Machine learning (ML) has become a foundational technology in various industries, from healthcare to finance, where systems learn from data to make predictions, identify trends, or discover patterns. Two core types of machine learning are supervised and unsupervised learning. Understanding the distinction between these methods is essential for selecting the right technique depending on the data and desired outcomes. While supervised learning focuses on making accurate predictions based on labeled data, unsupervised learning is designed to uncover hidden patterns in unlabeled data. This guide explores the key differences, examples, and applications of both learning types.
What is Supervised Learning?
Supervised learning is a machine learning technique in which the algorithm is trained on labeled data. This means that for each input, the corresponding output (or label) is provided. The model’s goal is to learn the mapping from inputs to outputs and make accurate predictions on new, unseen data.
The supervised learning process involves feeding the algorithm with a set of input-output pairs (training data), allowing it to learn the relationships and rules that link the input to the output. The model continues to adjust and improve its predictions by minimizing errors based on the provided labels.
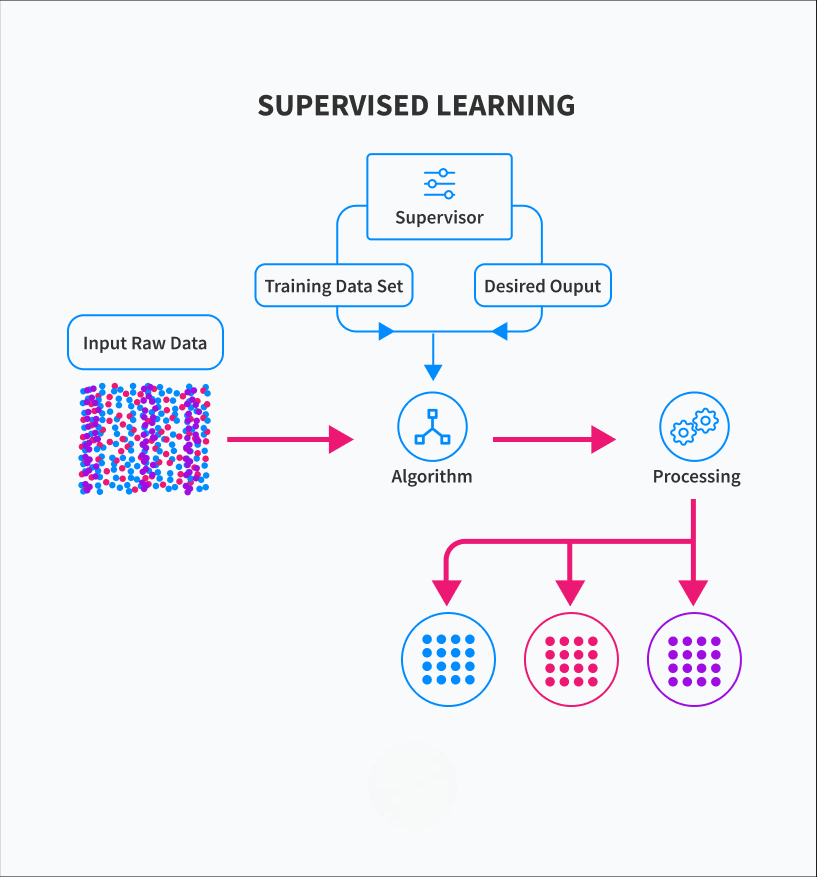
Why Supervised Learning?
Supervised learning is primarily used for tasks that involve classification or regression. It is highly effective when the outcome or label is already known, and the objective is to predict future events or categorize data accurately.
Common Use Cases:
- Email Spam Detection: A supervised learning algorithm is trained on a dataset of emails labeled as spam or not spam. Once trained, the model can classify incoming emails as spam or legitimate based on the learned patterns.
- House Price Prediction: A supervised learning model can predict house prices based on features like location, size, and number of bedrooms. The model is trained on historical data where house prices are already known.
