (spam and not spam).
- Extract features like word frequencies, presence of certain keywords, and metadata.
- Train a classification model (e.g., Naive Bayes or SVM) using the labeled dataset.
- Evaluate the model using metrics like accuracy, precision, and recall.
68. Explain the concept of reinforcement learning with an example.
- Reinforcement learning involves training an agent to make decisions by rewarding or penalizing actions. For example, in a game environment, the agent receives a reward for reaching the goal and a penalty for hitting obstacles. Over time, it learns to optimize its actions for the best outcomes.
69. How does transfer learning work in neural networks?
- Transfer learning involves taking a pre-trained model (e.g., a model trained on a large image dataset) and fine-tuning it on a new, related task. It allows models to learn quickly with less data, as they leverage the knowledge from previous tasks.
70. What is semi-supervised learning?
- Semi-supervised learning uses a small amount of labeled data combined with a large amount of unlabeled data. The model initially learns from the labeled data and then refines its learning using the unlabeled data, making it a cost-effective approach when labeled data is scarce.
Advanced Level Machine Learning Interview Questions
These questions dive into complex machine learning concepts, model tuning techniques, deep learning frameworks, and advanced algorithms suitable for senior-level candidates. These questions test your deep understanding of machine learning and its applications.
71. Explain the SVM algorithm in detail.
- Support Vector Machine (SVM) is a powerful classification algorithm that finds the optimal hyperplane to separate data points of different classes. It maximizes the margin between the nearest points of each class (support vectors). SVMs can also be extended to non-linearly separable data using kernel functions.
72. What is the difference between Lasso and Ridge regression?
- Both are regularization techniques:
- Lasso (L1) Regression: Shrinks some coefficients to zero, leading to feature selection and a simpler model.
- Ridge (L2) Regression: Shrinks coefficients but never to zero, making it better for models with many correlated features.
73. Explain the working of a neural network.
- A neural network consists of layers of nodes (neurons) that process inputs and pass them through activation functions. The network learns by adjusting weights during backpropagation, which minimizes the error in the output. It’s widely used for image and speech recognition, among other applications.
74. What is a convolutional neural network (CNN)?
- CNNs are specialized neural networks designed for image processing. They use convolutional layers to scan images, identifying patterns like edges or textures. These layers help extract features efficiently, making CNNs suitable for tasks like object detection and image classification.
75. What is a recurrent neural network (RNN)?
- RNNs are neural networks designed for sequential data (e.g., time series, text). They have loops that allow information to persist, making them ideal for tasks like language modeling and time series prediction.
76. Explain the concept of long short-term memory (LSTM).
- LSTM is a type of RNN that solves the problem of long-term dependencies. It uses gates to control the flow of information, allowing it to remember or forget specific information over long sequences. It’s widely used in natural language processing (NLP) and time series analysis.
77. What is reinforcement learning, and how is it different from other types of learning?
- Reinforcement learning (RL) involves training an agent to make decisions in an environment based on rewards and penalties. Unlike supervised and unsupervised learning, RL focuses on learning sequences of actions that maximize cumulative rewards.
78. What is the Bellman equation in reinforcement learning?
- The Bellman equation describes the relationship between the value of a state and the values of its successor states. It’s a fundamental concept in dynamic programming and RL, helping to determine the optimal policy for maximizing rewards.
79. Explain Q-learning and its application.
- Q-learning is a reinforcement learning algorithm that finds the optimal action-selection policy for an agent. It uses a Q-table to store the expected rewards for actions in each state. It’s applied in scenarios like robotics, game AI, and self-driving cars.
80. What is Bayesian optimization?
- Bayesian optimization is a technique used for optimizing expensive-to-evaluate functions, such as hyperparameter tuning in machine learning models. It builds a probabilistic model to predict the performance of different configurations, helping find the optimal solution faster.
81. How do you prevent model drift?
- Model drift occurs when the data the model sees changes over time, causing performance degradation. To prevent it:
- Monitor model performance over time.
- Retrain the model periodically with updated data.
- Use drift detection algorithms to trigger retraining when drift is detected.
82. What are the key differences between batch learning and online learning?
- Batch Learning: The model is trained on the entire dataset at once, suitable for static data.
- Online Learning: The model updates continuously as new data arrives, making it suitable for dynamic environments.
83. What is model interpretability, and why is it important?
- Model interpretability refers to the ability to understand and explain the decisions made by a model. It is crucial for trust, accountability, and compliance, especially in sensitive applications like healthcare and finance.
84. Explain the difference between inductive and deductive machine learning.
- Inductive learning creates generalized rules from specific examples (e.g., learning patterns from data).
- Deductive learning starts with known rules and applies them to specific cases (e.g., applying a learned rule to make a prediction).
