Data science is revolutionizing industries by enabling data-driven decision-making. To harness its full potential, a structured approach to data analysis is crucial. The data science process provides a step-by-step framework that guides professionals through collecting, cleaning, analyzing, and interpreting data, leading to more accurate and actionable insights.

Source: Inprogrammer
What is Data Science?
Data science is an interdisciplinary field that combines statistical analysis, machine learning, and data mining to extract knowledge and insights from structured and unstructured data. It involves collecting data, cleaning and processing it, analyzing it using various techniques, and then interpreting the results to solve real-world problems.
The nature of data science is highly interdisciplinary, requiring skills from fields like computer science, statistics, mathematics, and domain expertise. Data science is applied across industries, from finance and healthcare to retail and marketing, helping organizations make better decisions, improve processes, and innovate.
The data science process serves as a roadmap for tackling complex problems by providing a structured approach to handling data. This process allows data scientists to systematically break down problems, identify patterns, build models, and derive valuable insights. Whether it’s predicting customer behavior, detecting fraud, or optimizing supply chains, data science offers a powerful way to solve problems using data.
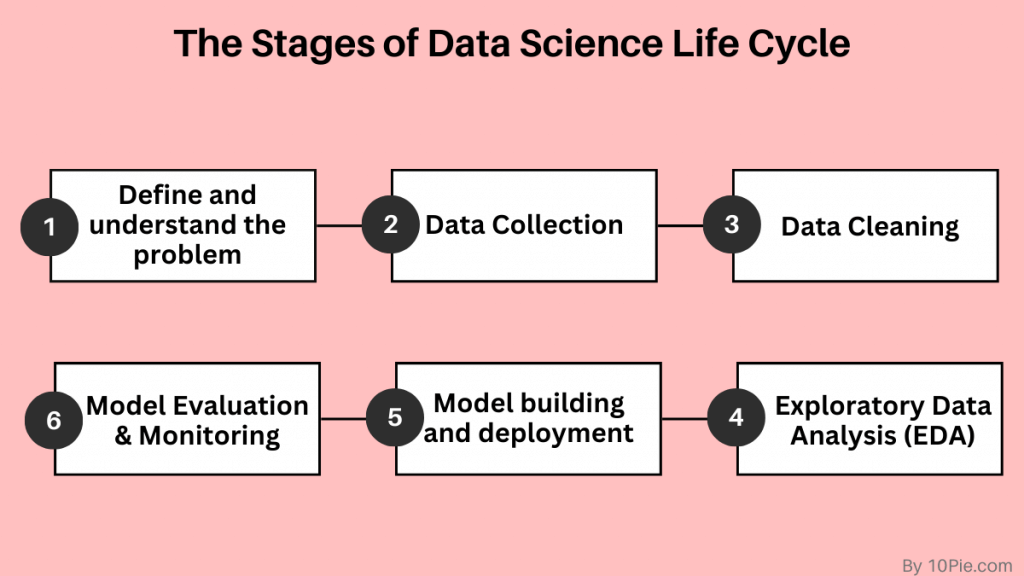
Data Science Process Life Cycle
The data science process life cycle is essential for ensuring that data-driven projects are well-structured and effective. The key steps in this process include:
Source: 10Pie
1. Framing the Problem
Defining the business or research problem is the first and most crucial step. The problem definition shapes the direction of the entire project. Without a clear understanding of the objective, it’s challenging to develop effective solutions.
2. Collecting Data
Once the problem is defined, the next step is to gather relevant data from various sources. Data can come in many forms, including structured, unstructured, and semi-structured formats. Data scientists collect data from databases, APIs, web scraping, and external sources like government records or sensors.
3. Cleaning Data
Data cleaning is one of the most time-consuming yet critical tasks in data science. This step involves handling missing values, correcting inconsistent data, and removing noisy data. Clean data ensures that the results from analysis and modeling are accurate.
4. Exploratory Data Analysis (EDA)
EDA involves exploring the data through statistical methods and visualization tools to uncover hidden patterns, trends, and relationships. This step often provides initial insights and helps shape the subsequent modeling phase.
5. Model Building and Deployment
In this step, predictive models are built using machine learning or statistical algorithms. After building a model, it’s deployed into real-world applications to make predictions or automate processes.
6. Communicating Your Results
Finally, data scientists must communicate their insights to stakeholders. This step involves creating visualizations and reports to explain the findings and recommend actionable steps.
Components of the Data Science Process
The data science process consists of several key components, each playing a vital role in the overall workflow:
1. Data
Data is the foundation of any data science project. It can be big data (massive datasets generated in real time) or traditional datasets. Data sources can include databases, APIs, IoT devices, social media platforms, and more. The quality of the data and its relevance to the problem at hand directly influence the success of the project.
2. Algorithms
At the core of data science is the use of machine learning and statistical algorithms. These algorithms are responsible for analyzing data, identifying patterns, and making predictions. Data scientists use a wide range of algorithms, including classification, regression, clustering, and decision trees. These algorithms help in solving problems such as predicting future outcomes, grouping similar data points, or classifying data into specific categories.
3. Tools
Data scientists rely on a variety of software tools and programming languages to process, analyze, and visualize data. Some of the most commonly used tools include:
- Programming Languages: Python, R, and SQL are the most widely used languages in data science.
- Big Data Technologies: Hadoop, Spark, and distributed computing frameworks help manage and process large datasets.
- Data Visualization Tools: Tools like Tableau, Power BI, and Matplotlib help present insights clearly.
4. Models
Models are mathematical representations of real-world phenomena. They help data scientists make predictions or classify data. Some common types of models used in data science include:
- Predictive Models: Used to forecast future outcomes based on historical data.
- Classification Models: Used to categorize data into predefined classes.
- Clustering Models: Group similar data points together based on their attributes.
Steps in the Data Science Process
The data science process involves several distinct steps, with each step playing a critical role in achieving accurate and reliable results. Two popular frameworks for organizing these steps are the CRISP-DM and OSEMN frameworks.
CRISP-DM Framework
The CRISP-DM (Cross-Industry Standard Process for Data Mining) framework is one of the most widely adopted processes in data science. It consists of six steps:
- Business Understanding
This step focuses on defining the business objective. Data scientists need to understand the goals and translate them into data-driven problems. For instance, if a company wants to reduce customer churn, the data science team must frame this as a prediction problem. - Data Understanding
After defining the problem, the next step is to collect and understand the data. This involves identifying relevant datasets, understanding their context, and assessing data quality. - Data Preparation
This step involves data cleaning and feature engineering—creating new features from existing data to improve the performance of machine learning models. - Modeling
In this phase, machine learning algorithms are applied to the data. The model’s performance is tested, and different algorithms are compared to find the best fit for the problem. - Evaluation
The model’s performance is evaluated using metrics like accuracy, precision, recall, and F1 score. The goal is to ensure the model performs well on unseen data and solves the problem effectively. - Deployment
Once the model is evaluated, it is deployed into production environments where it can make real-time predictions or automate decision-making processes.
OSEMN Framework
The OSEMN framework (Obtain, Scrub, Explore, Model, and iNterpret) provides another approach to the data science process:
- Obtain Data
The first step is acquiring data from various sources, such as APIs, databases, web scraping, or external files. Data might be structured or unstructured, requiring different techniques to collect and organize. - Scrub Data
After acquiring the data, it needs to be cleaned. This involves handling missing values, correcting inconsistencies, and transforming the data into a usable format. - Explore Data
In this step, data scientists perform exploratory data analysis (EDA) to discover patterns and trends within the data. Visualization tools like Seaborn or Matplotlib are often used to create histograms, scatter plots, and correlation matrices. - Model Data
After gaining insights from EDA, data scientists apply machine learning algorithms to the data. This step involves building models that can make predictions or classify data based on patterns. - iNterpret Results
The final step in the OSEMN framework is interpreting the results and presenting the findings to stakeholders. This often involves creating reports, dashboards, or presentations that explain the model’s performance and suggest actionable steps based on the insights.
Both the CRISP-DM and OSEMN frameworks provide structured approaches to the data science process, ensuring that each project follows a clear and methodical workflow.
Knowledge and Skills for Data Science Professionals
To succeed in data science, professionals need a combination of technical and non-technical skills:
Technical Skills:
- Programming: Proficiency in languages like Python, R, and SQL is essential for manipulating data, building models, and automating workflows.
- Machine Learning: Data scientists must understand machine learning algorithms such as decision trees, neural networks, and support vector machines to build predictive models.
- Data Wrangling: Cleaning and preparing data is a critical skill, as the quality of the input data directly impacts model performance.
- Statistical Analysis: Knowledge of probability, statistical tests, and regression analysis helps data scientists interpret results and validate their models.
Non-Technical Skills:
- Business Understanding: Data scientists must understand the business context and how data-driven insights can solve real-world problems.
- Communication Skills: Presenting complex insights in a simple, actionable format is key to ensuring that stakeholders can understand and act on the findings.
- Critical Thinking: Data science requires problem-solving skills and the ability to think critically about data and models to draw meaningful conclusions.
Data scientists must balance these technical and non-technical skills to succeed in their roles, ensuring they can effectively analyze data and communicate results to stakeholders.
Benefits and Uses of Data Science and Big Data
Data science, combined with big data, drives decision-making and innovation across various industries. Some of the key benefits and uses of data science include:
- Improved Decision-Making: Data science allows businesses to make data-driven decisions by analyzing large volumes of data. For instance, companies use data science to predict customer behavior, optimize pricing strategies, and improve supply chains.
- Enhanced Healthcare: In healthcare, data science helps predict patient outcomes, personalize treatments, and improve drug discovery. Data-driven insights can help reduce costs, increase efficiency, and improve patient care.
- Fraud Detection: In finance, data science is used to detect fraudulent transactions by analyzing spending patterns and identifying anomalies in real time.
- Personalization in Retail: Retail companies use data science to personalize customer experiences, improve recommendations, and optimize inventory management.
Big data technologies like Hadoop and Spark enable organizations to process and analyze vast datasets, extending the impact and reach of data science applications.
Tools for the Data Science Process
Data scientists use a variety of tools to collect, analyze, and visualize data. These tools are essential for completing the data science process efficiently.
1. Programming Languages:
- Python: Python is the most widely used programming language in data science due to its simplicity and a vast ecosystem of libraries such as Pandas, NumPy, and Scikit-learn.
- R: R is another popular language, especially for statistical analysis and data visualization.
2. Data Visualization Tools:
- Tableau: Tableau is widely used to create interactive visualizations and dashboards that allow stakeholders to explore data in a user-friendly way.
- Power BI: Power BI provides similar functionality, offering integration with Microsoft’s ecosystem for seamless reporting.
3. Big Data Technologies:
- Hadoop: Hadoop is a distributed computing framework that allows organizations to process large amounts of data across clusters of computers.
- Spark: Apache Spark is a faster, in-memory processing engine that’s used for big data analytics and real-time data processing.
4. Machine Learning Libraries:
- Scikit-learn: Scikit-learn is a popular Python library used for implementing machine learning algorithms, including classification, regression, and clustering models.
- TensorFlow: TensorFlow, developed by Google, is widely used for building and training deep learning models.
Data scientists leverage these tools to streamline the data science process, from data collection and cleaning to modeling and visualizing results.
Usage of the Data Science Process in Different Industries
Data science has wide-ranging applications across various industries. Some key examples include:
Healthcare:
In healthcare, data science is used for predictive analytics to improve patient outcomes, optimize treatment plans, and discover new drugs. For instance, machine learning models can predict the likelihood of diseases and assist doctors in making data-driven decisions.
Finance:
In the finance sector, data science helps in risk assessment, fraud detection, and developing investment strategies. By analyzing financial data, data scientists can uncover trends that help institutions make informed investment decisions.
Retail:
Retail companies use data science to gain insights into customer preferences and optimize inventory management. Data-driven personalization strategies, such as recommendation engines, enhance the customer experience and drive sales.
Marketing:
Data science enables marketers to optimize campaigns by analyzing customer data for segmentation and targeting. By understanding customer behavior, marketers can improve engagement and drive higher conversion rates.
These examples demonstrate how the data science process can be applied to solve industry-specific problems and drive innovation.
Challenges in the Data Science Process
Despite its benefits, the data science process comes with several challenges:
1. Data Quality Issues:
Data scientists often struggle with inconsistent, missing, or noisy data. Poor-quality data can lead to inaccurate predictions and flawed insights, making it essential to invest time in data cleaning and preparation.
2. Model Interpretability:
Some machine learning models, particularly deep learning algorithms, function as black boxes, making it difficult to interpret how they arrive at certain predictions. This lack of transparency can be problematic when models are deployed in high-stakes environments such as healthcare or finance.
3. Scalability:
As datasets grow, it becomes challenging to scale models to handle large data volumes efficiently. Data scientists must ensure that their models can process big data in real time without sacrificing accuracy.
4. Ethical Issues:
Ethical considerations are becoming increasingly important in data science. Issues like bias in machine learning models can lead to unfair or discriminatory outcomes. Additionally, data privacy concerns require data scientists to adhere to regulations such as GDPR and ensure that sensitive information is protected.
Addressing these challenges requires careful planning, proper data management, and ethical considerations throughout the data science process.
Conclusion
The data science process is essential for solving complex, data-driven problems. By following a structured workflow, data scientists can systematically collect, clean, analyze, and interpret data to provide actionable insights. As the field continues to evolve, the tools and techniques used in data science will become even more sophisticated, enabling businesses to unlock new opportunities and make more informed decisions. However, data scientists must also be mindful of the challenges associated with data quality, model interpretability, scalability, and ethical issues. By adhering to best practices, data science professionals can continue to drive innovation and positively impact industries worldwide.
References:
- Chapter 2. The data science process – Introducing Data Science: Big data, machine learning, and more, using Python tools
- Data Science Process: A Comprehensive Guide | by Abhijit | Medium


