Machine learning models are built on a foundation of data and algorithms that process, analyze, and extract insights from that data. Behind the scenes, many of these machine learning algorithms rely heavily on mathematical concepts to function effectively. One of the most important mathematical fields for machine learning is **linear algebra**.
Linear algebra deals with vectors, matrices, and their operations, and forms the backbone of algorithms such as **Principal Component Analysis (PCA)**, **Support Vector Machines (SVM)**, **Neural Networks**, and many more. Without a firm understanding of linear algebra, it becomes difficult to grasp how these algorithms manipulate data, optimize functions, and make predictions.
In this article, we’ll explore the fundamentals of linear algebra, its key operations, and its direct applications in machine learning.
Basics of Linear Algebra
Linear algebra is a field of mathematics that plays a crucial role in many machine learning algorithms. It helps us represent and manipulate data, perform operations like transformations, and understand relationships between data points. In machine learning, linear algebra enables us to work with datasets efficiently, especially when dealing with high-dimensional data. Let’s dive deeper into the fundamental concepts of linear algebra and how they relate to machine learning.
A. Definition of Linear Algebra
At its core, linear algebra deals with vectors, matrices, and linear transformations. It provides the tools to perform operations on these mathematical objects, allowing us to understand how data points relate to each other, how they can be transformed, and how we can use them in machine learning models.
For example, when you have a dataset with multiple features (such as height, weight, or temperature), each of these features can be represented as a vector. These vectors can then be grouped together into a matrix, which represents the entire dataset. Linear algebra allows us to perform various operations on these vectors and matrices, such as scaling, rotations, and transformations, which are essential in building machine learning models.
B. Fundamental Concepts
1. Vectors
A vector is simply an ordered collection of numbers, where each number represents a value in a particular dimension. You can think of a vector as a point in space, where each number in the vector represents a coordinate. Vectors are commonly used in machine learning to represent data points, where each element in the vector corresponds to a specific feature of the data point.
For instance, if you are analyzing weather data, a vector might contain three values: temperature, pressure, and humidity. This vector can be visualized as an arrow pointing to a specific point in 3-dimensional space. Each dimension corresponds to one of the features (temperature, pressure, or humidity), and the values in the vector determine the location of the data point in that space.
Example of a 3-dimensional vector representing temperature, pressure, and humidity:
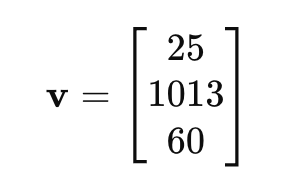
Here:
- 25 represents temperature (in degrees Celsius),
- 1013 represents atmospheric pressure (in hPa),
- 60 represents humidity (in %).
2. Matrices
A matrix is essentially a table of numbers arranged in rows and columns. Each row in a matrix typically represents a data point, and each column represents a feature. In machine learning, matrices are used to represent entire datasets, where the rows are the data points and the columns are the features (or attributes) of the data.
For example, if you have three data points (each representing weather conditions) and three features (temperature, pressure, humidity), the matrix might look like this:
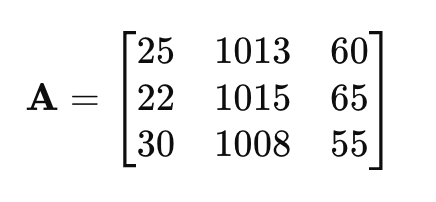
In this matrix:
- Each row corresponds to a different data point (different weather readings),
- Each column corresponds to a different feature (temperature, pressure, or humidity).
Matrices allow us to perform a wide variety of operations such as addition, multiplication, and transformations, which help us manipulate and understand data in machine learning.
3. Scalars
A scalar is just a single number. While vectors and matrices are collections of numbers, a scalar is a single value. In linear algebra, scalars are often used to scale vectors or matrices by multiplying each element by the scalar value.
For example, if we have a scalar 2 and a vector v:
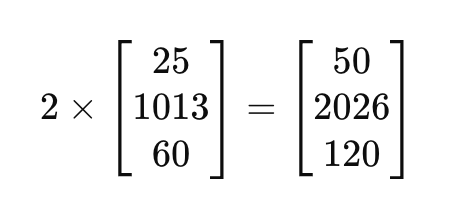
This operation scales the vector by multiplying each element by 2, which can be useful in situations where you want to adjust the magnitude of a vector.
