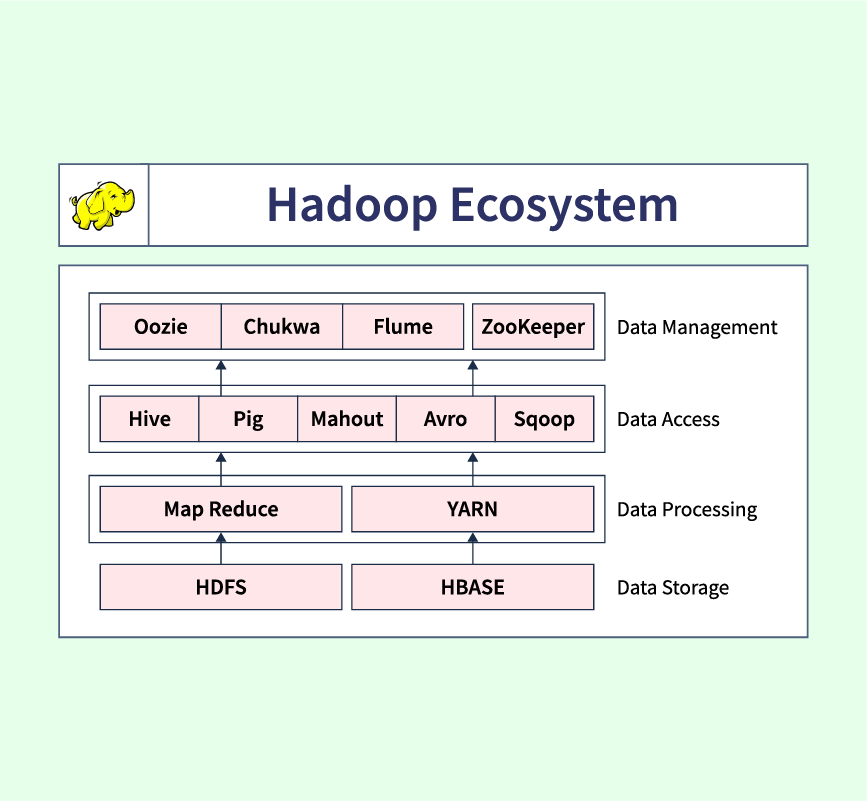
K-Means Clustering is an unsupervised learning algorithm used to group data points into distinct clusters based on similarity. It’s widely applied in tasks like market segmentation, image compression, and anomaly detection, known for its simplicity, efficiency, and scalability in handling large datasets.
What is K-Means Clustering?
K-Means Clustering is an unsupervised learning algorithm that divides a dataset into K distinct clusters. Each cluster contains data points that are more similar to each other than to points in other clusters. The algorithm aims to minimize intra-cluster variance (the distance between points within a cluster) and maximize inter-cluster separation (the distance between clusters).
K-Means operates on the principle of centroids, where each centroid represents the center of a cluster. The algorithm starts by assigning random centroids, then assigns each data point to the nearest centroid based on a distance metric like Euclidean distance. After all points are assigned to clusters, the centroids are updated by calculating the mean of the assigned points. This process repeats until the centroids stabilize.
Real-World Examples:
- Market Segmentation: Businesses use K-Means to group customers with similar purchasing behavior, allowing them to tailor marketing strategies.
- Image Compression: K-Means reduces the number of unique colors in an image by grouping similar pixels into clusters, compressing the image.
K-Means clustering is widely used due to its ease of implementation and ability to handle large datasets efficiently.
Objective of K-Means Clustering
The objective of K-Means clustering is to create clusters that minimize the variance within each cluster while maximizing the differences between clusters. This means that the algorithm aims to make the data points in each cluster as similar as possible while ensuring that each cluster remains distinct from the others.
Key Objectives:
- Minimizing Intra-Cluster Distance: The algorithm minimizes the variance within each cluster by grouping similar data points.
- Maximizing Inter-Cluster Distance: K-Means ensures that different clusters are as distinct as possible, making the segmentation clear.
Choosing the correct number of clusters (K) is crucial for balancing these objectives. An appropriate K value results in accurate clustering, while a poorly chosen K can lead to either over-clustering or under-clustering. Several methods, such as the Elbow Method and the Silhouette Score, help in determining the optimal K value.
How K-Means Clustering Works
K-Means clustering works through an iterative process, refining the clusters step-by-step.
Step 1: Initialization of Centroids
The algorithm begins by selecting K random centroids as the initial cluster centers. These centroids can be selected randomly from the dataset or generated randomly in the feature space. These centroids represent the starting points for cluster formation.
Step 2: Assignment of Points to the Nearest Centroid
Each data point is assigned to the nearest centroid based on a distance metric, usually Euclidean distance. This step ensures that each point is grouped with other similar points, forming the initial clusters.
Step 3: Update of Centroids
Once all points are assigned to clusters, the algorithm recalculates the centroids by taking the mean of the data points in each cluster. These updated centroids represent the new cluster centers, and the assignment process begins again.
Step 4: Iterative Process until Convergence
Steps 2 and 3 are repeated until the centroids stop moving or the change in their positions is negligible. This indicates that the algorithm has converged and the clusters are stable. The final clusters are then outputted as the result of the K-Means algorithm.
This iterative process continues until the clusters are well-defined, ensuring that intra-cluster distances are minimized and inter-cluster distances are maximized.
Challenges and Considerations in K-Means Clustering
Despite its popularity, K-Means clustering faces several challenges and limitations that can affect its performance.
1. Random Initialization and Local Minima
The algorithm’s reliance on random initialization can lead to local minima, where the solution is suboptimal. This happens because different initial centroids can lead to different final clusters. Running the algorithm multiple times with different initializations can help mitigate this issue.
2. Choosing the K Value
Determining the optimal number of clusters (K) is a significant challenge. An incorrect K value can lead to over-clustering or under-clustering, where either too many small clusters or too few generalized clusters are formed. Methods like the Elbow Method or the Silhouette Score are commonly used to help identify the best K value.
3. Sensitivity to Outliers
K-Means is highly sensitive to outliers, which can distort the cluster assignments. Outliers can affect the position of centroids, leading to inaccurate clusters.
- Solution: Preprocessing the data by identifying and removing outliers or using K-medoids, a variant of K-Means that is less sensitive to outliers, can improve clustering performance.
By understanding these challenges, it’s easier to apply K-Means clustering effectively, ensuring accurate and meaningful clusters.
Choosing the Optimal Number of Clusters (K)
Choosing the optimal number of clusters (K) is a critical step in K-Means clustering. If K is too small, the algorithm may overgeneralize, grouping distinct data points into the same cluster. Conversely, if K is too large, the algorithm may overfit the data, creating too many small, meaningless clusters.
The Elbow Method
The Elbow Method is a popular approach for determining the optimal K value. The method involves plotting the within-cluster sum of squares (WCSS) for different values of K. The “elbow” point on the plot indicates the K value at which the reduction in WCSS slows down, suggesting that adding more clusters beyond this point provides diminishing returns.
Silhouette Score
The Silhouette Score measures the quality of the clusters by evaluating how similar data points are within a cluster compared to other clusters. A high silhouette score indicates that the clusters are well-separated and that data points are appropriately grouped.
Both methods are commonly used to determine the most appropriate number of clusters for a dataset, ensuring that the final model balances accuracy and simplicity.
Implementation of K-means Clustering in Python
In this section, we will walk through two Python examples that demonstrate how to implement K-means clustering. One will use a simple custom dataset, while the other will utilize a real-world dataset.
Example 1: Simple Custom Dataset
Step 1: Import Libraries
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeansStep 2: Create Custom Dataset
We’ll use make_blobs to generate a custom dataset with three clusters.
# Generating a custom dataset with 3 clusters
X, y = make_blobs(n_samples=300, centers=3, cluster_std=0.60, random_state=0)Step 3: Initialize Random Centroids
The KMeans class automatically handles centroid initialization. We’ll set the number of clusters (K) to 3.
kmeans = KMeans(n_clusters=3)Step 4: Define and Calculate Euclidean Distance
In the K-means algorithm, Euclidean distance is used to calculate the distance between each point and the centroids. This is done internally by the KMeans class in scikit-learn.
Step 5: Assign and Update Cluster Centers
Once the distances are calculated, the algorithm assigns points to the nearest centroid and updates the centroid based on the mean of the points assigned to that cluster.
kmeans.fit(X)
y_kmeans = kmeans.predict(X)Step 6: Predict and Plot Clusters
Finally, we can visualize the clusters.
plt.scatter(X[:, 0], X[:, 1], c=y_kmeans, s=50, cmap='viridis')
centers = kmeans.cluster_centers_
plt.scatter(centers[:, 0], centers[:, 1], c='red', s=200, alpha=0.75)
plt.show()The output will show three clusters, with the cluster centers marked in red.
