In machine learning, a model is trained to make predictions or classify data based on patterns in a dataset. However, a single model can sometimes have limitations, such as overfitting, where the model performs well on training data but poorly on new data.
Ensemble methods offer a solution by combining multiple models to improve accuracy and reduce errors. By using the strengths of different models together, ensemble methods create a more reliable and robust prediction system than any single model on its own.
What are Ensemble Methods?
Ensemble methods are techniques in machine learning that combine the predictions of multiple models to improve overall accuracy. The idea is simple: rather than relying on a single model, ensemble methods leverage the strengths of several models to create a more powerful prediction system.
By combining different models, ensemble methods address some of the limitations of individual models. For example, if one model has a tendency to overfit or underperform on certain data points, the ensemble can balance out these weaknesses and make more accurate predictions. In essence, ensemble methods help create a “team” of models, working together for better results.
Why Use Ensemble Learning?
Ensemble learning offers several benefits that make it popular in machine learning:
- Improved Accuracy and Generalization – By combining multiple models, ensemble methods often achieve higher accuracy than individual models, making predictions more reliable.
- Reduced Variance and Overfitting – Ensembles help reduce overfitting by balancing out the weaknesses of individual models. This makes ensemble models perform better on new, unseen data.
- Robustness to Noise in Data – Ensemble methods are more resilient to noisy or complex data. With multiple models contributing to the final prediction, they can better handle variations and inconsistencies in the data.
Types of Ensemble Models
Ensemble models combine the predictions of multiple individual models to improve accuracy and stability. Here’s a breakdown of popular ensemble methods, each offering unique ways to enhance model performance:
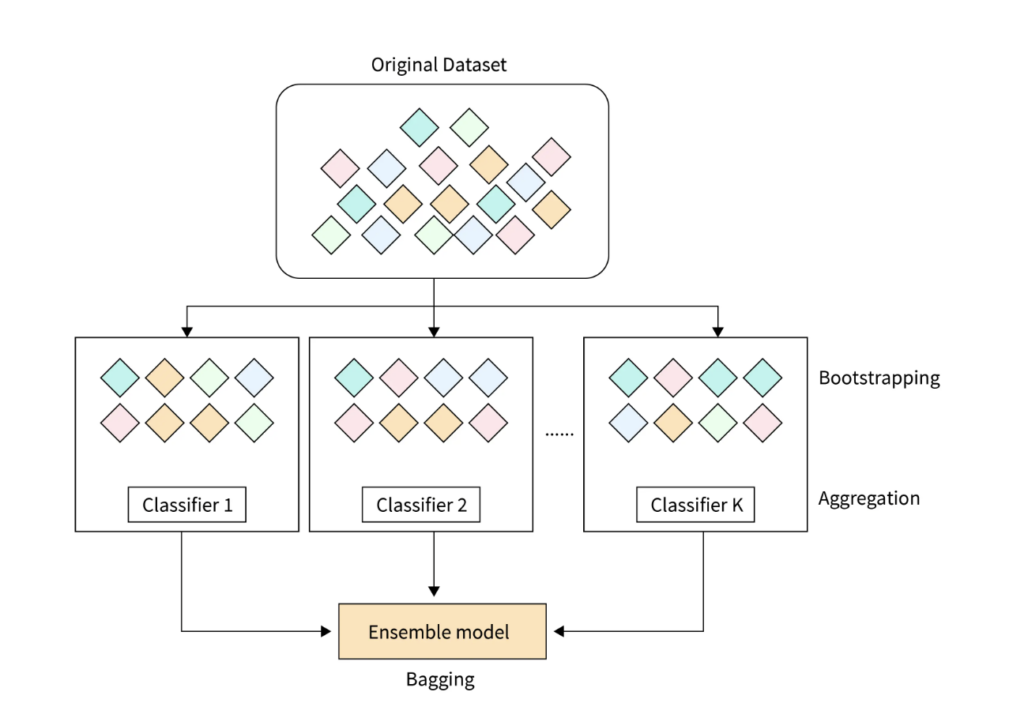
1. Bagging (Bootstrap Aggregation)
- Concept: Bagging creates multiple versions of the original dataset by randomly sampling data with replacement. Each subset is used to train a different model, which reduces variance and enhances stability.
- How It Works: Multiple models (usually decision trees) are trained independently on different subsets of the data. The predictions are then averaged (for regression) or voted on (for classification) to make the final decision.
- Popular Example: Random Forest
- Purpose: Combines multiple decision trees to create a powerful and more generalizable model.
- Implementation: In Python, use RandomForestClassifier or RandomForestRegressor from scikit-learn.
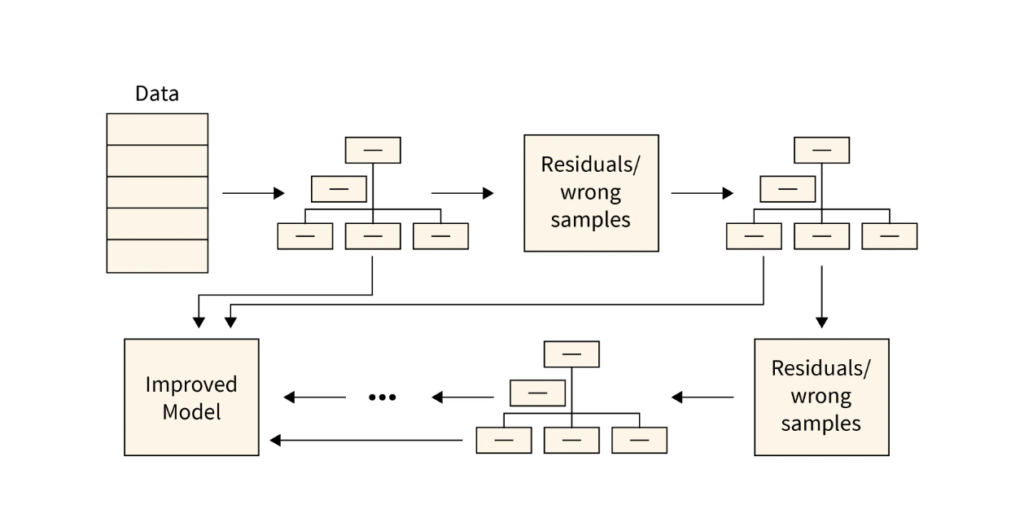
2. Boosting
- Concept: Boosting aims to build a strong model by training models sequentially. Each new model focuses on correcting the errors of the previous ones, progressively reducing bias.
- How It Works: Models are trained one after another, with each new model adjusting to the errors of its predecessors. By focusing on misclassified data points, boosting creates a robust model.
- Popular Examples:
- AdaBoost: Adjusts weights for misclassified points, emphasizing harder-to-classify examples.
- Gradient Boosting: Uses gradient descent to minimize error, popular for complex tasks.
- Implementation: In Python, use AdaBoostClassifier, GradientBoostingClassifier, or libraries like XGBoost and LightGBM for optimized boosting algorithms.
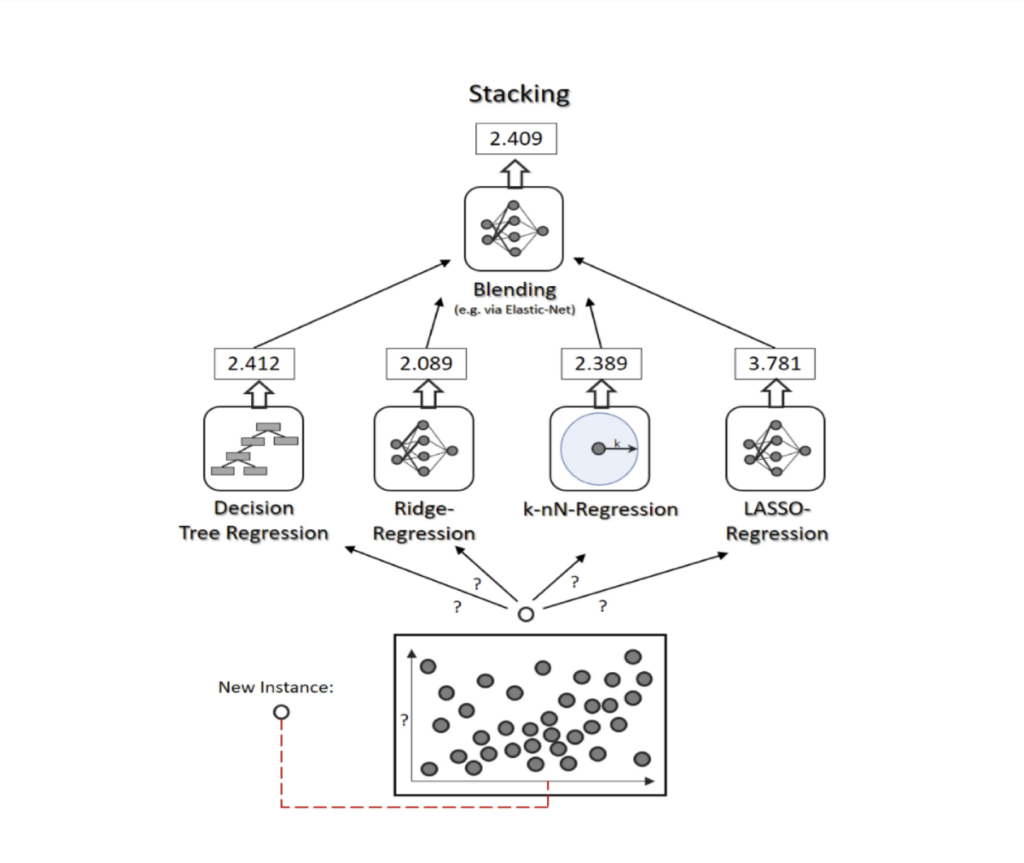
3. Stacking
- Concept: Stacking combines multiple models by using a meta-model (or “super learner”) to integrate their outputs. This meta-model learns from each individual model’s predictions to make a final, optimized prediction.
- How It Works: The base models generate predictions on the training data, and the meta-model then learns from these predictions to make a final decision. Stacking leverages the strengths of diverse models to increase accuracy.
- Popular Example: Combining decision trees, logistic regression, and support vector machines with a meta-model (such as linear regression) to produce the final result.
- Implementation: Use StackingClassifier or StackingRegressor from scikit-learn to stack models effectively.
4. Voting
- Concept: Voting aggregates predictions from multiple models, making a final decision based on a majority or weighted vote.
- How It Works: In hard voting, the final class is determined by majority vote, while soft voting takes the average probabilities of each class. This method is commonly used in classification tasks where predictions from models like logistic regression, k-nearest neighbors, and decision trees are combined.
- Popular Example: Hard voting for discrete class predictions or soft voting for probability-based outcomes.
- Implementation: Use the VotingClassifier in scikit-learn, which supports both hard and soft voting.
5. Weighted Ensemble
- Concept: Weighted ensembles assign varying importance to models based on their accuracy or reliability, giving more influence to models that perform better.
- How It Works: Each model is assigned a weight proportional to its accuracy. The final prediction is then a weighted combination, with higher-performing models contributing more to the outcome.
- Popular Example: Custom ensembles where models with greater accuracy receive higher weights to boost overall performance.
- Implementation: Weighted ensembles can be created using custom code or by specifying weights in scikit-learn’s VotingClassifier.
Main Challenge for Developing Ensemble Models?
While ensemble methods are powerful, they come with their own set of challenges that can impact model development and usability:
- Increased Computational Cost – Ensemble models often require multiple individual models, which can significantly increase computation time and resources. Training and deploying these models can be more resource-intensive compared to single models, especially for large datasets.
- Interpretability – Ensemble models, particularly complex ones like Random Forests or stacked models, can be difficult to interpret. Unlike simpler models, it’s challenging to understand how each individual model contributes to the final decision, which can make the ensemble harder to explain to stakeholders.
- Complexity in Implementation – Implementing ensemble models can be technically challenging, especially when combining different types of models. Ensuring that each model works together efficiently requires careful design and tuning, which may be difficult for beginners or small teams.
- Risk of Overfitting with Complex Ensembles – Although ensembles are designed to reduce overfitting, overly complex ensembles can still overfit if not properly tuned. When too many models are combined without careful evaluation, there’s a risk of creating a model that performs well on training data but poorly on new data.
Conclusion
Ensemble methods combine multiple models to improve accuracy and robustness, making them effective in complex machine learning tasks. Techniques like bagging, boosting, and stacking help address limitations of single models, enhancing performance.
While ensembles come with challenges like higher computational costs and reduced interpretability, these can be managed with careful tuning. Ensemble methods will continue to play a vital role in advancing machine learning, enabling reliable and high-performance models across various fields.