C. Operations in Linear Algebra
Linear algebra includes several key operations that are fundamental to working with vectors and matrices in machine learning. Let’s break down these operations and how they are used.
1. Addition and Subtraction
Addition and subtraction of vectors and matrices are straightforward operations where corresponding elements are added or subtracted. These operations only work if the vectors or matrices have the same dimensions (i.e., the same number of rows and columns).
For example, if we add two vectors:
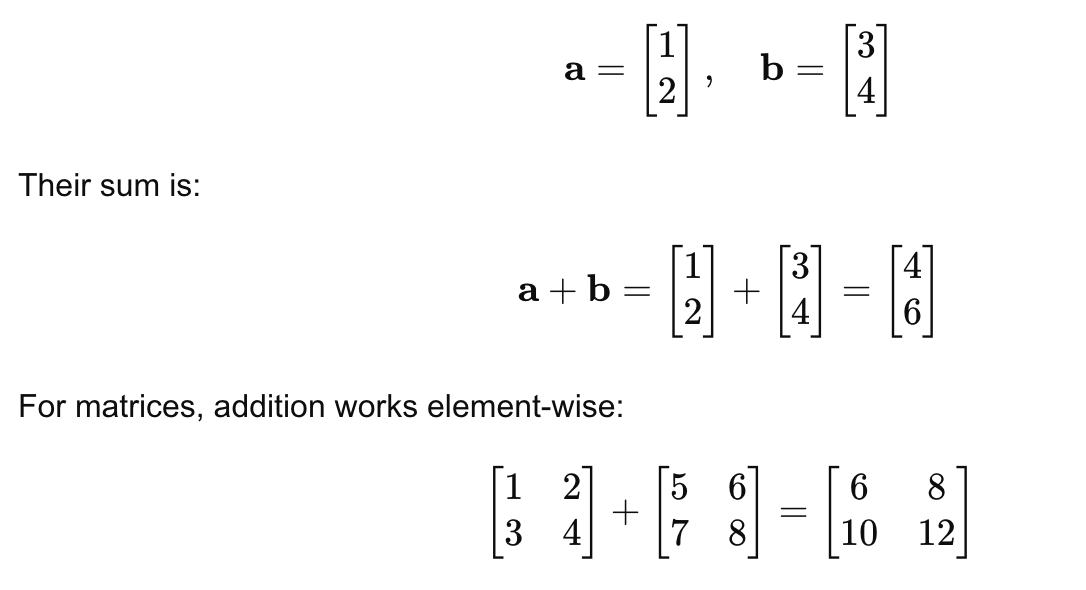
2. Scalar Multiplication
Scalar multiplication involves multiplying each element in a vector or matrix by a scalar. This operation is useful when you want to scale a dataset or modify the magnitude of a vector or matrix.
For instance, if we have the matrix B and scalar 3:
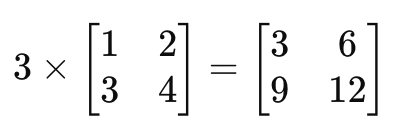
Scalar multiplication is a simple yet powerful operation that is used in many machine learning algorithms, such as gradient descent, where the learning rate is a scalar applied to the gradient vector.
3. Dot Product (Vector Multiplication)
The dot product is an operation between two vectors that results in a single scalar. It is calculated by multiplying corresponding elements from both vectors and summing the results. The dot product is often used to measure the similarity between two vectors in machine learning.
For two vectors a and b:
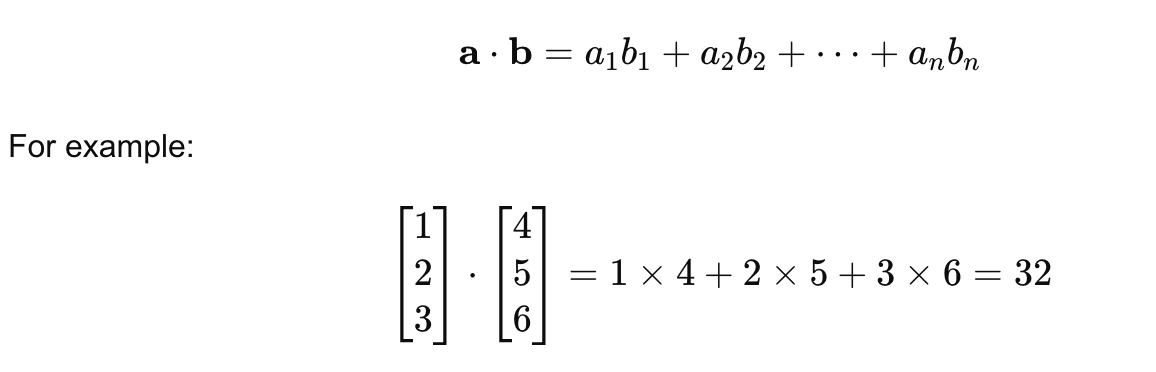
The dot product is commonly used in machine learning tasks such as measuring similarity in text processing or computing weights in neural networks.
4. Cross Product (Vector Multiplication for 3D Vectors)
The cross product is specific to 3D vectors. Unlike the dot product, which results in a scalar, the cross product results in another vector that is perpendicular to the two input vectors. This operation is mostly used in 3D geometry and physics, but it also has applications in certain areas of machine learning involving 3D data.
For vectors a and b:
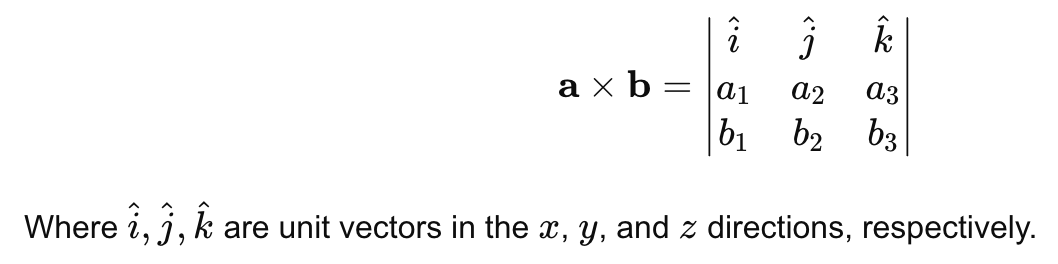
D. Linear Transformations
Linear transformations are one of the most important concepts in linear algebra. A linear transformation is a function that takes a vector and maps it to another vector in the same or a different space. These transformations preserve operations like addition and scalar multiplication. In machine learning, transformations are used to manipulate and represent data in different ways.
1. Definition and Explanation
A linear transformation maps vectors from one space to another, and it can be represented by multiplying a vector by a matrix. For example, applying a transformation to a vector can scale it, rotate it, or translate it in space.
2. Common Linear Transformations in Machine Learning
- Translation: Shifts a point by adding a translation vector to each coordinate. In machine learning, this might be used to shift data points to new locations without changing their relative distances.
- Scaling: Resizes vectors by multiplying them by a scalar or scaling matrix. This is useful when you need to normalize data or adjust the scale of features.
- Rotation: Rotates vectors around an axis, often used in dimensionality reduction techniques like PCA to rotate data to align with principal components.
Matrix Operations
Matrix operations are the cornerstone of linear algebra and are essential for manipulating data in machine learning. They allow us to perform complex calculations efficiently, especially when dealing with large datasets. In this section, we’ll dive into some key matrix operations that are frequently used in machine learning, such as matrix multiplication, transpose, inverse, and determinants.
A. Matrix Multiplication
Matrix multiplication is one of the most fundamental operations in linear algebra. It allows us to combine two matrices to produce a new matrix. This operation is crucial in machine learning algorithms, especially when dealing with transformations, data projections, and neural networks.
Definition of Matrix Multiplication:
Matrix multiplication is only possible when the number of columns in the first matrix matches the number of rows in the second matrix. Given two matrices A and B:

Matrix multiplication is often used in machine learning to perform transformations on data, such as when applying weights to inputs in a neural network or performing dimensionality reduction with PCA.
B. Transpose and Inverse of Matrices
1. Transpose of a Matrix
The transpose of a matrix is obtained by flipping the matrix over its diagonal, which turns the rows of the matrix into columns and vice versa. Given a matrix A, its transpose is denoted by AT.

The transpose operation is often used in machine learning algorithms when working with data, especially in vectorized operations where rows and columns need to be swapped.
2. Inverse of a Matrix
The inverse of a matrix is analogous to the reciprocal of a number. For a square matrix A, its inverse A−1 is the matrix that, when multiplied with A, results in the identity matrix I:
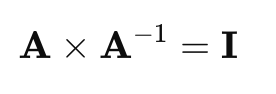
Where I is the identity matrix, a square matrix with ones on the diagonal and zeros elsewhere:
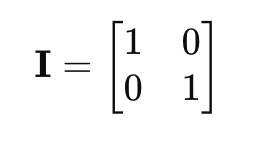
How to Find the Inverse:
- A matrix must be square (i.e., the same number of rows and columns) to have an inverse.
- Not all square matrices have an inverse. A matrix that does not have an inverse is called singular.
Finding the inverse of a matrix can be done through various methods, such as Gaussian elimination, but in machine learning, we often rely on computational tools like Python’s NumPy library to handle matrix inverses efficiently.
In machine learning, matrix inverses are used in algorithms such as linear regression, where the normal equation involves the inverse of the design matrix to compute the optimal weights.
C. Determinants
The determinant is a scalar value that can be computed from a square matrix. It provides important information about the matrix, such as whether the matrix has an inverse or not. If the determinant of a matrix is zero, the matrix is singular and does not have an inverse.
For a 2×2 matrix A:

Importance of Determinants:
- The determinant helps determine if a matrix is invertible. If det A≠0, the matrix is invertible; otherwise, it is singular.
- Determinants are used in solving systems of linear equations, in calculating volumes, and in understanding the properties of transformations applied to vectors.
Determinants, though not always computed directly in machine learning, play a role in understanding the invertibility of matrices used in algorithms like linear regression and matrix factorizations.
Eigenvalues and Eigenvectors
In linear algebra, eigenvalues and eigenvectors are important concepts that play a crucial role in machine learning, particularly in algorithms that involve dimensionality reduction, such as Principal Component Analysis (PCA). Understanding eigenvalues and eigenvectors allows us to analyze the structure of matrices and how they transform data.
A. Definition and Significance
Eigenvalues
An eigenvalue is a scalar that indicates how much a corresponding eigenvector is stretched or compressed during a linear transformation. It represents the factor by which the eigenvector is scaled when a matrix is applied to it.
Eigenvectors
An eigenvector is a non-zero vector that remains in the same direction after a linear transformation is applied to it by a matrix, though its magnitude may be scaled. Mathematically, if A is a square matrix, an eigenvector v, and its corresponding eigenvalue λ satisfy the equation:
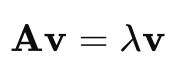
Here:
- A is the matrix,
- v is the eigenvector,
- λ is the eigenvalue.
In other words, multiplying the matrix A by the eigenvector v results in a scaled version of the eigenvector, where the scaling factor is the eigenvalue λ.
Geometric Interpretation
The geometric interpretation of eigenvectors and eigenvalues is that eigenvectors indicate directions in the data that are invariant under the transformation applied by the matrix. The corresponding eigenvalue tells us how much the eigenvector is stretched or compressed in that direction.
For example, in a 2D plane, if a matrix transforms a vector but keeps its direction intact while only scaling it by some factor, that vector is an eigenvector, and the scaling factor is its eigenvalue.
B. Applications in Machine Learning
Eigenvalues and eigenvectors have several key applications in machine learning, particularly in techniques that involve data transformation or dimensionality reduction.
1. Dimensionality Reduction (Principal Component Analysis – PCA)
Principal Component Analysis (PCA) is a widely used technique for reducing the dimensionality of large datasets while retaining most of the important information. PCA works by finding the eigenvectors and eigenvalues of the covariance matrix of the data. The eigenvectors represent the principal components, which are the directions in which the data varies the most, and the eigenvalues indicate how much variance there is along each principal component.
Steps involved in PCA:
- Compute the covariance matrix of the dataset.
- Perform eigen decomposition to obtain eigenvalues and eigenvectors of the covariance matrix.
- The eigenvectors corresponding to the largest eigenvalues are chosen as the principal components.
- Project the original data onto these principal components, reducing the number of features while retaining most of the variance.
By focusing on the eigenvectors with the largest eigenvalues, PCA allows us to reduce the complexity of the data while preserving as much useful information as possible. This is particularly useful in high-dimensional datasets like image processing or text analysis, where reducing the number of dimensions can significantly improve model performance and reduce computation costs.
2. Graph-based Algorithms
Eigenvalues and eigenvectors are also used in spectral clustering, a graph-based algorithm that groups data points into clusters by analyzing the eigenvalues and eigenvectors of the Laplacian matrix derived from the data. Spectral clustering is often used in community detection within networks, such as social media graphs, where nodes represent users and edges represent relationships.
The key idea is to use the eigenvectors of the Laplacian matrix to transform the original high-dimensional data into a lower-dimensional space, where traditional clustering techniques like k-means can be applied more effectively.
3. Matrix Factorization
In matrix factorization techniques, such as those used in recommender systems, eigenvalues and eigenvectors help decompose a matrix into lower-dimensional latent factors. For example, in collaborative filtering, matrices representing user-item interactions are decomposed into matrices representing latent features (e.g., user preferences and item characteristics). These latent features are used to make predictions for unseen data, such as recommending new movies or products to users.
C. Eigen Decomposition
Eigen decomposition is the process of finding the eigenvalues and eigenvectors of a square matrix. Given a matrix A, eigen decomposition can be represented as:
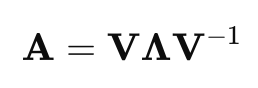
Where:
- V is the matrix of eigenvectors,
- Λ is the diagonal matrix of eigenvalues,
- V−1 is the inverse of the eigenvector matrix.
Eigen decomposition allows us to break down a matrix into its fundamental components, which can be useful for analyzing the matrix’s properties or simplifying complex calculations.
Spectral Theorem
For certain matrices, such as symmetric matrices, eigen decomposition can be simplified. The spectral theorem states that any real symmetric matrix can be diagonalized using an orthogonal matrix, meaning it can be represented as:
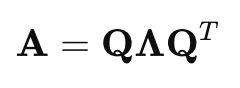
Where Q is an orthogonal matrix (its columns are orthogonal eigenvectors), and Λ is a diagonal matrix of eigenvalues.
Summary of Eigenvalues and Eigenvectors in Machine Learning
- Eigenvalues represent how much a corresponding eigenvector is scaled during a transformation.
- Eigenvectors represent directions in the data that are preserved under the transformation.
- These concepts are used in various machine learning applications, such as dimensionality reduction (PCA), spectral clustering, and matrix factorization.
Eigen decomposition provides a powerful tool for understanding and simplifying matrix operations, and it is frequently used in machine learning for transforming and analyzing data.
Solving Linear Systems
In machine learning and many other fields, it’s common to encounter linear systems of equations, where you have multiple equations and unknown variables. Linear algebra provides several methods to solve these systems, and understanding how to efficiently solve them is important for tasks like model optimization and predictions in machine learning.
A linear system is typically written in the form:
Ax=b
Where:
- A is a matrix representing the coefficients of the linear equations,
- x is a vector of unknown variables,
- b is a vector representing the results of each equation.
In this system, the goal is to find x, the solution vector that satisfies all the equations. Let’s explore different methods to solve linear systems.
A. Gaussian Elimination
Gaussian elimination is one of the most basic and widely used methods for solving linear systems. It transforms a matrix into row echelon form (or further into reduced row echelon form) using elementary row operations. Once the matrix is in this form, the solution to the system can be found by back substitution.
Steps of Gaussian Elimination:
- Forward Elimination: The matrix is manipulated to create zeros below the diagonal, converting it into an upper triangular matrix.
- Back Substitution: Once the matrix is in upper triangular form, we solve for the unknowns starting from the last row and moving upwards.
Example:
Consider the system of equations:
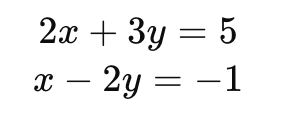
We can represent this system as a matrix equation:
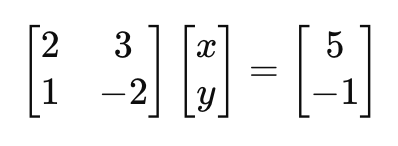
Using Gaussian elimination, we first eliminate x from the second row by multiplying the first row by 0.5 and subtracting it from the second row:
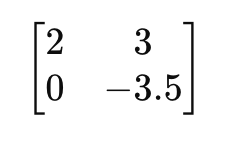
Now, solve for y by dividing the second row by -3.5 and then substitute back into the first equation to find x.
Advantages of Gaussian Elimination:
- Simple and easy to understand.
- Can be applied to any square system of linear equations.
Disadvantages:
- Computationally expensive for large matrices.
- Sensitive to numerical errors, especially when pivoting is not used.
B. LU Decomposition
LU decomposition is a method that decomposes a matrix A into the product of two simpler matrices: a lower triangular matrix L and an upper triangular matrix U. This makes solving linear systems more efficient, especially when multiple systems with the same coefficient matrix need to be solved.
LU Decomposition:
For a matrix A, LU decomposition is:
A=LU
Where:
- L is a lower triangular matrix (with ones on the diagonal),
- U is an upper triangular matrix
Once the matrix A is decomposed into L and U, the system Ax=b becomes:
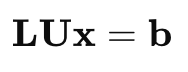
This can be solved in two steps:
- Solve Ly= b for y using forward substitution.
- Solve Ux= y for x using back substitution.
Example:
Consider the matrix:
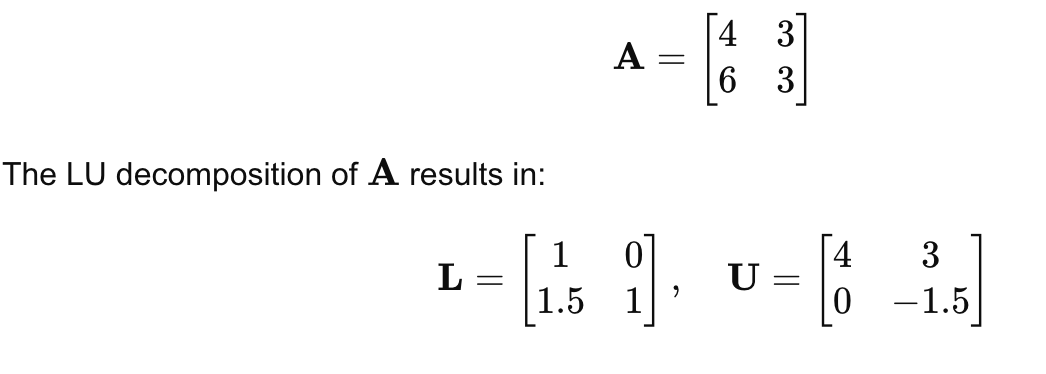
We then solve the system by first finding y and then x.
Advantages of LU Decomposition:
- Efficient for solving multiple systems with the same coefficient matrix A.
- Reduces the complexity of solving large systems.
Disadvantages:
- LU decomposition may not exist for every matrix without row interchanges (pivoting may be required).
- It is not as efficient for small systems compared to direct methods like Gaussian elimination.
C. QR Decomposition
QR decomposition is another factorization method where a matrix A is decomposed into the product of an orthogonal matrix Q and an upper triangular matrix R:

QR decomposition is often used to solve least-squares problems, where the goal is to minimize the difference between predicted and actual values. This method is particularly useful when the system is overdetermined (more equations than unknowns).
Application in Least-Squares Problems:
In a least-squares problem, the system Ax=b may not have an exact solution. The goal is to find x that minimizes the squared error:
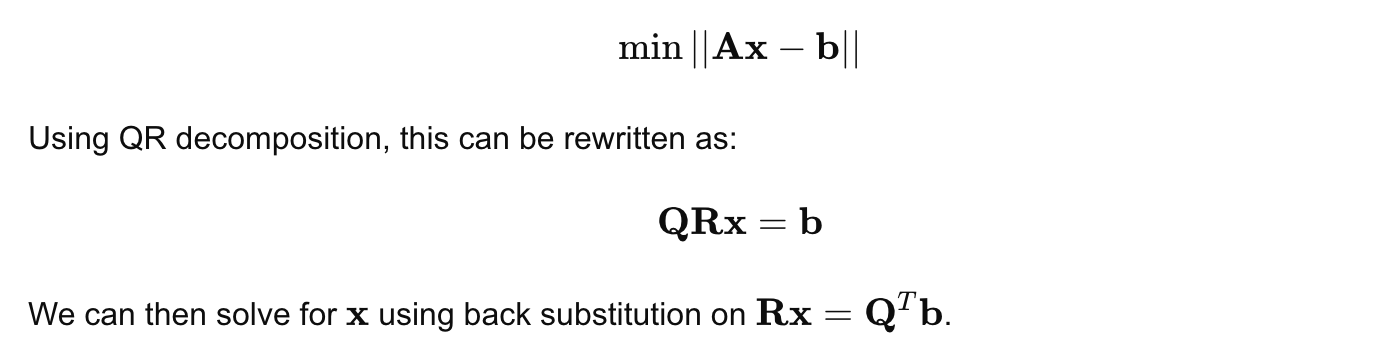
Advantages of QR Decomposition:
- Provides a stable and efficient way to solve least-squares problems.
- Handles overdetermined systems well.
Disadvantages:
- More complex than LU decomposition or Gaussian elimination for smaller systems.
- Computationally more expensive than simpler methods for small problems.
Applications of Linear Algebra in Machine Learning
Linear algebra is the backbone of many machine learning algorithms. Whether it’s handling large datasets, transforming data, or optimizing model parameters, linear algebra plays a vital role in making machine learning efficient and scalable. In this section, we will explore how key linear algebra concepts are applied in popular machine learning techniques and algorithms.
A. Principal Component Analysis (PCA)
Principal Component Analysis (PCA) is a popular dimensionality reduction technique used to simplify high-dimensional datasets by transforming them into a lower-dimensional space while preserving the most important features of the data. The goal of PCA is to reduce the number of features (dimensions) while retaining as much of the original variance as possible.
How PCA Works:
- Calculate the Covariance Matrix: The covariance matrix is computed to understand how different features of the dataset are correlated.
- Eigen Decomposition: The covariance matrix is decomposed into its eigenvalues and eigenvectors. The eigenvectors (also known as principal components) indicate the directions in which the data varies the most, while the eigenvalues represent the magnitude of variance in those directions.
- Select Principal Components: The eigenvectors corresponding to the largest eigenvalues are selected as the principal components. These are the directions along which the data can be projected to achieve maximum variance with fewer dimensions.
- Project Data onto Principal Components: The original data is projected onto the selected principal components, resulting in a lower-dimensional dataset that captures the most important information.
Example of PCA in Action:
Consider a dataset with 100 features. Using PCA, we can reduce the number of features to, say, 10, while retaining 95% of the variance in the original data. This is particularly useful when dealing with high-dimensional data like images, where reducing the number of pixels (features) can make models more efficient.
Applications of PCA:
- Data Visualization: PCA helps visualize high-dimensional data by reducing it to 2 or 3 dimensions, making it easier to plot and interpret.
- Noise Reduction: PCA can filter out noise from the data by ignoring small eigenvalues that represent less significant variations.
- Speeding Up Algorithms: Reducing the number of dimensions in the data makes algorithms like logistic regression and support vector machines run faster.
B. Singular Value Decomposition (SVD)
Singular Value Decomposition (SVD) is another matrix factorization technique used in machine learning to break down a matrix into three component matrices: U, Σ, and VT. This decomposition allows us to analyze and manipulate data more effectively.
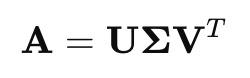
Where:
- A is the original matrix,
- U is the matrix of left singular vectors,
- Σ is the diagonal matrix of singular values (which are the square roots of the eigenvalues of ATA
- VT is the matrix of right singular vectors.
Applications of SVD:
- Latent Semantic Analysis (LSA): SVD is used in natural language processing (NLP) to analyze relationships between terms and documents. It helps reduce dimensionality while capturing the underlying structure of the data.
- Recommender Systems: In collaborative filtering, SVD is used to decompose user-item interaction matrices, identifying latent factors that explain user preferences.
- Image Compression: SVD is used in image compression by keeping only the most significant singular values, which allows for a reduced representation of the image while preserving its core structure.
C. Linear Regression
Linear regression is a simple yet powerful algorithm for predicting a continuous target variable based on one or more input features. Linear algebra is heavily used in the matrix formulation of linear regression, which helps compute the optimal model parameters (weights).
Matrix Formulation of Linear Regression:
In matrix form, the linear regression model can be written as:
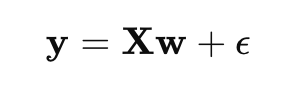
Where:
- y is the vector of target values,
- X is the design matrix (each row is a data point, and each column is a feature),
- w is the vector of weights (parameters) we want to learn,
- ϵ is the error term.
To find the optimal weights w, we use the normal equation:
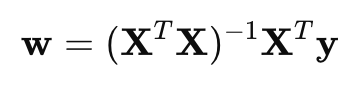
This equation uses matrix operations like transpose, multiplication, and inverse to compute the parameters that minimize the squared error between the predicted and actual target values.
Applications of Linear Regression:
- Predictive Modeling: Linear regression is used in finance, healthcare, and economics to predict outcomes like stock prices, medical expenses, or housing prices.
- Trend Analysis: Linear regression is used to analyze trends and relationships between variables, such as how education level affects income.
D. Support Vector Machines (SVM)
Support Vector Machines (SVM) is a powerful classification algorithm that uses linear algebra concepts to find the optimal boundary (hyperplane) that separates data points from different classes.
The Role of Linear Algebra in SVM:
- Kernel Trick: When data is not linearly separable, SVM uses the kernel trick to map data points into a higher-dimensional space, where a linear boundary can be found. This involves calculating dot products between data points in this higher-dimensional space, which is a core linear algebra operation.
- Maximizing the Margin: SVM aims to find the hyperplane that maximizes the margin between data points from different classes. The optimization problem is formulated as a quadratic programming problem that involves matrix operations.
Applications of SVM:
- Image Classification: SVM is commonly used in tasks like handwritten digit recognition or facial detection.
- Text Categorization: SVM is used to classify documents into categories, such as spam detection or sentiment analysis.
E. Neural Networks
Neural networks rely heavily on linear algebra for forward propagation, backward propagation, and optimization. In a neural network, the inputs, weights, and activations are represented as matrices, and the operations between layers are matrix multiplications.
The Role of Linear Algebra in Neural Networks:
- Forward Propagation: In each layer of the network, the inputs are multiplied by the weights and passed through an activation function. This involves matrix multiplications and element-wise operations.
- Backpropagation: During training, gradients of the loss function with respect to the weights are calculated using linear algebra operations like transposes and multiplications. These gradients are then used to update the weights in the network.
Applications of Neural Networks:
- Deep Learning: Neural networks, especially deep learning models like convolutional neural networks (CNNs) and recurrent neural networks (RNNs), are used in image recognition, natural language processing, and autonomous driving.
- Optimization: Linear algebra is used in optimization algorithms like gradient descent, where the goal is to minimize a loss function by iteratively updating the weights of the network.
Conclusion
Linear algebra is an essential tool in machine learning, underpinning many of the algorithms and techniques used today. From vector and matrix operations to eigenvalues, eigenvectors, and matrix decompositions, linear algebra enables us to manipulate, analyze, and transform data efficiently. Without these fundamental concepts, tasks like dimensionality reduction, optimizing models, and even building neural networks would be extremely difficult.
In this article, we’ve explored:
- The basics of linear algebra, including vectors, matrices, and key operations like matrix multiplication, scalar multiplication, and dot products.
- How matrix operations like transpose, inverse, and determinants help in solving systems of linear equations, which are at the heart of many machine learning models.
- The importance of eigenvalues and eigenvectors for understanding linear transformations and their applications in techniques like Principal Component Analysis (PCA).
- Methods for solving linear systems, such as Gaussian elimination, LU decomposition, and QR decomposition, which are crucial for optimizing machine learning algorithms.
- Applications of linear algebra in core machine learning algorithms, including PCA, SVD, linear regression, SVM, and neural networks.
Understanding linear algebra not only helps you grasp the mechanics of these machine learning algorithms but also gives you the ability to apply, adapt, and optimize them for real-world problems. Whether it’s performing dimensionality reduction with PCA, training a neural network, or optimizing weights in a regression model, mastering linear algebra equips you with the tools to excel in machine learning.
For anyone looking to deepen their understanding of machine learning, a strong grasp of linear algebra is a must. It forms the foundation upon which more complex mathematical and algorithmic concepts are built, and it will remain relevant as the field of machine learning continues to evolve.