85. What is backpropagation, and how does it work in neural networks?
- Backpropagation is a method used to train neural networks. It calculates the gradient of the loss function with respect to each weight by propagating the error backward through the network. The weights are then adjusted to minimize the error.
86. What is a generative adversarial network (GAN)?
- A GAN consists of two neural networks (a generator and a discriminator) competing against each other. The generator creates fake data, while the discriminator tries to distinguish between real and fake data. This competition improves both models, resulting in realistic outputs.
87. Explain the concept of autoencoders.
- Autoencoders are neural networks used for dimensionality reduction. They learn to compress data into a lower-dimensional representation and then reconstruct it back, minimizing the loss. They are widely used for anomaly detection and image compression.
88. What are activation functions, and why are they important?
- Activation functions determine the output of a neuron, introducing non-linearity to the network. They are crucial for the network to learn complex patterns. Examples include the sigmoid, ReLU, and tanh functions.
89. What is the difference between the sigmoid and softmax activation functions?
- Sigmoid produces an output between 0 and 1, making it suitable for binary classification.
- Softmax outputs a probability distribution across multiple classes, making it suitable for multi-class classification.
90. What is the ROC curve, and how is it used to evaluate models?
- The ROC (Receiver Operating Characteristic) curve plots the true positive rate against the false positive rate. It helps evaluate a classification model’s performance, with the area under the curve (AUC) indicating overall model accuracy.
91. Explain the concept of the Gini index in decision trees.
- The Gini index measures the impurity of a node in a decision tree. A lower Gini index indicates a better split of the data, as the classes are more homogeneous. It helps the algorithm choose the best feature to split on.
92. How do you handle overfitting in deep learning models?
- To handle overfitting:
- Use dropout: Randomly drop neurons during training.
- Apply regularization: Techniques like L1/L2 regularization.
- Add more data or use data augmentation.
93. What is dropout in neural networks?
- Dropout is a regularization technique where random neurons are deactivated during training. It prevents the model from becoming too dependent on specific neurons, promoting generalization.
94. What is explainable AI (XAI)?
- XAI refers to methods and techniques that make AI models transparent and interpretable, enabling users to understand how and why a model makes decisions. It is essential for gaining trust and ensuring ethical AI use.
95. Explain the concept of model fairness.
- Model fairness involves ensuring that the AI system’s predictions are unbiased and fair across different groups or demographics. Techniques include adjusting training data or applying fairness constraints during model development.
96. What is a quantum machine learning model?
- Quantum machine learning combines quantum computing and ML techniques to accelerate computations. It leverages quantum bits (qubits) and quantum algorithms to perform tasks faster than classical computers, potentially transforming fields like optimization and cryptography.
97. What is the role of reinforcement learning in robotics?
- Reinforcement learning enables robots to learn tasks by interacting with their environment. It allows robots to make decisions and improve performance over time through trial and error, adapting to dynamic and complex environments.
98. Explain few-shot learning.
- Few-shot learning is a method where a model learns to make predictions with only a few examples. It is particularly useful when labeled data is scarce, as the model generalizes from a small dataset.
99. What is zero-shot learning?
- Zero-shot learning allows models to recognize new classes they haven’t seen before, using knowledge from related classes. It’s beneficial in applications where labeling data for every possible class is impractical.
100. How does meta-learning differ from traditional learning?
Meta-learning, or “learning to learn,” focuses on training models that can quickly adapt to new tasks with minimal data. Traditional learning, on the other hand, requires large amounts of data for each task. Meta-learning is particularly useful in scenarios where rapid adaptation is crucial.
101. How would you implement a sentiment analysis model?
To implement a sentiment analysis model:
- Collect and preprocess text data (e.g., tokenization, stopword removal).
- Train a model (e.g., Naive Bayes, LSTM) using labeled sentiment data.
- Evaluate using metrics like accuracy, precision, and recall.
102. Describe how you would optimize a model for time series forecasting.
For time series forecasting:
- Choose a model suitable for sequential data (e.g., ARIMA, LSTM).
- Split data into training, validation, and test sets, ensuring time-based splits.
- Tune hyperparameters like window size and learning rate using cross-validation.
103. What is federated learning, and how does it work?
Federated learning trains models across multiple devices or servers without sharing raw data. Each device trains a local model, and only the model updates are sent back to a central server for aggregation. This approach improves privacy and security.
104. Explain the difference between content-based and collaborative filtering.
Content-based filtering: Recommends items based on their similarity to items the user has interacted with before.
Collaborative filtering: Recommends items based on the preferences of similar users.
105. How would you design a self-driving car’s AI system using reinforcement learning?
Designing an AI system for a self-driving car involves:
- Creating a simulation environment for training.
- Defining rewards for safe and efficient driving behaviors.
- Using reinforcement learning algorithms (e.g., Q-learning or deep Q-networks) to optimize decision-making.