Popular Algorithms:
- Linear Regression: Used to predict continuous variables, such as sales figures or stock prices.
- Logistic Regression: Commonly used for binary classification tasks, such as determining whether a customer will churn or not.
- Random Forests: A versatile algorithm that can be used for both classification and regression, providing robust and accurate predictions.
In summary, supervised learning is ideal when a known relationship exists between inputs and outputs, and the goal is to predict or classify future outcomes.
What is Unsupervised Learning?
Unsupervised learning operates on unlabeled data, meaning the algorithm must infer patterns and relationships without any predefined output labels. Unlike supervised learning, the goal of unsupervised learning is not to make predictions but to find structure within the data itself. The algorithm identifies clusters, associations, or hidden structures based solely on the input data’s characteristics.
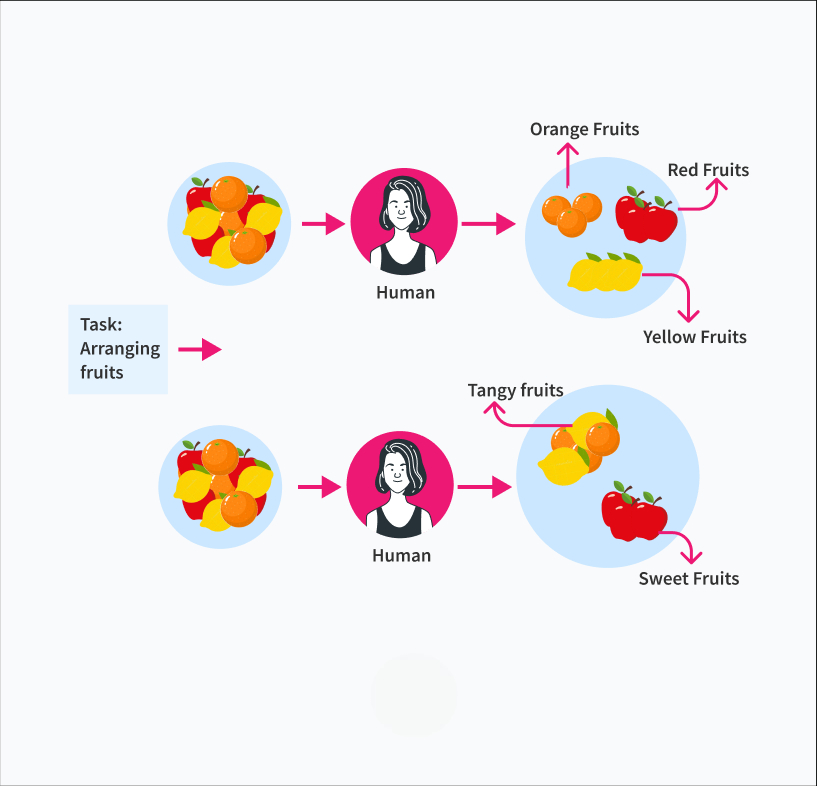
Why Unsupervised Learning?
Unsupervised learning is widely used when the aim is to explore data and uncover previously unknown insights. It helps analysts understand the data’s structure and is particularly useful in situations where labeled data is not available or is too costly to obtain.
Common Use Cases:
- Customer Segmentation: Unsupervised learning algorithms like K-Means Clustering are used to group customers into different segments based on purchasing behavior, demographics, or engagement metrics. This segmentation allows businesses to tailor marketing efforts to different customer groups.
- Anomaly Detection: Algorithms like Isolation Forests or Autoencoders are often used to detect outliers or anomalies in datasets. This is particularly useful in applications like fraud detection, where identifying unusual patterns can prevent fraudulent activities.
Popular Algorithms:
- K-Means Clustering: A simple and widely used clustering algorithm that partitions data into k distinct clusters based on their similarity.
- Hierarchical Clustering: An alternative clustering method that organizes data into a tree-like structure, grouping similar data points together.
- Principal Component Analysis (PCA): A dimensionality reduction technique that simplifies large datasets by reducing the number of features while retaining important information.
Unsupervised learning excels in situations where little or no labeled data exists, making it a powerful tool for exploratory data analysis and pattern recognition.
Key Differences between Supervised and Unsupervised Learning
Supervised and unsupervised learning differ in several key aspects, from the type of data they use to their ultimate objectives. Below is a detailed comparison of their differences:
| Aspect | Supervised Learning | Unsupervised Learning |
| Labeled vs. Unlabeled Data | Uses labeled data, where both the input and the corresponding output (label) are known. | Works with unlabeled data, where there are no predefined labels or outputs. |
| Objective | Aims to predict specific outcomes based on labeled data (classification or regression). | Focuses on discovering hidden patterns or structures within the data (clustering or dimensionality reduction). |
| Training Process | The model is trained using labeled data and continuously adjusts to minimize errors between predictions and actual outputs. | The model automatically identifies similarities, clusters, or structures within the data without any supervision. |
| Complexity | Typically easier to interpret because the output labels are known, making it easier to assess the model’s performance. | More exploratory in nature and often harder to interpret because the output isn’t predefined. |
| Common Applications | Used for tasks like classification (e.g., categorizing emails as spam or not spam) and regression (e.g., predicting house prices or sales figures). | Commonly applied in tasks like clustering (e.g., grouping customers by behavior) and dimensionality reduction (e.g., simplifying datasets). |
| Examples of Algorithms | Linear Regression, Logistic Regression, Support Vector Machines (SVM), Decision Trees | K-Means Clustering, Hierarchical Clustering, Principal Component Analysis (PCA) |
| Supervision | The learning process is supervised, with the model’s performance continually checked against known outcomes to improve accuracy. | The learning process is unsupervised, meaning the model identifies patterns without feedback or labels. |
| Accuracy and Monitoring | The model’s accuracy is evaluated using a loss function, and performance can be monitored based on how well it predicts known outcomes. | There’s no predefined evaluation metric; success is measured by how well the model organizes or simplifies the data. |
In essence, the choice between supervised and unsupervised learning depends on whether you need to predict specific outcomes or explore unknown patterns in your data.
Supervised vs. Unsupervised Learning: Which is Best for You?
Choosing between supervised and unsupervised learning largely depends on the nature of your data and the goals of your project.
When to Use Supervised Learning:
- Prediction Tasks: If your objective is to predict future events, such as whether a customer will make a purchase, then supervised learning is the best choice.
- Labeled Data: When you have a dataset with clear input-output pairs, like sales data where you know the total revenue for each month, supervised learning can generate accurate predictions.
When to Use Unsupervised Learning:
- Exploratory Data Analysis: If you’re working with a dataset where the relationships or outcomes are unknown, unsupervised learning can help uncover hidden patterns or clusters.
- Clustering or Grouping: When you need to group similar data points—like segmenting customers into groups based on buying patterns—unsupervised learning is ideal.
In some cases, a combination of both techniques—semi-supervised learning—can be applied. This approach leverages a small amount of labeled data alongside a large volume of unlabeled data to improve model accuracy and reduce labeling costs.
Conclusion
Both supervised and unsupervised learning are fundamental to machine learning and artificial intelligence. While supervised learning excels in tasks where predicting specific outcomes is the goal, unsupervised learning is invaluable for exploring and identifying patterns in unlabeled data. As machine learning continues to grow in importance across industries, understanding the differences between these approaches—and knowing when to use each—will help data scientists, engineers, and businesses make informed decisions. By choosing the right learning technique, organizations can unlock the full potential of their data and drive innovation in areas such as finance, healthcare, and e-commerce.
References:
- Supervised vs. Unsupervised Learning: What’s the Difference? | IBM
- Supervised vs. unsupervised learning | Google Cloud
- Supervised vs Unsupervised Learning Explained – Seldon


