Machine learning has revolutionized how we approach data-driven decision-making, with algorithms that allow machines to learn patterns and make predictions. Among the various algorithms, the decision tree stands out for its simplicity and effectiveness in both classification and regression tasks. Decision trees mimic human decision-making processes, making them intuitive to interpret and apply. This article explores the intricacies of decision trees, why they are widely used, and how they are built and optimized in machine learning.
What is a Decision Tree in Machine Learning?
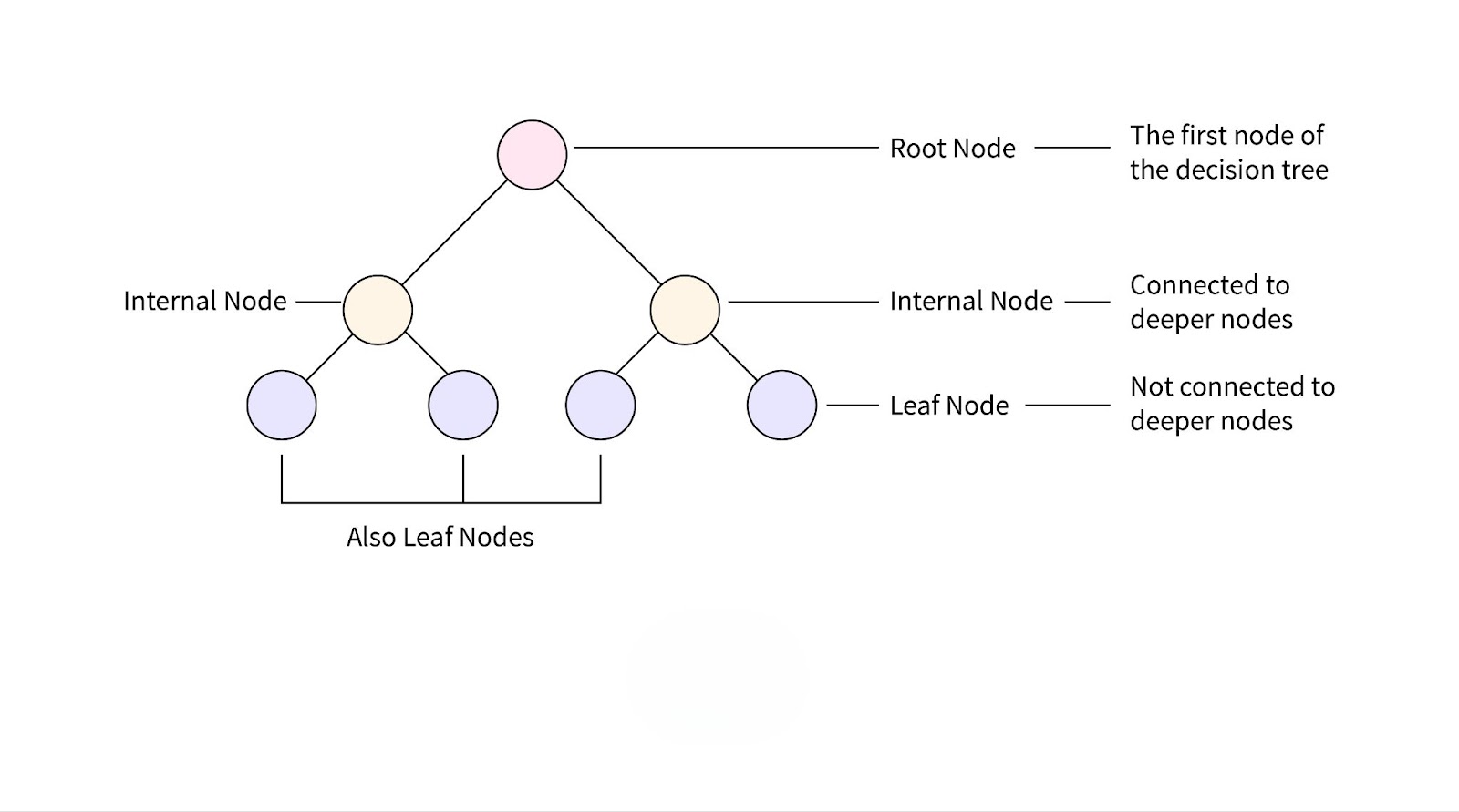
A decision tree is a supervised learning algorithm used for both classification and regression problems. It is represented as a tree structure where each internal node represents a test on an attribute, each branch represents the outcome of the test, and each leaf node represents a class label or a predicted value. The goal of a decision tree is to split the dataset into subsets based on the value of an attribute, repeating this process until each subset contains only instances that belong to a single class or have similar values.
In simpler terms, a decision tree can be thought of as a flowchart where each decision leads to further decisions until an outcome is reached. For example, imagine a decision tree model that predicts whether a person will purchase a product based on factors such as age, income, and previous purchasing behavior. At each stage of the tree, a decision is made (e.g., “Is the person’s age greater than 30?”) until a final decision is reached, such as “Will the person buy the product or not?”
Decision Tree Terminologies
To fully understand how decision trees work, it’s important to familiarize yourself with the following key terminologies:
- Root Node: This is the topmost node in a decision tree, representing the entire dataset. The root node is where the first split occurs based on the most significant attribute.
- Leaf Node: A leaf node is the terminal node that represents the final classification or output. It does not split further and provides the decision based on the previous splits.
- Splitting: This refers to the process of dividing a node into sub-nodes based on a certain condition or attribute. Each split corresponds to a decision made by the model.
- Branch/Subtree: A branch represents the subset of data that results from a split. It leads from a parent node to a child node or leaf.
- Decision Node: A node that represents a decision to split the data further based on a particular feature or attribute.
- Pruning: The process of removing parts of the tree that are not contributing to the model’s accuracy in order to prevent overfitting.
Understanding these terms is crucial for grasping how a decision tree works from start to finish, enabling better comprehension of how decisions are made at every step of the process.
How is a Decision Tree Formed?
Building a decision tree involves several steps that ensure the final model is both accurate and interpretable. Here’s a breakdown of the process:
1. Selecting the Best Attribute
The first step in building a decision tree is selecting the best attribute to split the dataset. This is done using criteria such as information gain or Gini index. The attribute that results in the highest gain (or lowest impurity) is chosen as the root node.
2. Recursive Splitting
Once the best attribute is selected, the data is split into subsets based on the value of that attribute. This process is repeated recursively for each subset, creating branches and sub-branches until the data is perfectly split or meets a stopping criterion (e.g., maximum depth or minimum number of instances per leaf).
3. Stopping Criteria
The decision tree continues splitting the data until one of the following conditions is met:
- All instances in a node belong to the same class.
- The maximum depth of the tree is reached.
- The number of instances in a node falls below a specified threshold.
4. Tree Pruning
After the decision tree is fully grown, it may be necessary to prune it to remove overfitting. Pruning helps simplify the model by removing branches that do not contribute much to the accuracy of the model on unseen data.
Why Use a Decision Tree in Machine Learning?
Decision trees offer several unique advantages that make them a popular choice in machine learning:
- Interpretability: Decision trees are highly interpretable. The tree structure provides a clear visual representation of the decision-making process, making it easy for both technical and non-technical stakeholders to understand.
- No Data Preprocessing Required: Decision trees can handle data without the need for normalization or scaling, unlike other algorithms like SVM or neural networks.
- Handling of Both Categorical and Numerical Data: Decision trees can work with both types of data, making them versatile for different problem types.
- Non-linear Relationships: Decision trees can model non-linear relationships between features and the target variable, enabling more complex decision-making.
These attributes make decision trees useful in a wide range of industries, from finance and healthcare to marketing and education.
Attribute Selection Measures
Choosing the right attribute to split the data at each node is a critical step in building an accurate decision tree. The most common methods used for attribute selection are information gain and Gini index.
Information Gain
Information Gain is based on the concept of entropy, which measures the amount of disorder or uncertainty in the dataset. The goal is to select the attribute that reduces entropy the most when the data is split.
The formula for entropy is:
$$Entropy(S) = – \sum p_i \log_2(p_i)$$
where pip_ipi is the proportion of instances in class iii.
Information gain is calculated as the difference between the entropy before and after the split. The attribute with the highest information gain is selected as the splitting attribute.
Gini Index
The Gini index measures the impurity of a dataset. A lower Gini index indicates a purer dataset, meaning most of the instances belong to a single class. The Gini index is computed as:
$$Gini = 1 – \sum (p_i)^2$$
where pip_ipi is the probability of a particular class.
Attributes that result in the lowest Gini index after the split are considered the best candidates for splitting the data.
Comparison
Both information gain and Gini index serve a similar purpose, but information gain is more commonly used in decision trees for classification tasks, while Gini index is often preferred in CART (Classification and Regression Trees) algorithms.
Pruning Decision Trees
One major challenge with decision trees is their tendency to overfit, especially when the tree becomes too deep. To address this, pruning is used to simplify the tree and improve its generalization to unseen data.
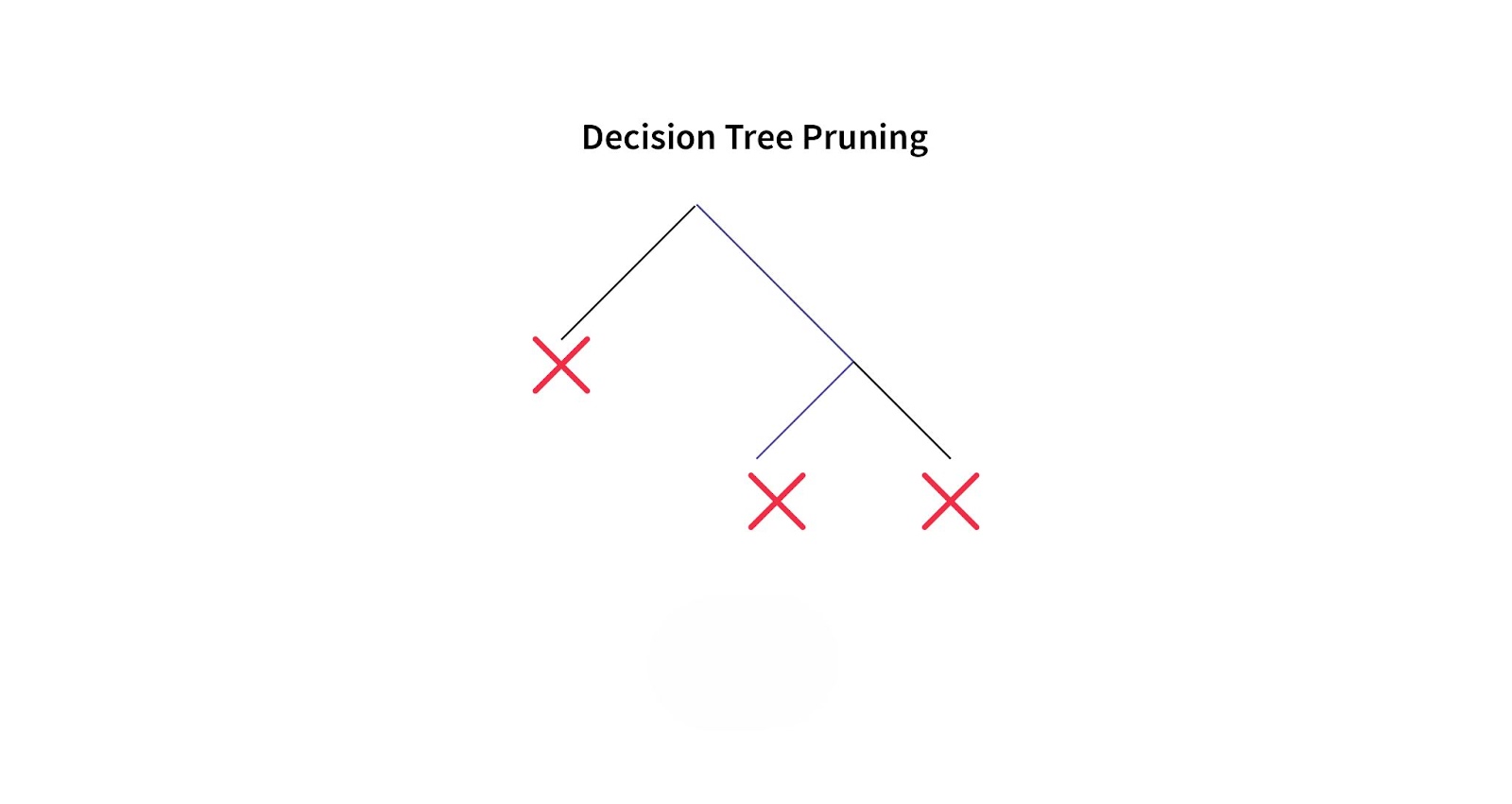
Pre-pruning
Pre-pruning involves stopping the tree-building process before it becomes too complex. This is done by setting conditions such as limiting the tree’s maximum depth or requiring a minimum number of instances for a split. Pre-pruning helps avoid overfitting early on.
Post-pruning
Post-pruning occurs after the tree has been fully built. In this method, branches that do not improve the model’s performance on a validation set are removed. This results in a smaller, more efficient tree that performs better on unseen data.
Pruning is an essential technique for achieving the right balance between model complexity and accuracy, ensuring that the decision tree performs well on both training and test data.
Example of a Decision Tree Algorithm
Let’s consider a real-world example of how a decision tree algorithm might be used to classify patients based on symptoms. Suppose we have a dataset containing symptoms like fever, cough, and fatigue, along with a target variable indicating whether a patient has a particular illness (yes or no).
The decision tree algorithm will first split the dataset based on the most significant attribute (e.g., “Does the patient have a fever?”). If the answer is yes, the algorithm may then split based on another symptom, such as “Does the patient have a cough?” This process continues until the algorithm arrives at a leaf node, where it predicts whether the patient has the illness or not.
This example illustrates how decision trees break down complex decisions into a series of binary choices, ultimately arriving at a prediction.
Advantages of Decision Tree in Machine Learning
Decision trees offer several advantages that make them a popular choice for machine learning tasks:
- Easy to Interpret: The structure of decision trees makes them easy to understand and explain.
- Minimal Data Preprocessing: They work well with raw data and do not require extensive preprocessing.
- Flexibility: Decision trees can handle both categorical and numerical data.
- Captures Non-linear Relationships: They are capable of modeling non-linear interactions between features.
Disadvantages of Decision Tree in Machine Learning
Despite their advantages, decision trees have some limitations:
- Overfitting: Without pruning, decision trees are prone to overfitting, especially with noisy data.
- Instability: Small changes in the data can lead to significant changes in the structure of the tree.
- Bias: Decision trees can become biased toward features with more categories, affecting their accuracy in certain tasks.
- Complexity: For very large datasets, decision trees can become computationally expensive and difficult to interpret.
Despite these limitations, decision trees remain a powerful tool, particularly when combined with techniques like bagging and random forests to address issues like overfitting and instability.
Python Implementation of Decision Tree
Decision trees can be implemented easily in Python using the scikit-learn library. Here’s a step-by-step guide to building and evaluating a decision tree:
Data Preprocessing
The first step is to preprocess the data by handling missing values, converting categorical data to numerical format using one-hot encoding, and splitting the dataset into training and testing sets.
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from sklearn.tree import DecisionTreeClassifier
import pandas as pd
# Load and preprocess the data
data = pd.read_csv('dataset.csv')
X = data.drop('target', axis=1)
y = data['target']
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)Training the Decision Tree Model
Once the data is preprocessed, the next step is to create and train the decision tree model.
# Initialize the decision tree classifier
model = DecisionTreeClassifier(criterion='gini', max_depth=5)
# Train the model
model.fit(X_train, y_train)Model Evaluation
After training the model, we can evaluate its performance using metrics such as accuracy, confusion matrix, and classification report.
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# Make predictions
y_pred = model.predict(X_test)
# Evaluate the model
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
# Confusion matrix and classification report
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))This simple implementation demonstrates how to train, predict, and evaluate a decision tree model in Python.
Conclusion
Decision trees are a powerful and intuitive tool for both classification and regression tasks. Their ability to model complex, non-linear relationships and handle both categorical and numerical data makes them versatile across various industries. While decision trees are prone to overfitting, techniques like pruning help mitigate this issue, ensuring that the model generalizes well to unseen data. With the right balance of depth, pruning, and attribute selection, decision trees provide a robust and transparent way to solve machine learning problems.
References:


