Neural networks have revolutionized sequence modeling by enabling efficient processing of sequential data. Among these, Long Short-Term Memory (LSTM) networks stand out for their ability to handle long-term dependencies and avoid vanishing gradient issues. LSTMs are pivotal in applications like speech recognition, language translation, and time-series forecasting.
What is LSTM?
Long Short-Term Memory (LSTM) is a specialized type of recurrent neural network (RNN) designed to effectively learn and retain long-term dependencies in sequential data. Traditional RNNs struggle with vanishing and exploding gradient problems, which hinder their ability to capture relationships over extended sequences. LSTM overcomes this limitation by introducing a unique memory cell structure that selectively retains or forgets information as needed.
The core innovation of LSTM lies in its gating mechanisms: the forget gate, input gate, and output gate. These gates regulate the flow of information, enabling the network to focus on relevant data while discarding unnecessary details. This architecture makes LSTM particularly effective for tasks requiring context over long sequences, such as language modeling, time-series prediction, and video analysis.
By mitigating gradient-related challenges, LSTM ensures stable learning even in deep networks. This capability has made it a cornerstone in applications like speech recognition, machine translation, and anomaly detection, where understanding dependencies across time is crucial.
LSTM Architecture
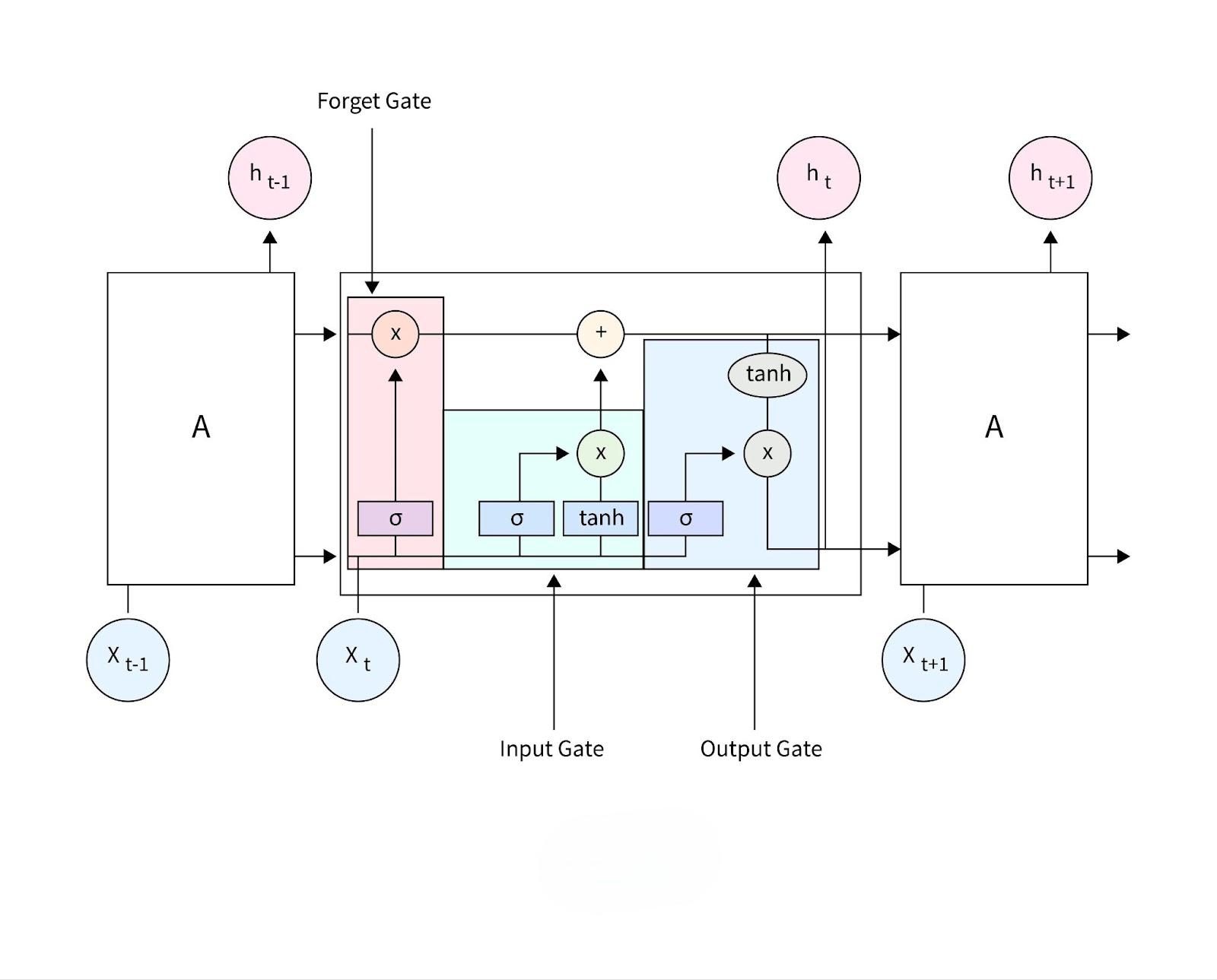
Components of LSTM
The architecture of Long Short-Term Memory (LSTM) revolves around its three main gates—forget, input, and output gates—that work together to manage the flow of information in the network:
1. Forget Gate
The forget gate determines what information from the previous cell state should be discarded. It uses a sigmoid function to output values between 0 and 1, where 0 indicates “completely forget” and 1 indicates “completely retain.” This allows the LSTM to reset irrelevant details while retaining essential context, ensuring efficient memory management.
2. Input Gate
The input gate decides what new information should be added to the cell state. It combines a sigmoid activation (to determine which values to update) with a tanh activation (to create a candidate vector of new information). This mechanism allows the LSTM to integrate fresh, relevant data into its memory.
3. Output Gate
The output gate determines the information to pass to the next layer or time step. It uses the updated cell state in conjunction with a sigmoid activation to filter relevant outputs. The processed data is scaled using a tanh function, ensuring the LSTM focuses on meaningful features while suppressing noise.
These gates collectively empower LSTMs to address long-term dependencies by dynamically retaining or discarding information, making them highly effective in sequence-based tasks.
Variants of LSTM
1. Vanilla LSTM
The standard LSTM architecture forms the foundation of sequence modeling. It includes the three main gates (forget, input, and output) and a memory cell. Vanilla LSTMs are widely used in tasks like language translation and time-series forecasting.
2. Peephole Connections
This variant enhances LSTM by connecting the memory cell state directly to the gates, allowing the network to better account for long-term dependencies. Peephole LSTMs are particularly effective in applications requiring precise timing, such as speech synthesis.
3. Gated Recurrent Unit (GRU)
The GRU is a simplified alternative to LSTM, combining the forget and input gates into a single update gate. It also eliminates the separate memory cell, reducing computational complexity while retaining performance. GRUs are often preferred in scenarios with limited resources or less intricate dependencies.
Each LSTM variant addresses specific challenges, offering flexibility to researchers and practitioners in tackling diverse sequential data problems.
How LSTM Works?
Long Short-Term Memory (LSTM) networks address the limitations of traditional RNNs by maintaining long-term dependencies through a unique gating mechanism. Here’s a step-by-step explanation of the LSTM workflow:
1. Input Processing
Each LSTM cell receives input data (x_t) at a specific time step along with the previous hidden state (h_t-1) and cell state (C_t-1). This combination allows the network to consider both current and historical information.
2. Forget Gate
The forget gate determines which parts of the previous cell state (C_t-1) should be discarded. It uses a sigmoid function to produce values between 0 and 1, where 0 means “forget this information” and 1 means “retain completely.”
$$f_t = \sigma(W_f \cdot [h_{t-1}, x_t] + b_f)$$
3. Input Gate
The input gate updates the cell state with new information. It comprises two parts:
- Candidate State: A tanh layer generates potential updates (C̃_t).
- Update Decision: A sigmoid layer decides the importance of the candidate state.
$$i_t = \sigma(W_i \cdot [h_{t-1}, x_t] + b_i)$$
$$C̃_t = \tanh(W_C \cdot [h_{t-1}, x_t] + b_C)$$
4. Cell State Update
The forget gate and input gate combine to update the cell state (C_t):
$$C_t = f_t \ast C_{t-1} + i_t \ast C̃_t$$
5. Output Gate
The output gate decides which parts of the cell state should influence the hidden state (h_t). It applies a sigmoid function to select the relevant parts, followed by a tanh transformation to produce the final hidden state:
$$o_t = \sigma(W_o \cdot [h_{t-1}, x_t] + b_o)$$
$$h_t = o_t \ast \tanh(C_t)$$
Visualizing Information Flow
In an LSTM cell, information flows through the forget, input, and output gates, each contributing to the decision-making process. This gating mechanism enables LSTMs to selectively update, retain, or discard information, ensuring robust handling of sequential data.
LSTM vs. RNN
Recurrent Neural Networks (RNNs) are foundational for sequence modeling, but they have limitations when handling long-term dependencies. Long Short-Term Memory (LSTM) networks address these challenges effectively.
| Aspect | RNN | LSTM |
| Architecture | Simple structure with hidden states. | Complex structure with cell states and gating mechanisms. |
| Gradient Issues | Prone to vanishing and exploding gradients in long sequences. | Mitigates gradient issues using cell states for better information flow. |
| Memory Management | Relies on hidden states, often losing long-term dependencies. | Cell states and gates enable retention of relevant long-term information. |
| Sequence Length Handling | Effective for short sequences, struggles with long-term dependencies. | Handles both short and long sequences efficiently. |
| Learning Mechanism | Simple backpropagation through time (BPTT). | Incorporates gated mechanisms (forget, input, and output gates). |
| Flexibility | Limited to straightforward tasks like sentiment analysis. | Suitable for complex tasks like machine translation and speech synthesis. |
| Use Cases | Sentiment analysis, simple time-series prediction. | Time-series forecasting, video analysis, and NLP tasks like language modeling. |
| Training Stability | Gradients can become unstable, affecting model performance. | Gates ensure stable training even with deep sequences. |
By using dedicated gates and cell states, LSTMs overcome the inherent limitations of RNNs, making them a powerful choice for sequential data processing.
Applications of LSTM
1. Speech Recognition: LSTMs play a vital role in converting spoken words into text by processing sequential audio data. Their ability to retain long-term dependencies makes them effective in identifying patterns in speech signals, improving the accuracy of automatic speech recognition systems used in virtual assistants and transcription software.
2. Natural Language Processing (NLP): LSTMs are extensively used in NLP tasks like sentiment analysis, language translation, and text summarization. They capture the context and semantics of words over long sentences, enabling applications such as chatbots, email sorting, and predictive text systems. For example, Google Translate leverages LSTMs to deliver accurate translations by understanding word relationships.
3. Time-Series Forecasting: LSTMs excel in analyzing sequential data over time, making them a preferred choice for forecasting trends in financial markets, weather predictions, and energy consumption. Their ability to capture temporal dependencies enables better modeling of complex time-dependent patterns.
4. Video Captioning: By integrating LSTMs with computer vision techniques, video captioning systems generate textual descriptions for videos. LSTMs process sequential frames and match them with contextual text, enabling applications like automated video tagging and accessibility for visually impaired users.
5. Healthcare Data Analysis: In healthcare, LSTMs analyze time-series data such as patient vitals, ECG signals, and medical histories to predict diseases, monitor health conditions, and recommend personalized treatments. Their reliability in handling noisy and complex medical data makes them invaluable in medical research and diagnostics.
LSTM’s versatility in handling sequential data has driven innovation across diverse fields, reshaping the way tasks are automated and interpreted.
Conclusion
LSTMs have revolutionized sequence modeling in deep learning by effectively addressing the limitations of traditional RNNs, such as the vanishing and exploding gradient problems. Their unique architecture, including forget, input, and output gates, enables the retention and selective updating of information, making them invaluable for tasks involving sequential data.
Understanding LSTM’s architecture and applications is essential for leveraging its capabilities in fields like natural language processing, speech recognition, and healthcare. These networks have opened doors to advanced solutions, from translating languages to predicting stock market trends and enhancing patient care.
As research continues, LSTMs and their variants, such as GRUs and Peephole LSTMs, hold immense potential for innovation. Their adaptability in processing diverse types of sequential data ensures their relevance in tackling complex challenges and advancing technologies in AI and machine learning.
References:
- Long short-term memory – Wikipedia
- Long Short-Term Memory Network – an overview | ScienceDirect Topics


