ETL (Extract, Transform, Load) plays a pivotal role in data-driven decision-making. It serves as the backbone of data integration, allowing businesses to consolidate and process data efficiently. By enabling smooth data flow from various sources to target systems, ETL ensures that organizations can leverage their data for meaningful insights and analytics.
What is ETL?
ETL stands for Extract, Transform, Load, a process used to collect data from various sources, convert it into a usable format, and load it into a target system like a data warehouse or data lake. The ETL process ensures that disparate data sources are integrated into a unified system for accurate analysis and reporting.
Key Phases of ETL
- Extract: Data is retrieved from multiple sources, such as databases, spreadsheets, and APIs.
- Transform: The extracted data undergoes cleansing, validation, and formatting to meet the target system’s requirements.
- Load: The transformed data is moved into the target storage system, where it becomes accessible for analytics and reporting tools.
ETL plays a significant role in data integration workflows, making sure that inconsistent and incomplete data is cleaned and aligned. Its relevance in business intelligence (BI) is critical because high-quality, reliable data is essential for generating actionable insights.
Today, ETL is used extensively across industries for financial analysis, sales forecasting, and marketing analytics, among other applications. Organizations depend on well-built ETL pipelines to ensure that their analytics dashboards are powered by accurate and up-to-date information, which is essential for competitive advantage in a data-driven market.
Why is ETL Important?
ETL plays a crucial role in modern data management by enabling organizations to efficiently handle and integrate large volumes of data. It ensures that data collected from various sources is transformed into a consistent and accurate format, making it easier to derive valuable insights.
Consolidated Data View
ETL unifies data from multiple sources, such as customer relationship management (CRM) systems, enterprise resource planning (ERP) platforms, and IoT devices, into a single repository. This provides businesses with a holistic view of their operations, helping decision-makers understand trends and performance across departments. Consolidated data also eliminates silos, making it easier for different teams to collaborate.
Accurate Data Analysis
Data extracted from different systems may contain inconsistencies or errors. Through ETL, raw data undergoes a transformation process that includes cleansing, validation, and standardization. This ensures that only high-quality, reliable data is available for analytics, improving the accuracy of insights and reports. Consistent data reduces the likelihood of errors in decision-making.
Automation
ETL automates repetitive data processing tasks, reducing the need for manual intervention. With scheduled ETL processes, data is regularly extracted, transformed, and loaded into target systems without disruption. This automation accelerates access to up-to-date information and ensures that reports and dashboards reflect the latest data. Additionally, automation minimizes the risk of human errors, contributing to more reliable business processes.
ETL’s importance lies in its ability to streamline data workflows, enhance data quality, and provide timely insights, empowering organizations to make data-driven decisions confidently.
How ETL Has Evolved?
ETL has undergone significant changes over the years to meet the growing demands of modern data management. The transition from traditional batch-based ETL processes to modern real-time data integration reflects the evolving nature of business needs and technological advancements.
Traditional ETL
Traditional ETL processes focused on batch processing. Data was extracted from operational systems at scheduled intervals, typically during off-peak hours, and loaded into data warehouses for reporting and historical analysis. These systems were designed for structured data and performed well for predefined, static reporting needs. However, the time lag between extraction and analysis limited the ability to generate real-time insights.
Modern ETL
Modern ETL practices address the limitations of batch processing by incorporating real-time data streaming. This shift is essential for businesses that require instant access to up-to-date information. Modern ETL pipelines also work seamlessly with data lakes and cloud platforms, allowing organizations to store and analyze both structured and unstructured data. With cloud-native ETL, scalability is improved, and organizations can dynamically adjust their resources based on demand.
Key Differences
- Processing: Traditional ETL relies on batch jobs, while modern ETL supports real-time streaming.
- Infrastructure: Traditional ETL is built for on-premises data warehouses, whereas modern ETL integrates with cloud-based data lakes.
- Data Types: Traditional ETL focuses on structured data, while modern ETL handles both structured and unstructured formats.
- Flexibility: Cloud-native ETL tools offer better automation and scalability compared to their traditional counterparts.
The evolution of ETL reflects the growing need for agility in data management, enabling organizations to adapt quickly to changing business environments.
ETL Process Steps
The ETL process consists of three primary steps: data extraction, transformation, and loading. Each step plays a crucial role in ensuring that data flows smoothly from its source to the target system, maintaining accuracy and consistency throughout.
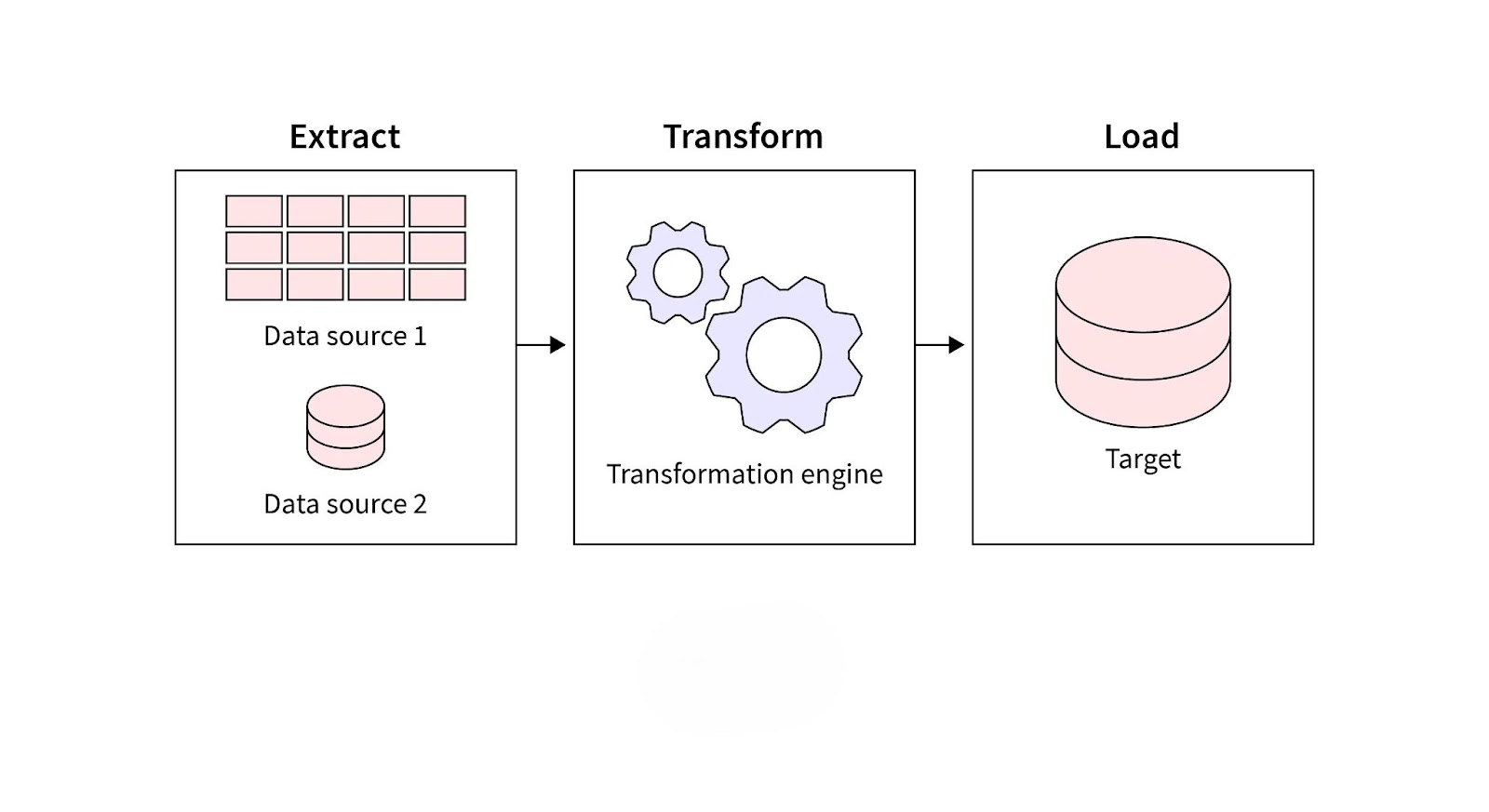
1. Data Extraction
Data extraction is the first step in the ETL process, where data is collected from multiple sources, such as databases, APIs, spreadsheets, and cloud platforms. The goal is to retrieve relevant data while ensuring that it remains consistent and complete throughout the extraction phase.
Extraction Methods
- Update Notification: This trigger-based method extracts data only when changes occur at the source. It ensures minimal data movement, making it efficient for real-time or event-driven systems.
- Incremental Extraction: In this approach, only new or modified data is retrieved since the last extraction. Incremental extraction reduces the load on the system and speeds up data transfer, making it ideal for frequent updates.
- Full Extraction: This method retrieves the complete dataset from the source system. Full extraction is usually performed during the initial data load or when a complete refresh is required. Although resource-intensive, it ensures that all data is available for analysis.
Data extraction ensures that the relevant information is accurately retrieved from multiple sources to initiate the transformation step.
2. Data Transformation
Data transformation is the most critical step in the ETL process, as it converts raw data into a consistent and usable format. Transformation ensures that the data meets business rules, standards, and target system requirements, improving overall data quality.
Types of Data Transformation
- Basic Transformations:
- Data Cleansing: Identifying and correcting errors or inconsistencies in the data.
- Deduplication: Removing duplicate entries to ensure data accuracy.
- Reformatting: Changing data formats to align with the target system.
- Advanced Transformations:
- Derivation: Creating new fields or metrics based on existing data.
- Joining: Merging data from multiple sources to form a unified dataset.
- Splitting: Breaking down complex data into simpler parts.
- Summarization: Aggregating data to create high-level insights, such as totals or averages.
- Encryption: Securing sensitive data by converting it into encrypted formats to meet privacy standards.
Effective transformation ensures that data is consistent, reliable, and prepared for accurate analysis once it is loaded into the target system.
3. Data Loading
Data loading is the final step of the ETL process, where the transformed data is moved into the target system, such as a data warehouse, data lake, or analytics platform. This step ensures that the data is accessible for analysis and reporting.
Types of Data Loading
- Full Load: This method involves loading the entire dataset into the target system, typically during the initial setup or when a full refresh is needed.
- Incremental Load: In this approach, only new or updated data is added. Incremental loading can be performed either in batches at scheduled intervals or as a streaming process for real-time data updates.
ETL vs. ELT
ELT (Extract, Load, Transform) is an alternative data processing approach where data is first loaded into the target system and then transformed as needed. Unlike ETL, where transformation happens before loading, ELT postpones this step, allowing data to remain in its raw form initially. ELT is commonly used in data lakes and cloud-based platforms that can handle large volumes of unstructured data.
Key Differences between ETL and ELT
- Processing Speed: ELT is faster since it minimizes pre-processing by loading raw data directly into the target system. ETL involves time-consuming transformations before loading, making it slower for large datasets.
- Flexibility: ELT offers more flexibility by allowing transformations to occur on-demand, while ETL follows predefined rules and is less adaptable to changing requirements.
- Use Cases: ETL is best suited for structured data that requires cleansing and formatting, often used with data warehouses. ELT, on the other hand, is ideal for big data environments, where raw data is stored in data lakes and processed only when needed.
When to Use ETL vs. ELT
ETL is preferred when data quality and consistency are essential, such as in financial reporting or compliance monitoring. ELT works well in cloud-based analytics platforms, where storage is inexpensive, and data needs to be accessed in multiple formats for different applications.
Benefits and Challenges of ETL
Benefits
- Reliable Data Integration: ETL enables organizations to seamlessly integrate data from multiple sources into a unified system. This ensures consistency and accessibility across business functions, promoting informed decision-making.
- Improved Data Quality: The transformation phase ensures that data is cleansed, validated, and formatted, leading to higher accuracy and better insights. High-quality data minimizes errors in reporting and analysis.
- Faster Data Retrieval for Analytics: Automation in ETL pipelines accelerates the movement of data to target systems, making it readily available for analytics. This real-time access to processed data allows organizations to respond quickly to market trends and business needs.
Challenges
- High Initial Setup Costs: Implementing ETL processes requires substantial investment in tools, infrastructure, and skilled personnel. Organizations need to allocate resources for both the initial setup and ongoing maintenance.
- Complexity in Maintenance: Managing ETL pipelines can be challenging, especially in environments with multiple data sources and constantly changing requirements. Troubleshooting issues across systems and maintaining data consistency demand technical expertise.
- Scalability Issues: Traditional ETL systems may struggle to handle rapidly growing datasets. As organizations generate more data, scaling ETL pipelines to accommodate the increasing volume becomes resource-intensive, prompting a shift towards modern cloud-based solutions.
ETL Tools
Several ETL tools are available to streamline data integration processes. Below are three popular tools, each with unique features:
- Apache Nifi: A powerful tool designed for automating data flows and real-time data streaming. Nifi supports various data formats and offers an intuitive interface for building complex workflows.
- Talend: Known for its user-friendly design, Talend provides both batch and real-time processing capabilities. It integrates well with cloud platforms and offers a wide range of connectors for data sources.
- Informatica: A comprehensive ETL solution offering advanced features for data governance and quality management. Informatica is widely used in large enterprises for its scalability and support for complex data workflows.
Future of ETL and Data Integration Trends
The future of ETL is shaped by evolving technologies and new demands for real-time data integration. Automation is becoming a key trend, with ETL pipelines being increasingly automated to reduce manual intervention and ensure continuous data processing.
Another significant trend is the shift towards real-time data integration, allowing businesses to access insights as soon as data is generated. This trend is driven by industries that require fast decision-making, such as finance and e-commerce.
Cloud-based ETL platforms are gaining popularity due to their scalability, flexibility, and ability to handle large datasets. These platforms support both batch and streaming data, making them suitable for modern data environments.
The role of AI and machine learning in ETL is also expanding. These technologies enhance ETL efficiency by automating data transformation processes and identifying patterns or anomalies in real-time, improving data quality and reliability.
Conclusion
ETL plays a vital role in data transformation and insight generation, enabling organizations to manage and analyze data effectively. By consolidating data from various sources and ensuring its quality, ETL processes provide the foundation for business intelligence and analytics.
As technology evolves, businesses must evaluate their ETL strategies to align with changing requirements and leverage advancements such as cloud platforms and automation. Selecting the right ETL approach based on organizational needs ensures scalability and efficiency, helping businesses thrive in a data-driven world.
To learn about Data Science, click here.
References:


