A loss function is a fundamental concept in machine learning, representing a mathematical measure of the difference between the predicted values and the actual values. It quantifies how well a machine learning model performs during training, with smaller loss values indicating better predictions and higher values signaling a need for improvement.
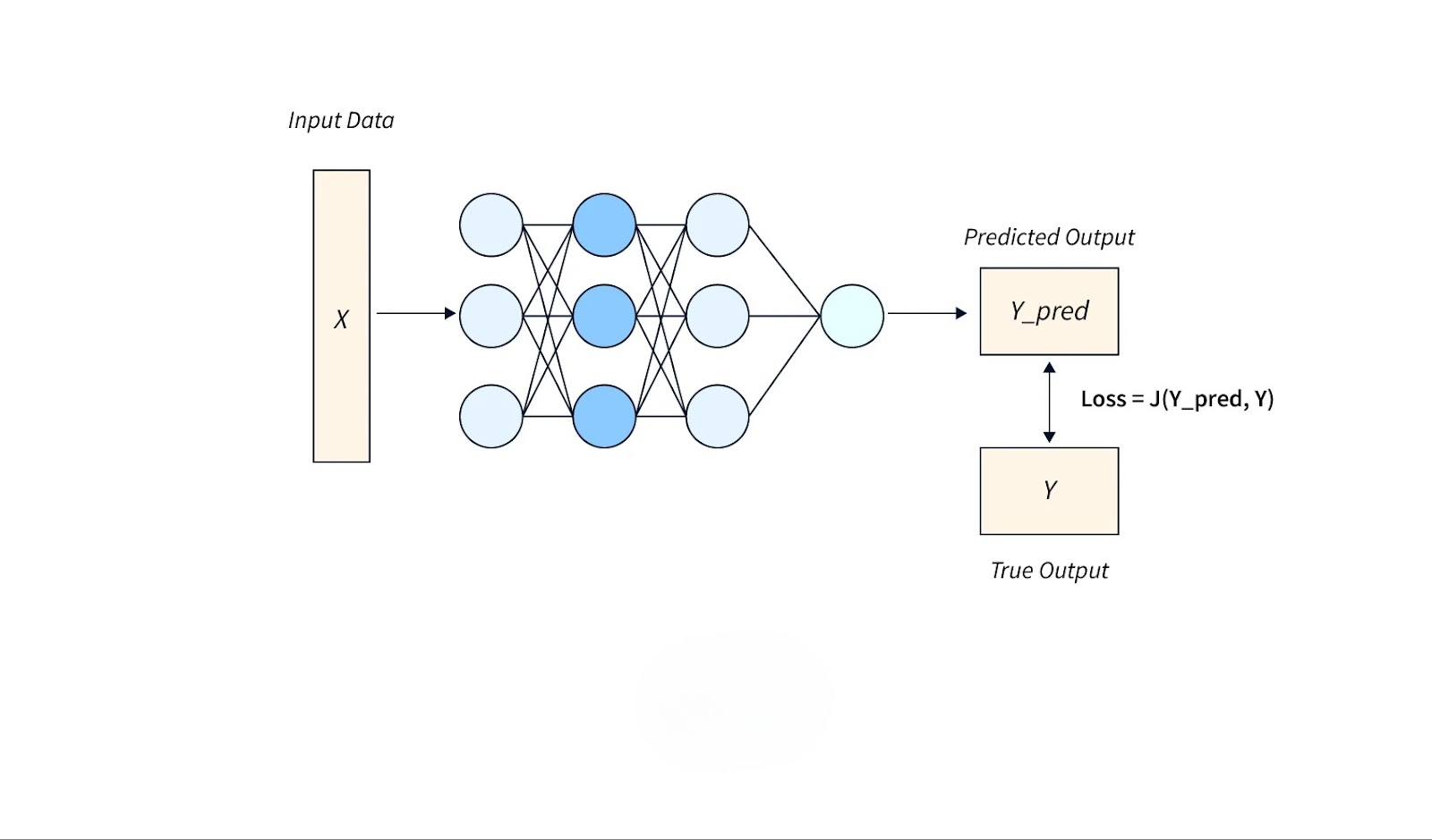
The primary role of a loss function is to guide the training process of a machine learning model. It provides feedback by calculating the error in the model’s predictions, which helps adjust the model’s parameters for better accuracy. This adjustment occurs through backpropagation, where the computed loss is used to update the model’s weights via gradient descent or other optimization algorithms.
Loss functions act as the objective metric that machine learning models aim to minimize during training. By reducing the loss value, the model improves its ability to generalize and make accurate predictions on unseen data. This process ensures that the model learns to map input features to output labels effectively.
Simple Loss Formula
In its simplest form, a loss function can be expressed as:
$$\text{Loss} = \text{Actual Value} – \text{Predicted Value}$$
For instance, if the actual value is 10 and the predicted value is 8, the loss would be $10 – 8 = 2$
Loss functions are crucial for driving the learning process and ensuring that machine learning models achieve optimal performance, making them an indispensable component in the field of artificial intelligence.
Importance of Loss Functions in Machine Learning
Loss functions play a critical role in the learning process and significantly influence the accuracy and performance of machine learning models. By providing a measurable objective, they ensure the model learns effectively and produces predictions that align closely with actual outcomes.
Impact on Learning and Accuracy
Loss functions guide the model by quantifying errors during training. Optimization algorithms, such as gradient descent, rely on these loss values to adjust model parameters iteratively, reducing errors with each step. A well-chosen loss function ensures the model captures the underlying data patterns, thereby improving its accuracy and generalization on unseen data.
Role in Model Selection
Minimizing the loss value helps identify the best-fitting model. During training, the loss function determines how well the model is learning and when it is overfitting or underfitting. A lower loss value indicates that the model is effectively balancing bias and variance.
Impact of Incorrect Loss Function Selection
Choosing the wrong loss function can lead to suboptimal results, especially in regression and classification tasks:
- Regression Models: Using a non-suitable loss function, such as Cross-Entropy Loss, instead of Mean Squared Error, may fail to capture numerical relationships.
- Classification Models: Employing Mean Squared Error in place of Cross-Entropy Loss can result in slower convergence and poor classification boundaries.
In essence, loss functions are the backbone of model training, ensuring the model learns efficiently and achieves its intended purpose.
Categories of Loss Functions
Loss functions are broadly categorized based on the type of machine learning task, ensuring they align with the model’s output nature and objectives. Proper categorization is crucial for achieving optimal performance.
1. Regression Loss Functions
These loss functions are used in regression tasks, where the model predicts continuous numerical values. They measure the error between the actual and predicted values and guide the model in minimizing this discrepancy.
Examples: Mean Squared Error (MSE), Mean Absolute Error (MAE), and Huber Loss.
Use Case: Predicting housing prices, stock values, or temperatures requires regression loss functions to achieve accurate outputs.
2. Classification Loss Functions
Classification loss functions are employed in classification tasks, where the goal is to categorize data into discrete classes. These functions evaluate the probability distribution of predicted class labels and penalize incorrect predictions.
Examples: Cross-Entropy Loss, Hinge Loss, and Kullback-Leibler Divergence.
Use Case: Tasks like image classification, spam detection, or sentiment analysis rely heavily on classification loss functions to ensure accurate categorizations.
Regression Loss Functions in Machine Learning
Regression loss functions play a crucial role in machine learning by measuring the error in predictions for continuous output variables. Here are some of the most commonly used regression loss functions:
1. Mean Squared Error (MSE)
Mean Squared Error calculates the average squared difference between predicted and actual values. It emphasizes larger errors due to squaring, making it sensitive to significant deviations.
Formula:
$$\text{MSE} = \frac{1}{n} \sum_{i=1}^{n} (y_i – \hat{y}_i)^2$$
Pros:
- Penalizes large errors more, making it effective for detecting substantial deviations.
Cons: - Highly sensitive to outliers, as squaring amplifies their impact.
Use Case:
MSE is ideal for problems where reducing large errors is critical, such as energy usage prediction.
2. Mean Absolute Error (MAE)
Mean Absolute Error computes the average absolute difference between predicted and actual values, treating all errors equally.
Formula:
$$\text{MAE} = \frac{1}{n} \sum_{i=1}^{n} |y_i – \hat{y}_i|$$
Pros:
- Less sensitive to outliers compared to MSE.
Cons: - Less smooth gradients, making it harder to optimize in some gradient-based models.
Use Case:
MAE is commonly used when errors of all magnitudes should be treated equally, such as house price prediction.
3. Huber Loss
Huber Loss is a hybrid of MSE and MAE, offering the robustness of MAE while retaining the smoothness of MSE. It switches between the two based on a threshold (δ\deltaδ):
Formula:
$$L_{\delta}(a) = \begin{cases} \frac{1}{2}a^2 & \text{for } |a| \leq \delta, \\ \delta (|a| – \frac{1}{2} \delta) & \text{for } |a| > \delta. \end{cases} $$
Pros:
- Robust to outliers while still penalizing smaller errors effectively.
Cons: - Requires tuning the δ\deltaδ parameter for optimal performance.
Use Case:
Huber Loss is ideal for datasets with outliers, such as fraud detection or error-prone sensor data.
4. Log-Cosh Loss
Log-Cosh Loss is a smooth approximation of MAE, defined as:
$$\text{Log-Cosh Loss} = \sum_{i=1}^{n} \log(\cosh(y_i – \hat{y}_i))$$
It penalizes large errors less aggressively than MSE but more smoothly than MAE.
Pros:
- Provides smooth gradients for optimization.
Cons: - Slightly slower to compute than simpler functions like MSE.
Use Case:
Log-Cosh is suitable for regression tasks where outliers exist but shouldn’t dominate the loss function, such as predicting temperature variations.
5. Quantile Loss
Quantile Loss is used to predict confidence intervals or handle skewed data distributions. It minimizes the quantile regression error, penalizing over-predictions and under-predictions differently.
Formula:
$$\text{Quantile Loss} = \sum_{i=1}^{n} \begin{cases} \alpha \cdot (y_i – \hat{y}_i) & \text{if } y_i > \hat{y}_i, \\ (1 – \alpha) \cdot (\hat{y}_i – y_i) & \text{if } y_i \leq \hat{y}_i. \end{cases} $$
Pros:
- Useful for interval predictions and handling non-uniform error penalties.
Cons: - Requires selecting the quantile parameter ($\alpha$).
Use Case:
Quantile Loss is effective in financial forecasting and risk analysis, where predicting upper and lower bounds is crucial.
Classification Loss Functions in Machine Learning
Classification loss functions evaluate the difference between predicted and actual class labels in machine learning tasks that deal with discrete categories. They ensure the model learns to assign correct labels by minimizing the discrepancy during training. Below are the commonly used classification loss functions:
1. Binary Cross-Entropy Loss (Log Loss)
Binary Cross-Entropy Loss measures the difference between actual binary class labels and predicted probabilities. It is essential for models that output probabilities for two classes and ensures predictions align with the actual labels.
Formula:
$$\text{Binary Cross-Entropy} = -\frac{1}{n} \sum_{i=1}^{n} [y_i \log(\hat{y}_i) + (1-y_i) \log(1-\hat{y}_i)]$$
This formula calculates the loss by averaging the negative log probabilities of correct predictions, penalizing incorrect predictions more when the model is confident but wrong. It is a widely used loss function for binary classification tasks, such as spam detection and fraud identification.
2. Hinge Loss
Hinge Loss is commonly used in Support Vector Machines (SVMs) for binary classification. It ensures a margin between the data points and the decision boundary, penalizing predictions that fall within the margin or on the incorrect side of the boundary.
Formula:
$$L(y, f(x)) = \max(0, 1 – y \cdot f(x))$$
In the formula, $y$ represents the actual class label ($+1$ or $-1$), and $f(x)$ is the predicted value. Predictions outside the margin (greater than 1) are not penalized, encouraging the model to maximize the separation between classes.
3. Kullback-Leibler (KL) Divergence
KL Divergence is a metric for measuring the difference between two probability distributions, typically the predicted distribution and the actual (true) distribution. It quantifies how much information is lost when one distribution is used to approximate another.
Formula:
$$D_{KL}(P || Q) = \sum_{i} P(i) \log\left(\frac{P(i)}{Q(i)}\right)$$
In this formula, $P(i)$ represents the actual probability distribution, and $Q(i)$ is the predicted probability distribution. KL Divergence is widely used in applications involving probabilistic models, such as language models and generative adversarial networks (GANs).
4. Multi-Class Cross-Entropy Loss
Multi-Class Cross-Entropy Loss extends Binary Cross-Entropy to handle multiple classes. It calculates the loss by comparing the softmax probabilities of predicted outputs with the actual class labels across all classes.
Formula:
$$-\sum_{i=1}^{n} \sum_{c=1}^{C} y_{i,c} \log(\hat{y}_{i,c})$$
Here, $C$ represents the total number of classes, $y_{i,c}$ indicates whether class $c$ is the correct class for instance $i$, and $\hat{y}_{i,c}$ is the predicted probability for class $c$. This loss function is commonly applied in tasks like image recognition and sentiment analysis, where the output spans multiple categories.
By choosing the appropriate classification loss function, machine learning models can be tailored to effectively handle specific challenges in tasks ranging from binary classification to multi-class prediction, ensuring accurate and reliable results.
Choosing the Right Loss Function
Selecting the appropriate loss function is a critical step in optimizing machine learning models. It directly impacts the training process, model performance, and the ability to generalize to unseen data. Below are the key factors to consider and examples to guide this decision:
- Type of Problem: The nature of the machine learning task—regression or classification—plays a vital role in determining the loss function. For regression tasks, loss functions like Mean Squared Error (MSE) or Mean Absolute Error (MAE) are common, while classification tasks rely on functions like Cross-Entropy or Hinge Loss.
- Outliers: For datasets with outliers, using robust loss functions is crucial. Loss functions like Huber Loss or Log-Cosh Loss are better suited for handling outliers compared to MSE, which is sensitive to large deviations.
- Model Type: The architecture of the model also influences the choice of loss function. For example:
- Margin-based models, like Support Vector Machines, work best with Hinge Loss.
- Probabilistic models, such as logistic regression or neural networks, require Cross-Entropy Loss for optimal results.
- Computational Efficiency: When training on large datasets or resource-constrained environments, computationally efficient loss functions like MAE or MSE may be prioritized over complex alternatives like Quantile Loss or KL Divergence, which can be more resource-intensive.
Examples
- Regression Tasks:
- Use MSE for datasets where smooth predictions are required and outliers are minimal.
- Opt for MAE or Huber Loss when dealing with datasets that contain significant outliers.
- Classification Tasks:
- For probabilistic outputs, like those in neural networks or logistic regression, Cross-Entropy Loss is ideal.
- For margin-based classifiers, such as SVMs, Hinge Loss provides optimal performance.
By carefully evaluating the problem type, dataset characteristics, and computational constraints, the right loss function can be chosen to maximize model efficiency and accuracy.
Implementation of Loss Functions in Python
Loss functions are a crucial component of machine learning pipelines, and popular libraries such as Scikit-learn and TensorFlow make it simple to implement them. Below are examples of implementing commonly used loss functions:
Example 1: Mean Squared Error (MSE)
MSE is widely used in regression tasks to calculate the average squared difference between actual and predicted values.
from sklearn.metrics import mean_squared_error
# Actual and Predicted Values
y_true = [3.0, -0.5, 2.0, 7.0]
y_pred = [2.5, 0.0, 2.0, 8.0]
# Compute Mean Squared Error
mse = mean_squared_error(y_true, y_pred)
print("Mean Squared Error:", mse)Output:
Mean Squared Error: 0.375Example 2: Cross-Entropy Loss
Cross-Entropy Loss is commonly used in binary or multi-class classification tasks to compare predicted probabilities with true labels.
import tensorflow as tf
# Actual and Predicted Probabilities
y_true = [0, 1, 0] # True labels
y_pred = [0.1, 0.7, 0.2] # Predicted probabilities
# Compute Binary Cross-Entropy Loss
loss = tf.keras.losses.BinaryCrossentropy()
print("Binary Cross-Entropy Loss:", loss(y_true, y_pred).numpy())Output:
Binary Cross-Entropy Loss: 0.35667494These examples demonstrate how to implement MSE for regression and Cross-Entropy Loss for classification using Python libraries. By leveraging such tools, machine learning practitioners can streamline the evaluation and optimization of their models.
Conclusion
Loss functions are pivotal in guiding machine learning models toward improved accuracy and performance by quantifying errors and providing direction for optimization. Selecting the right loss function is crucial and depends on the problem type—regression or classification—and the unique characteristics of the dataset, such as the presence of outliers or computational constraints.
By carefully aligning the choice of loss function with the model’s objectives, practitioners can significantly enhance the learning process and achieve optimal results. Experimenting with different loss functions ensures a tailored approach, enabling the development of robust and efficient machine learning pipelines.
References:


