In machine learning, models make predictions based on data. However, they must generalize beyond the training data to be effective. This is where inductive bias comes into play. Inductive bias refers to the assumptions a model makes to generalize from the observed data, guiding learning algorithms toward specific predictions.
What is Inductive Bias?
Inductive bias is the set of assumptions or preferences that a learning algorithm uses to make predictions beyond the data it has been trained on. Without inductive bias, machine learning algorithms would be unable to generalize from training data to unseen situations, as the possible hypotheses or models could be infinite.
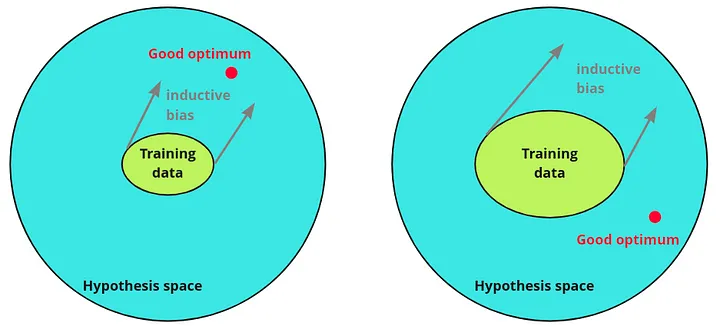
Sources: Medium
For instance, in a classification problem, if the model is trained on data that suggests a linear relationship between features and outcomes, the inductive bias of the model might favor a linear hypothesis. This preference guides the model to choose simpler, linear relationships rather than complex, nonlinear ones, even if such relationships might exist in the data.
Examples:
- Inductive bias in decision trees: A preference for shorter trees with fewer splits.
- Inductive bias in linear regression: The assumption that the data follows a linear trend.
These biases help the algorithm make predictions more efficiently, even in situations where there is uncertainty.
Types of Inductive Bias
Inductive bias can be categorized into different types based on the constraints or preferences that guide a learning algorithm:
1. Language Bias
Language bias refers to the constraints placed on the hypothesis space, which defines the types of models a learning algorithm can consider. For instance, linear regression models assume a linear relationship between variables, thereby limiting the hypothesis space to linear functions.
2. Search Bias
Search bias refers to the preferences that an algorithm has when selecting hypotheses from the available options. For example, many algorithms prefer simpler models over complex ones due to the principle of Occam’s Razor, which suggests that simpler models are more likely to generalize well.
3. Algorithm-Specific Biases
Certain algorithms have specific biases based on their structure:
- Linear Models: Assume that the data has linear relationships.
- k-Nearest Neighbors (k-NN): Assumes that similar data points exist in close proximity.
- Decision Trees: Typically biased towards choosing splits that result in the most homogeneous subgroups.
Each type of inductive bias impacts how an algorithm approaches the learning process, guiding it towards certain types of models and predictions.
Inductive Biases in Machine Learning Algorithms
Different machine learning algorithms incorporate distinct inductive biases that shape their learning and prediction processes:
1. Bayesian Models
In Bayesian models, prior knowledge is treated as a form of inductive bias. This prior helps the model make predictions even when the available data is limited. The model updates its predictions as new data becomes available, balancing the prior with the likelihood of the observed data.
2. k-Nearest Neighbors (k-NN)
The inductive bias in k-NN lies in its assumption that similar data points are located close to each other in feature space. As a result, k-NN tends to perform well in datasets where locally similar data points share the same classification.
3. Linear Regression
The inductive bias in linear regression is the assumption that the relationship between input variables and output is linear. This bias works well for datasets with linear patterns but may fail to capture more complex, nonlinear relationships.
4. Logistic Regression
Logistic regression assumes a linear decision boundary between classes, which makes it effective for binary classification tasks with linearly separable data.
Each of these algorithms leverages specific inductive biases to balance accuracy and generalization, ensuring that the model doesn’t overfit or underfit the training data.
Importance of Inductive Bias
Inductive bias plays a critical role in ensuring that machine learning models can generalize effectively from training data to unseen data. Without bias, a learning algorithm would have to consider every possible hypothesis, which is computationally infeasible.
Generalization and Bias-Variance Trade-off:
Inductive bias helps balance the bias-variance trade-off. A model with too much bias may underfit the data, resulting in poor predictions on unseen data. Conversely, a model with too little bias may overfit, capturing noise in the training data but failing to generalize.
The goal is to find the right balance: enough inductive bias to ensure generalization, but not so much that the model becomes too rigid. This is especially important in real-world machine learning tasks, where data is often noisy and incomplete, and making assumptions about the data is necessary for the model to make reasonable predictions.
Challenges and Considerations in Inductive Bias
While inductive bias is essential for guiding machine learning models, it comes with challenges:
Overfitting
When the inductive bias is too weak, the model may overfit the training data by learning noise rather than meaningful patterns. Overfitting occurs when the model fits the training data too closely, resulting in poor performance on unseen data.
Underfitting
Conversely, if the inductive bias is too strong, the model may underfit the data, failing to capture important patterns. This can lead to overly simplistic models that don’t perform well on either the training or test data.
Finding the Right Balance
Finding the optimal level of inductive bias requires tuning the model’s complexity and flexibility. For instance, regularization techniques can help control the degree of bias by penalizing overly complex models, thus encouraging generalization without overfitting.
Machine learning practitioners must carefully consider the trade-off between bias and flexibility to create models that are both accurate and generalizable.
Conclusion
Inductive bias is a fundamental concept in machine learning that guides models in making predictions beyond the training data. By introducing assumptions about the data, inductive bias allows algorithms to generalize and learn more efficiently. However, the strength of the bias must be carefully balanced to avoid underfitting or overfitting the model. Understanding the role of inductive bias in different machine learning algorithms is crucial for selecting the right model for a given task. Further exploration of bias-variance trade-offs will lead to better-performing models in real-world applications.
References:
- What is Inductive Bias in Machine Learning | Saturn Cloud Blog
- What is the Inductive bias in Machine Learning? | by David Kim(Changhun Kim) | Medium