Example 2: Real-World Dataset
Step 1: Load Dataset
We will use the Iris dataset, a well-known dataset for clustering tasks.
from sklearn import datasets
iris = datasets.load_iris()
X = iris.dataStep 2: Apply Elbow Method for Optimal K
We can use the Elbow Method to determine the best number of clusters by plotting the within-cluster sum of squares (WCSS) for different K values.
wcss = []
for i in range(1, 11):
kmeans = KMeans(n_clusters=i, init='k-means++', max_iter=300, n_init=10, random_state=0)
kmeans.fit(X)
wcss.append(kmeans.inertia_)
plt.plot(range(1, 11), wcss)
plt.title('Elbow Method')
plt.xlabel('Number of clusters')
plt.ylabel('WCSS')
plt.show()Step 3: Build K-Means Model
Based on the Elbow Method, we’ll choose K=3.
kmeans = KMeans(n_clusters=3, init='k-means++', max_iter=300, n_init=10, random_state=0)
y_kmeans = kmeans.fit_predict(X)Step 4: Predict and Visualize Clusters
We can visualize the clustering results using a scatter plot, just as we did in the first example.
plt.scatter(X[y_kmeans == 0, 0], X[y_kmeans == 0, 1], s=100, c='red', label='Cluster 1')
plt.scatter(X[y_kmeans == 1, 0], X[y_kmeans == 1, 1], s=100, c='blue', label='Cluster 2')
plt.scatter(X[y_kmeans == 2, 0], X[y_kmeans == 2, 1], s=100, c='green', label='Cluster 3')
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s=300, c='yellow', label='Centroids')
plt.title('Clusters of Iris Data')
plt.legend()
plt.show()Step 5: Evaluate the Model
Finally, we can evaluate the model using the Silhouette Score to measure the quality of the clustering.
from sklearn.metrics import silhouette_score
score = silhouette_score(X, y_kmeans)
print('Silhouette Score:', score)The Silhouette Score will give us an indication of how well the clusters are separated.
Applications of K-means Clustering
K-means clustering is widely used in various industries due to its simplicity and efficiency. Some common applications include:
1. Customer Segmentation
In marketing, K-means clustering is used to group customers based on behavior, preferences, or demographics. This allows companies to tailor marketing strategies to specific segments, improving targeting and engagement.
2. Image Compression
K-means is frequently used in image processing for compression purposes. By clustering pixels with similar colors, the algorithm reduces the number of unique colors in an image, leading to significant size reductions without much visible loss in quality.
3. Anomaly Detection
K-means is applied in anomaly detection to identify outliers or abnormal patterns in data. For example, in network security, K-means can detect unusual traffic patterns that may indicate a security breach.
4. Document Clustering
In natural language processing (NLP), K-means is used to cluster documents based on similarity, making it useful for organizing large collections of documents or performing topic modeling.
Advantages and Disadvantages of K-means Clustering
Advantages
- Simplicity: K-means is easy to implement and understand, making it a go-to algorithm for many clustering tasks.
- Scalability: K-means scales well with large datasets, handling thousands of data points efficiently.
Disadvantages
- Sensitivity to Outliers: K-means is sensitive to outliers, which can distort the cluster assignments.
- Difficulty with Varying Densities: K-means struggles with clusters of varying sizes and densities, often leading to suboptimal cluster assignments.
- Fixed K Value: The requirement to specify K beforehand can lead to issues if the chosen K value is not optimal.
Conclusion
K-means clustering is one of the most popular clustering algorithms in machine learning, known for its simplicity and efficiency. By dividing data into K clusters based on similarity, it offers valuable insights for tasks such as customer segmentation, image compression, and anomaly detection.
However, K-means is not without its challenges. It requires specifying the number of clusters upfront and is sensitive to outliers and variations in cluster density. Despite these limitations, it remains widely used, particularly for large datasets due to its scalability.
In the future, improvements in techniques like K-means++ and hybrid models may further enhance its performance, making it an even more powerful tool for data segmentation and pattern recognition.
References: