Linear regression is one of the most essential algorithms in machine learning, forming the backbone of predictive analytics. It models the relationship between a dependent variable (outcome) and one or more independent variables (predictors), allowing businesses and researchers to predict continuous outcomes based on input data. By identifying trends and relationships, linear regression provides meaningful insights for decision-making across a variety of industries, such as healthcare, finance, and retail.
In machine learning, linear regression is part of supervised learning. In supervised learning, the model learns from labeled data (where both input and output values are known) to make predictions on unseen data. Linear regression’s power lies in its ability to provide not just predictions but also an understanding of the strength and direction of relationships between variables. This makes it a foundational tool for understanding more complex regression and classification models, as well as for creating benchmark models to compare with more advanced algorithms.
The significance of linear regression extends to both academic research and real-world applications. It is widely used in predictive analysis, where the objective is to forecast future trends based on historical data. For example, it can help predict future stock prices or sales trends. One of the reasons it remains popular is its ability to give interpretable results—meaning that the model’s coefficients provide actionable insights about the relationship between the dependent and independent variables.
What is Linear Regression?
Linear regression is a supervised learning algorithm used to predict continuous values by modeling the relationship between a dependent (target) variable and one or more independent (predictor) variables. The objective of linear regression is to determine a linear relationship between the variables, which can then be used to predict outcomes for unseen data.
Mathematically, the model estimates the dependent variable as:
$Y = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \ldots + \beta_n X_n + \epsilon$
Where:
$Y$ is the dependent variable (the target outcome to predict).
$X_1, X_2, \ldots, X_n$ are independent variables (predictors).
$\beta_0$ is the intercept, representing the expected value of $Y$ when all predictors are zero.
$\beta_1, \beta_2, \ldots, \beta_n$ are the coefficients, which represent the change in the dependent variable for each unit change in the corresponding independent variable.
$\epsilon$ is the error term, accounting for the deviation between the predicted and actual values.
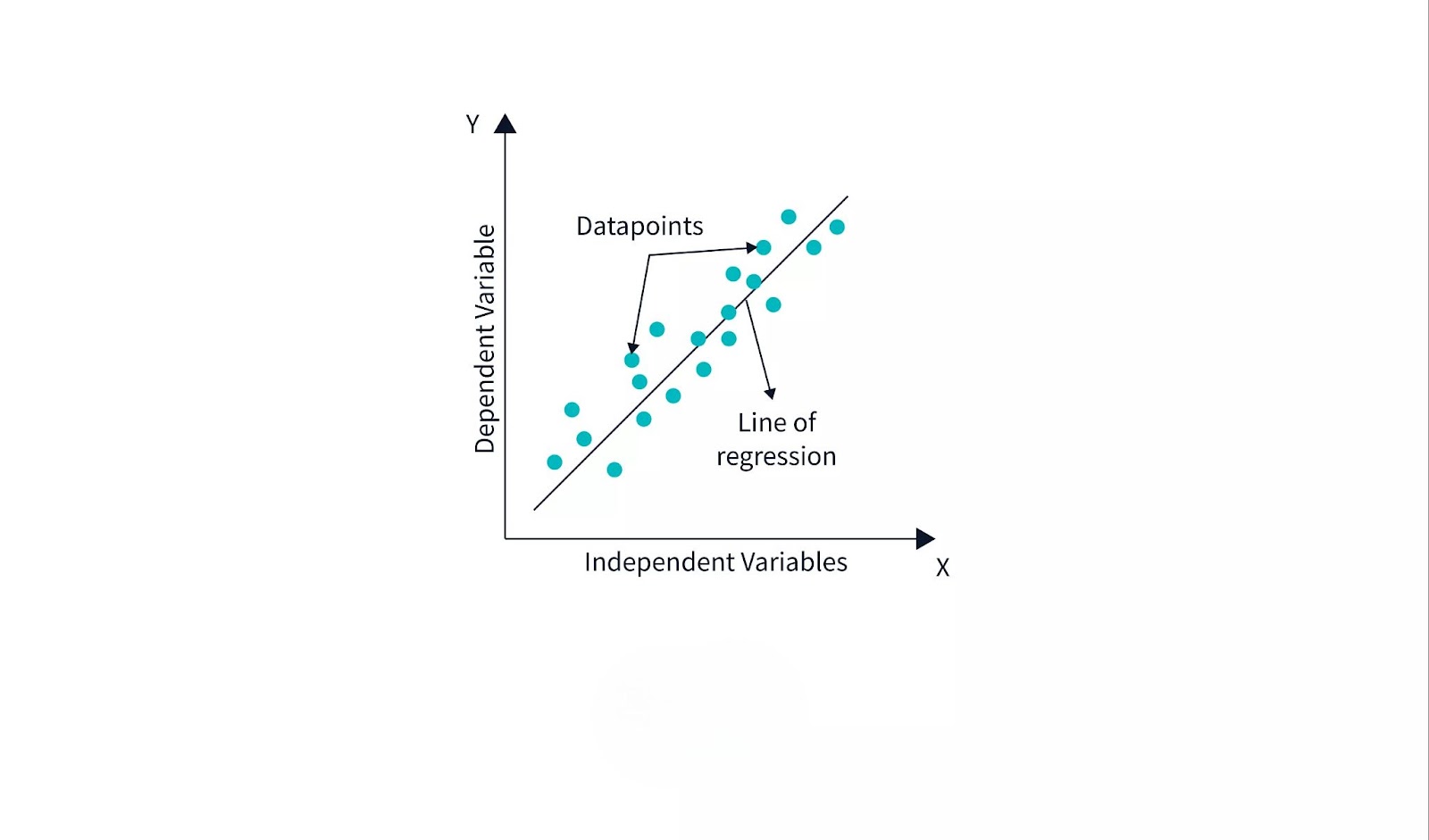
Linear regression models a straight-line relationship between the predictors and the outcome. This relationship is the foundation for making forecasts and predictions.
Dependent and Independent Variables
The dependent variable is the value the model aims to predict, such as house prices or customer spending. On the other hand, independent variables are the features used to make the prediction, such as the size of a house, the number of rooms, or marketing spend. The model identifies how these independent variables influence the dependent variable.
Example: Real-Life Applications of Linear Regression
- Predicting House Prices: A real estate company can use linear regression to predict the price of a house based on its size, number of bedrooms, and location.
- Sales Forecasting: Companies can forecast future sales based on factors like advertising spend and seasonal trends, helping them plan inventory and campaigns.
- Medical Research: In healthcare, linear regression helps predict patient outcomes (like blood pressure) based on variables such as age, weight, and lifestyle factors.
Linear regression offers a simple yet effective way to identify trends and relationships, making it a versatile tool across various industries.
Why Linear Regression is Important?
Linear regression serves as the baseline model for solving regression problems in machine learning. Despite being simple, it is effective in many real-world scenarios. Its importance lies in the following:
- Simplicity and Ease of Use: Linear regression is easy to implement and understand, making it a popular choice for beginners.
- Interpretability: The model’s coefficients reveal the relationship between independent variables and the outcome, helping interpret the impact of each feature.
- Efficient Computation: Linear regression can handle large datasets efficiently and provides quick predictions.
- Foundational Concept: It acts as a stepping stone for understanding more advanced machine learning models like logistic regression and support vector machines.
Because of these strengths, linear regression finds use across various industries, ranging from predictive modeling in finance to trend forecasting in healthcare.
Types of Linear Regression in Machine learning
Linear regression can be divided into two main types: simple linear regression and multiple linear regression. Both aim to establish a linear relationship between variables, but they differ in the number of independent variables they use. Below is a detailed breakdown of these types, including their mathematical formulations, key differences, and how they estimate the best-fit line.
1. Simple Linear Regression
Simple linear regression involves a single independent variable (predictor) used to predict the value of a dependent variable (target). It examines how a change in the independent variable affects the outcome. This type of regression is used when the relationship between the two variables can be represented by a straight line.
The mathematical expression for simple linear regression is:
$$Y = \beta_0 + \beta_1 X + \epsilon$$
Where:
- YYY is the dependent variable.
- XXX is the independent variable.
- $\beta_0$ is the intercept, representing the value of YYY when XXX is zero.
- $\beta_1$ is the slope, indicating how much YYY changes with a unit change in XXX.
- $\epsilon$ is the error term, accounting for the deviation between actual and predicted values.
Example: A company may use simple linear regression to predict sales revenue based on advertising expenses. In this case, advertising spend is the independent variable, and revenue is the dependent variable.
2. Multiple Linear Regression
Multiple linear regression extends the concept of simple linear regression by using more than one independent variable to predict a single dependent variable. This approach captures the combined effect of multiple predictors, which often reflects real-world scenarios more accurately.
The equation for multiple linear regression is:
$$Y = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \ldots + \beta_n X_n + \epsilon$$
Where:
- $X_1, X_2, \ldots, X_n$ are independent variables.
- $\beta_1, \beta_2, \ldots, \beta_n$ are the corresponding coefficients that indicate how each predictor influences the dependent variable.
Example: Real estate firms often predict house prices using multiple linear regression by considering features like square footage, number of bedrooms, and location.
Mathematical Formulations and Differences Between Simple and Multiple Linear Regression
- Number of Variables: Simple linear regression uses one independent variable, while multiple linear regression involves two or more.
- Equation Complexity: The equation for simple linear regression is straightforward, while multiple linear regression requires handling multiple predictors and their interactions.
- Interpretation: In simple linear regression, the slope coefficient directly represents the effect of the independent variable. In multiple linear regression, each coefficient shows the marginal effect of a predictor, holding other variables constant.
- Overfitting Risk: Multiple linear regression has a higher risk of overfitting due to the increased number of predictors, especially if irrelevant variables are included.
How the Model Estimates the Best-Fit Line
Both simple and multiple linear regression aim to find the best-fit line that minimizes the error between predicted and actual values. This is achieved using the Ordinary Least Squares (OLS) method, which minimizes the sum of squared residuals.
The residual for each observation is calculated as:
$$\text{Residual} = Y_i – \hat{Y}_i$$
Where $Y_i$ is the actual value, and $\hat{Y}_i$ is the predicted value.
The OLS method finds the optimal coefficients ($\beta$) by minimizing the following objective function:
$$\text{Minimize} \sum_{i=1}^{n} (Y_i – \hat{Y}_i)^2$
The best-fit line in simple linear regression is a straight line through the data points, indicating the trend between the independent and dependent variables. For multiple linear regression, the best-fit line is a hyperplane, as it involves multiple dimensions.
What is the Best Fit Line?
The best-fit line in linear regression is the line that minimizes the difference between the predicted and actual values of the dependent variable. This line represents the optimal linear relationship between the independent and dependent variables. In mathematical terms, the best-fit line is determined by minimizing the sum of squared residuals—the difference between the observed values and the predicted values from the model.
Hypothesis Function in Linear Regression
The hypothesis function for linear regression is expressed as:
$\hat{Y} = \beta_0 + \beta_1 X$
Where:
- $\hat{Y}$ is the predicted value of the dependent variable.
- XXX is the independent variable.
- $\beta_0$ is the intercept, representing the predicted value when X = 0.
- $\beta_1$ is the slope, which indicates how much $\hat{Y}$ changes for a unit change in XXX.
In multiple linear regression, this hypothesis function extends to:
$$\hat{Y} = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \ldots + \beta_n X_n$$
This function allows the model to make predictions by assigning weights (coefficients) to each feature.
How the Best-Fit Line Minimizes Error
The goal of linear regression is to minimize the residuals (the difference between actual and predicted values). The residual for a single observation is:
$$\text{Residual} = Y_i – \hat{Y}_i$$
To ensure that negative and positive residuals do not cancel each other out, the sum of squared residuals is used as the objective function:
$$\sum_{i=1}^{n} (Y_i – \hat{Y}_i)^2$$
The Ordinary Least Squares (OLS) method minimizes this sum to find the optimal values for the coefficients.
How to Update θ₁ and θ₂ Values
The coefficients $\theta_1$ (slope) and $\theta_2$ (intercept) are updated using gradient descent. This optimization algorithm iteratively adjusts the parameters to minimize the error between predicted and actual values. The parameter update rule is:
$$\theta_j = \theta_j – \alpha \frac{\partial J(\theta)}{\partial \theta_j}$$
Where:
- $\alpha$ is the learning rate that controls the step size during each update.
- $J(\theta)$ is the cost function.
This process continues until the algorithm converges to the optimal coefficients.
Geometrical and Statistical Significance of the Best-Fit Line
- Geometrically, the best-fit line is the line that passes closest to all the data points, minimizing the sum of squared distances (residuals) between the points and the line. In simple linear regression, the best-fit line is represented in a two-dimensional plane, while in multiple linear regression, it becomes a hyperplane in a multi-dimensional space.
- Statistically, the best-fit line allows for the most accurate predictions of the dependent variable. The slope of the line indicates the strength and direction of the relationship between the variables, and the intercept provides the starting value when all predictors are zero.
Cost Function in Linear Regression
The cost function in linear regression is a mathematical formula used to measure the error between the predicted values and the actual values. Its primary purpose is to quantify how well the model’s predictions align with the actual data points. By minimizing the cost function, the model finds the optimal parameters (coefficients) for the best-fit line. This is a crucial step in model optimization, ensuring that the predictions are as accurate as possible.
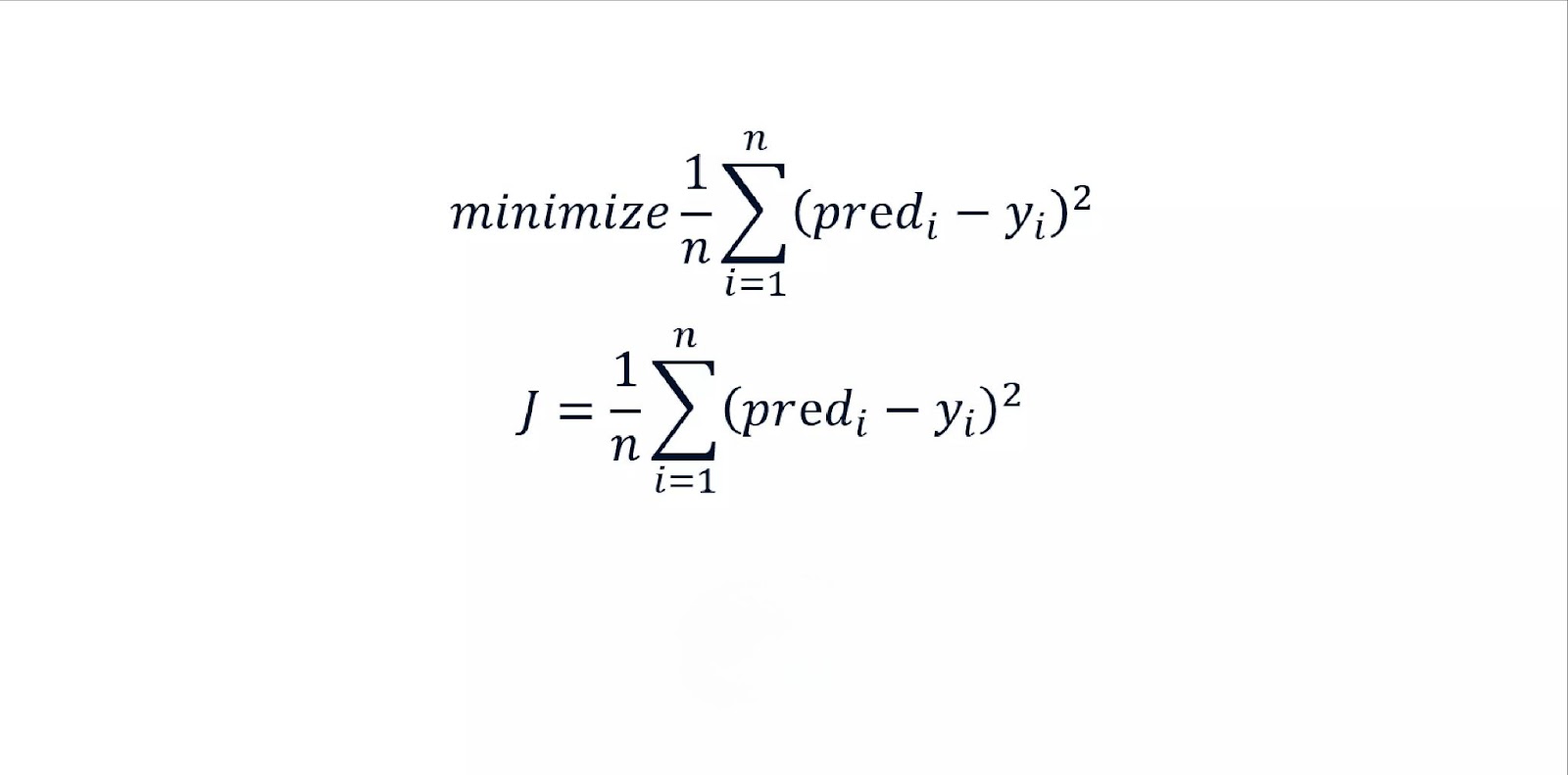
The goal of optimization is to minimize the difference between the predicted outcome (Y^\hat{Y}Y^) and the actual outcome (YYY). This difference, also called the residual, is squared to ensure that both positive and negative deviations are treated equally.
Mean Squared Error (MSE) as a Popular Cost Function
The Mean Squared Error (MSE) is the most commonly used cost function for linear regression. It calculates the average of the squared differences between the actual and predicted values:
$$MSE = \frac{1}{n} \sum_{i=1}^{n} (Y_i – \hat{Y}_i)^2$$
where:
- $Y_i$ is the actual value of the dependent variable for the $i^{th}$ observation
- $\hat{Y}_i$ is the predicted value for the $i^{th}$ observation
- nnn is the number of observations
MSE is effective because it penalizes large errors more than smaller ones, making it particularly sensitive to large deviations. This property ensures that the model focuses on minimizing significant prediction errors, leading to better overall performance.
How the Cost Function Helps in Finding the Best-Fit Line
The cost function plays a central role in determining the best-fit line by guiding the optimization process. In linear regression, Ordinary Least Squares (OLS) is the method used to find the coefficients that minimize the sum of squared residuals. The cost function provides feedback on how well the model performs at each iteration of the optimization process, typically through gradient descent.
Gradient descent adjusts the model’s parameters by moving them in the direction that reduces the value of the cost function. With each iteration, the parameters are updated until the cost function reaches its minimum value, ensuring the model converges to the optimal coefficients.
By minimizing the MSE, the model finds the line that has the least error across all observations, producing the most accurate and reliable predictions. This process ensures the best possible fit between the independent variables and the dependent variable, allowing the model to generalize effectively to new data.
Gradient Descent for Linear Regression in Machine learning
Gradient descent is an optimization algorithm used to minimize the cost function by iteratively adjusting the model’s parameters (coefficients). It plays a vital role in linear regression, guiding the model to find the optimal parameters that yield the best predictions. The primary objective of gradient descent is to reduce the value of the cost function by moving the parameters in the direction of the steepest descent. This algorithm is essential for optimizing large models and ensuring that the error between predicted and actual values is minimized.
How Gradient Descent Works: Step-by-Step
- Initialize Parameters: The coefficients (parameters) are randomly assigned initial values. For example, θ0\theta_0θ0 (intercept) and θ1\theta_1θ1 (slope) can start as arbitrary values.
- Compute the Cost Function: At each iteration, the cost function (Mean Squared Error) is evaluated to measure the model’s performance with the current parameters.
- Calculate the Gradient: The gradient is the partial derivative of the cost function with respect to each parameter. It indicates how much the cost function would change if a parameter were adjusted slightly.
- Update the Parameters: The parameters are updated using the gradient. The update rule is:
$$\theta_j = \theta_j – \alpha \frac{\partial J(\theta)}{\partial \theta_j}$$
Here, $\alpha$ is the learning rate, which controls the size of each step. The process ensures that the parameters move toward the direction that decreases the cost function. - Repeat Until Convergence: The steps are repeated until the parameters converge to values where the cost function reaches its minimum.
Visualization of the Gradient Descent Process
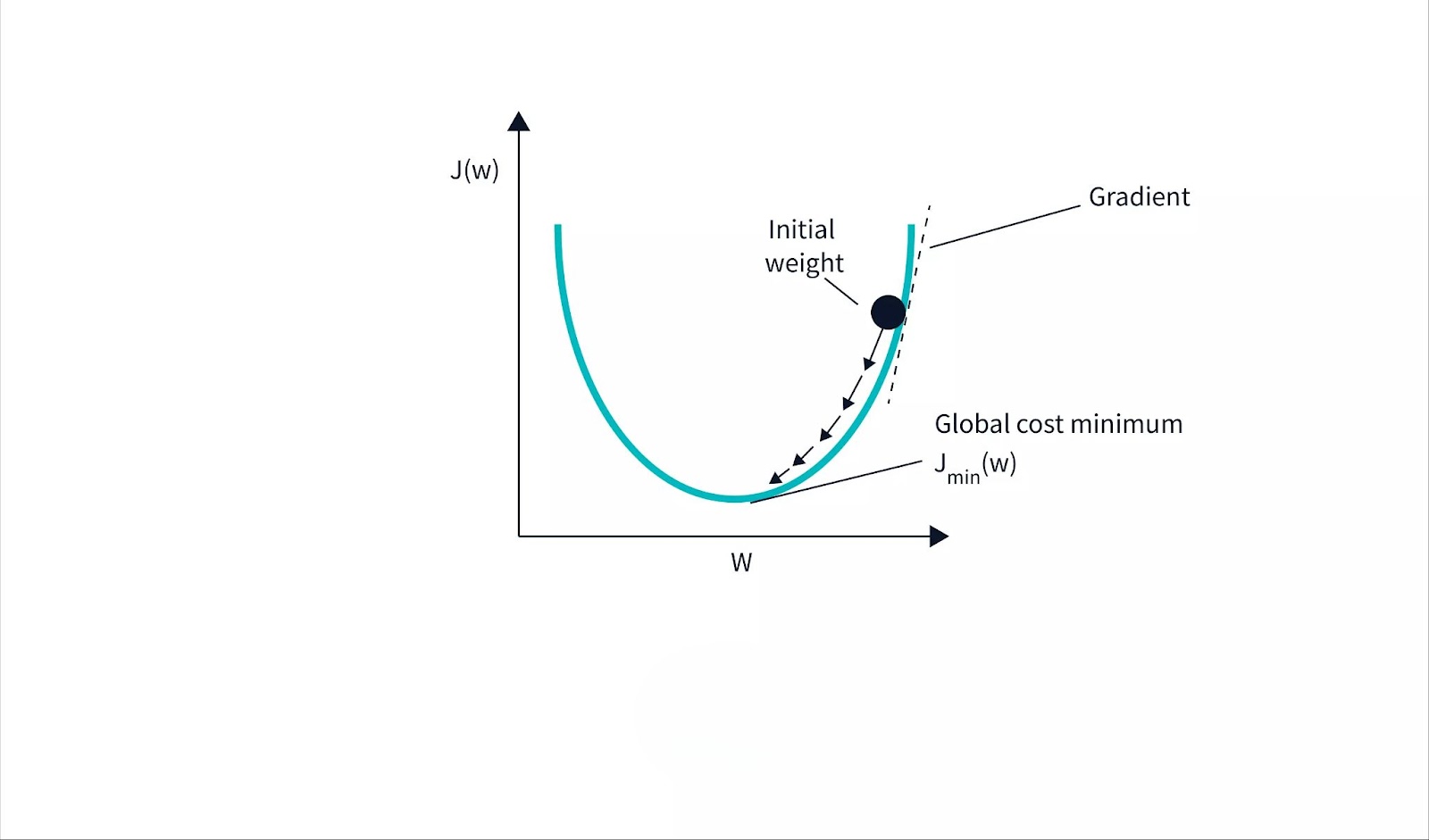
Visualizing gradient descent involves plotting the cost function against parameter values. Initially, the parameters are far from the minimum, and the cost function value is high. With each iteration, the parameters adjust, gradually bringing the cost function to its minimum, represented by a point at the bottom of the curve.
Types of Gradient Descent
- Batch Gradient Descent: Uses the entire dataset to compute the gradient for each step. It is more stable but computationally expensive for large datasets.
- Stochastic Gradient Descent (SGD): Updates the parameters for each data point, making it faster but noisier.
- Mini-Batch Gradient Descent: Combines batch and stochastic approaches by updating parameters using small batches of data, balancing speed and stability.
Assumptions of Linear Regression in Machine learning
Linear regression relies on several assumptions to ensure that the model provides accurate and reliable predictions. If these assumptions are violated, the model’s performance may degrade, resulting in biased estimates or incorrect conclusions. Below is an explanation of the key assumptions that must hold for linear regression to perform effectively.
Linearity
The first assumption is that the relationship between the dependent variable and the independent variable(s) is linear. The model assumes that changes in the predictors result in proportional changes in the outcome. If the relationship is non-linear, the model will struggle to provide accurate predictions.
- Impact of Violation: If the relationship is non-linear, linear regression will produce biased results, and other models, such as polynomial regression, may be more suitable.
Independence of Errors
This assumption states that the residuals (errors) must be independent of each other. In other words, the error for one observation should not be correlated with the error for another observation. This is especially relevant for time-series data, where sequential data points may be correlated.
- Impact of Violation: Violating this assumption leads to autocorrelation, which can result in underestimated standard errors and unreliable statistical inferences. Techniques such as Durbin-Watson tests are used to detect autocorrelation.
Homoscedasticity
Homoscedasticity means that the variance of the residuals remains constant across all levels of the independent variable(s). In other words, the spread of residuals should be the same throughout the range of predicted values.
- Impact of Violation: If the residuals have unequal variance (heteroscedasticity), the model’s predictions may become inefficient, and the standard errors may be incorrect, leading to invalid hypothesis tests. Residual plots help detect heteroscedasticity.
No Multicollinearity (for Multiple Linear Regression)
In multiple linear regression, the independent variables should not be highly correlated with each other. If multicollinearity exists, it becomes difficult to determine the individual effect of each predictor on the outcome.
- Impact of Violation: High multicollinearity inflates the standard errors of the coefficients, making them unstable and hard to interpret. Variance Inflation Factor (VIF) is commonly used to detect multicollinearity.
Normality of Residuals
The residuals are expected to follow a normal distribution. This assumption is important for making valid inferences about the model’s coefficients and for hypothesis testing.
- Impact of Violation: If the residuals are not normally distributed, it may affect the accuracy of confidence intervals and p-values. Q-Q plots and Shapiro-Wilk tests are often used to assess the normality of residuals.
Common Violations and Their Impact on Performance
When these assumptions are violated, the model’s ability to generalize to new data diminishes. For example, non-linearity leads to biased predictions, while heteroscedasticity affects the efficiency of estimates. Autocorrelation in residuals can cause the model to underestimate variability, giving a false sense of accuracy. In practice, when assumptions are violated, practitioners often consider transforming variables, using different models (like polynomial regression), or employing robust regression techniques to mitigate the impact.
Evaluation Metrics for Linear Regression in Machine learning
Evaluation metrics provide a quantitative way to assess the performance of a linear regression model. By measuring the differences between predicted and actual values, these metrics offer insights into how well the model fits the data and generalizes to unseen datasets. Below are the key metrics used to evaluate the accuracy and reliability of linear regression models, along with real-world examples of their application.
Mean Squared Error (MSE)
MSE calculates the average of the squared differences between actual and predicted values. It penalizes large errors more than smaller ones by squaring the residuals, ensuring the model focuses on reducing large deviations.
$$MSE = \frac{1}{n} \sum_{i=1}^{n} (Y_i – \hat{Y}_i)^2$$
Where:
- $Y_i$ is the actual value of the dependent variable.
- $\hat{Y}_i$ is the predicted value.
- nnn is the number of observations.
Interpretation: A lower MSE indicates better model performance. However, since MSE uses squared units, it can be harder to interpret in the context of the original data.
Use Case: MSE is widely used in house price prediction models. If the actual house price is $300,000 and the model predicts $310,000, the squared error for this observation would be $(300,000 – 310,000)^2 = 100,000,000$.
Mean Absolute Error (MAE)
MAE measures the average of the absolute differences between actual and predicted values, offering a more interpretable metric since it retains the original units.
$$MAE = \frac{1}{n} \sum_{i=1}^{n} |Y_i – \hat{Y}_i|$$
Advantages Over MSE: MAE is less sensitive to outliers because it does not square the residuals. It provides a clearer understanding of how far off predictions are from actual values on average.
Use Case: MAE is often used in sales forecasting to measure the accuracy of revenue predictions. For instance, if a model predicts daily sales of 1,000 units but the actual sales are 900, the absolute error is 100 units.
Root Mean Squared Error (RMSE)
RMSE is the square root of MSE, bringing the error back to the original units of the dependent variable, making it more interpretable than MSE.
$$RMSE = \sqrt{MSE}$$
Interpretation: RMSE penalizes larger errors more than smaller ones, similar to MSE, but is easier to relate to the dependent variable’s scale.
Use Case: RMSE is commonly used in climate modeling to predict daily temperatures. It helps identify how close the predicted temperature values are to the actual readings.
R-Squared (R²)
R-squared measures the proportion of the variance in the dependent variable that can be explained by the independent variables. It indicates how well the model fits the data.
$$R^2 = 1 – \frac{SS_{res}}{SS_{tot}}$$
Where:
- $SS_{res}$ is the sum of squared residuals.
- $SS_{tot}$ is the total sum of squares.
Interpretation: An R-squared value of 0.8 means that 80% of the variance in the dependent variable is explained by the model. However, a high R-squared does not always indicate a good model, especially if it overfits the data.
Use Case: R-squared is used in finance to evaluate the performance of models predicting stock prices based on economic indicators.
Adjusted R-Squared
Adjusted R-squared accounts for the number of predictors in the model, providing a more accurate measure of fit. As more variables are added, R-squared can increase even if they do not contribute significantly to the model, but adjusted R-squared penalizes unnecessary predictors.
$$R^2_{adj} = 1 – \frac{(1 – R^2)(n – 1)}{n – k – 1}$$
Where:
- nnn is the number of observations.
- kkk is the number of predictors.
Use Case: Adjusted R-squared is commonly applied in multiple linear regression models to assess whether adding more features improves model performance or leads to overfitting.
Real-World Examples of Metric Applications
- Retail: RMSE is used to forecast daily sales trends, helping businesses adjust inventory levels.
- Real Estate: MSE and MAE are applied to evaluate house price prediction models, guiding property valuation tools.
- Finance: R-squared helps analysts determine how well economic indicators predict stock market movements.
- Healthcare: RMSE measures the accuracy of models predicting patient recovery times based on medical history and treatment plans.
Python Code Implementation of Linear Regression
In this section, we’ll go step-by-step through a Python implementation of linear regression using essential libraries. Python’s scikit-learn library provides a simple interface for building machine learning models, while pandas and numpy are used for data manipulation. This implementation demonstrates how to load a dataset, preprocess the data, train a linear regression model, and evaluate its performance using metrics.
Importing Necessary Libraries
The following libraries are required to implement linear regression:
- pandas: Used for data manipulation and analysis.
- numpy: Provides mathematical operations and array handling.
- scikit-learn: Contains machine learning algorithms, including linear regression.
- matplotlib: Used for data visualization.
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
import matplotlib.pyplot as pltLoading Dataset and Data Preprocessing
The first step is to load the dataset and prepare the data for training. We will assume a sample dataset containing information on house prices, including features like square footage and the number of rooms.
# Load the dataset
data = pd.read_csv('house_prices.csv')
# View the first few rows
print(data.head())Next, we separate the independent variables (features) and the dependent variable (target).
# Define features and target variable
X = data[['size', 'rooms']] # Features: square footage, number of rooms
y = data['price'] # Target: house price
# Split the data into training and testing sets (80% training, 20% testing)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)Building and Training the Linear Regression Model
Now that the data is prepared, we initialize and train the linear regression model using the training dataset.
# Initialize the linear regression model
model = LinearRegression()
# Fit the model on the training data
model.fit(X_train, y_train)
# Display the model coefficients
print("Intercept:", model.intercept_)
print("Coefficients:", model.coef_)The intercept represents the predicted value when all features are zero, and the coefficients show the effect of each feature on the target variable.
Plotting the Regression Line
For visualizing the relationship between a single feature and the target, let’s plot the regression line for one of the features (e.g., house size).
# Plot the data points and regression line
plt.scatter(X_train['size'], y_train, color='blue', label='Actual')
plt.plot(X_train['size'], model.predict(X_train[['size']]), color='red', label='Regression Line')
plt.xlabel('Size (square footage)')
plt.ylabel('Price')
plt.title('Linear Regression: Size vs. Price')
plt.legend()
plt.show()Prediction and Evaluation
Once the model is trained, we use it to make predictions on the test data and evaluate its performance using Mean Squared Error (MSE) and R-squared.
# Make predictions on the test set
y_pred = model.predict(X_test)
# Calculate Mean Squared Error (MSE)
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse}")
# Calculate R-squared
r2 = r2_score(y_test, y_pred)
print(f"R-squared: {r2}")In this example, MSE indicates the average squared difference between predicted and actual house prices, and R-squared explains the proportion of variance in house prices captured by the model.
Regularization Techniques for Linear Models
Regularization is a technique used in machine learning to prevent overfitting, which occurs when a model performs well on the training data but poorly on new, unseen data. In linear regression, overfitting can happen when the model becomes too complex, especially with a large number of features. Regularization addresses this issue by adding a penalty to the cost function, discouraging the model from assigning excessively high weights to any feature. This ensures a simpler, more generalizable model.
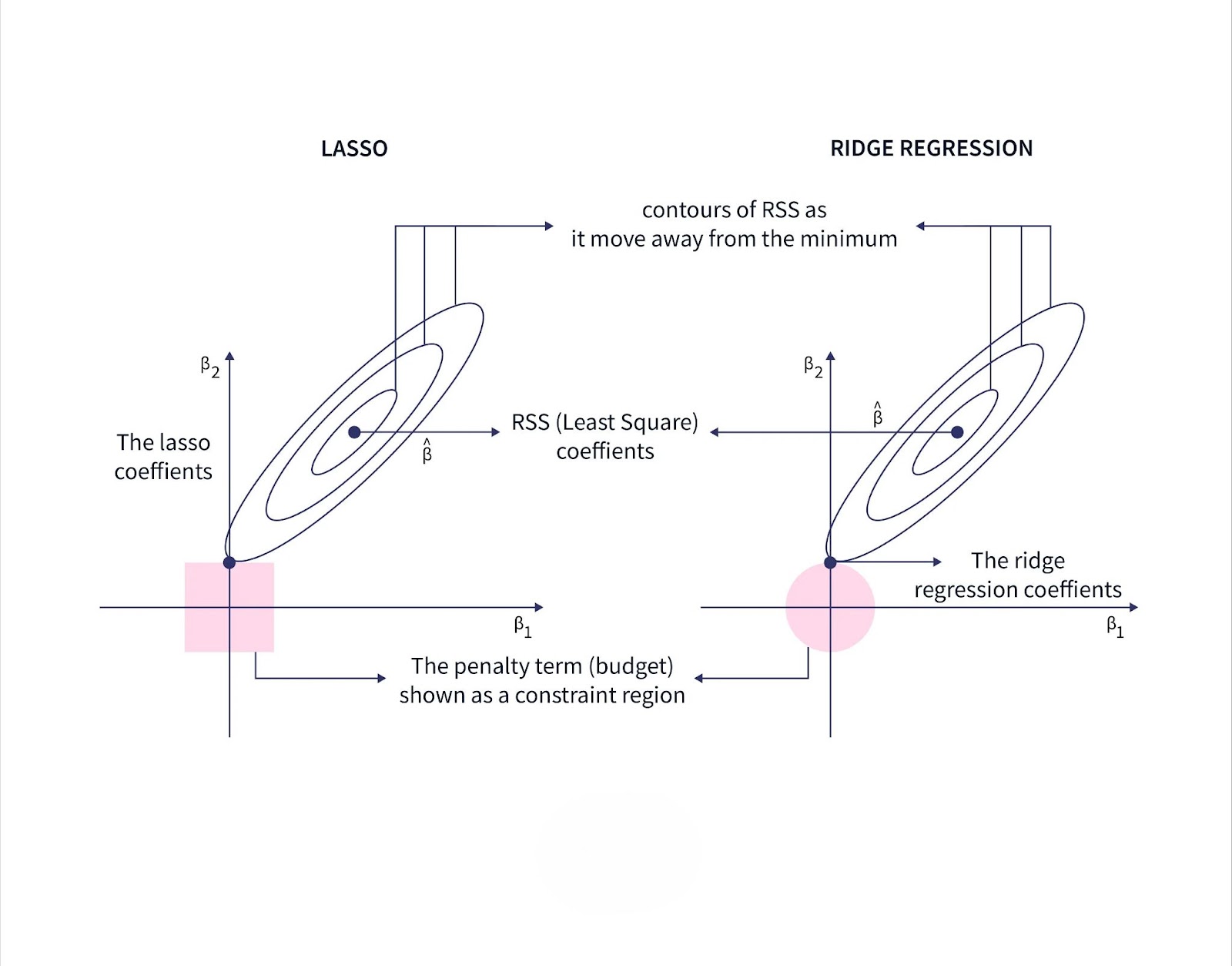
Lasso Regression (L1 Regularization)
Lasso regression, or Least Absolute Shrinkage and Selection Operator, is a type of linear regression that uses L1 regularization. It works by adding the absolute value of the coefficients as a penalty to the cost function:
$$J(\theta) = \frac{1}{n} \sum_{i=1}^{n} (Y_i – \hat{Y}_i)^2 + \lambda \sum_{j=1}^{p} |\theta_j|$$
Where $\lambda$ is the regularization parameter that controls the strength of the penalty.
Lasso regression not only prevents overfitting but also performs feature selection by shrinking some coefficients to zero, effectively removing them from the model. This makes it particularly useful when dealing with high-dimensional datasets with many irrelevant features.
Use Case: In finance, lasso regression can be used to select the most important features for predicting stock prices from a large number of economic indicators.
Ridge Regression (L2 Regularization)
Ridge regression adds L2 regularization by penalizing the squared values of the coefficients. The cost function becomes:
$$J(\theta) = \frac{1}{n} \sum_{i=1}^{n} (Y_i – \hat{Y}_i)^2 + \lambda \sum_{j=1}^{p} \theta_j^2$$
The L2 penalty ensures that all coefficients are small, preventing the model from being overly sensitive to individual features. Unlike lasso regression, ridge regression does not eliminate features but reduces the impact of less important ones, leading to a more stable model.
Use Case: Ridge regression is often used in healthcare for predicting patient outcomes, where all features are important, but their influence needs to be regularized.
Elastic Net Regression
Elastic Net is a hybrid approach that combines the strengths of L1 and L2 regularization. It introduces both penalties into the cost function:
$$J(\theta) = \frac{1}{n} \sum_{i=1}^{n} (Y_i – \hat{Y}_i)^2 + \lambda_1 \sum_{j=1}^{p} |\theta_j| + \lambda_2 \sum_{j=1}^{p} \theta_j^2$$
This method balances feature selection (via L1) and model stability (via L2). Elastic Net is especially useful when dealing with highly correlated features, where lasso alone might struggle.
Use Case: Elastic Net is widely applied in genetics to model the impact of correlated genetic markers on diseases.
Advantages and Disadvantages of Linear Regression
Advantages
- Simplicity and Ease of Interpretation
Linear regression is easy to understand and implement, making it an ideal starting point for machine learning beginners. Its coefficients offer clear insights into the relationships between variables. - Fast Computation
Linear regression is computationally efficient, even with moderately large datasets. This makes it suitable for real-time applications where quick predictions are required. - Applicability to Various Real-World Problems
The model is versatile and finds applications in multiple domains, from finance to healthcare and marketing, demonstrating its practical value.
Disadvantages
- Prone to Overfitting
When the model includes too many features, it risks overfitting the training data, which reduces its ability to generalize to new data. Techniques like regularization help address this limitation. - Sensitive to Outliers
Outliers in the data can have a significant impact on the coefficients, leading to biased predictions. Robust regression methods may be required to handle such cases. - Assumes Linearity
Linear regression assumes a linear relationship between the dependent and independent variables. This limits its applicability in cases where non-linear relationships exist, requiring transformations or non-linear models.
Conclusion
Linear regression is a fundamental algorithm in machine learning, providing a simple yet effective way to model relationships between variables. While it has limitations, mastering linear regression lays the foundation for understanding more advanced techniques such as logistic regression, decision trees, and neural networks. With proper feature selection and regularization, linear regression remains a powerful tool in the data scientist’s arsenal.
References: