Did you know that over 90% of the world’s data has been generated in just the past two years? With this exponential growth in data comes an increasing need for businesses to leverage it effectively. This is where data science comes into play. Data science is the key to transforming raw data into actionable insights, driving smarter decision-making and innovation across industries.
The Data Science Lifecycle revolves around the use of machine learning and various analytical strategies to produce insights and predictions from data to meet business objectives. The process involves multiple stages such as data cleaning, preparation, modeling, and evaluation. Each stage is critical, and the entire procedure can span several months depending on the complexity of the problem. Therefore, following a well-defined structure is essential to solve data-driven challenges effectively.
One of the most widely accepted structures for managing analytical problems is the Cross-Industry Standard Process for Data Mining (CRISP-DM) framework. This globally recognized framework provides a methodical approach to tackling any data science challenge, ensuring that each step is addressed thoroughly and efficiently.
This article will guide you through the Data Science Lifecycle, covering each phase, from understanding business objectives to deploying models in production. Whether you’re a beginner seeking foundational knowledge or a seasoned professional refining your process, this guide will offer valuable insights.
What is the Need for Data Science?
In today’s data-driven world, businesses across all sectors are turning to data science to gain competitive advantages. For instance:
- Fraud detection: Financial institutions use data science algorithms to detect fraudulent transactions in real-time.
- Personalized recommendations: E-commerce platforms like Amazon and Netflix rely on data models to suggest products and content tailored to user preferences.
- Medical diagnostics: Hospitals are using predictive models to improve diagnostics, anticipate treatment outcomes, and manage patient data more effectively.
By applying data science, organizations can address several pressing challenges:
- Inefficient processes: Data science can identify bottlenecks and optimize workflows, saving time and resources.
- Lack of actionable insights: Companies often sit on mountains of data but struggle to extract meaningful information. Data science bridges this gap, turning raw data into strategic insights.
- Risk management: Predictive modeling allows organizations to assess risks, enabling more informed and confident decision-making.
The Lifecycle of Data Science
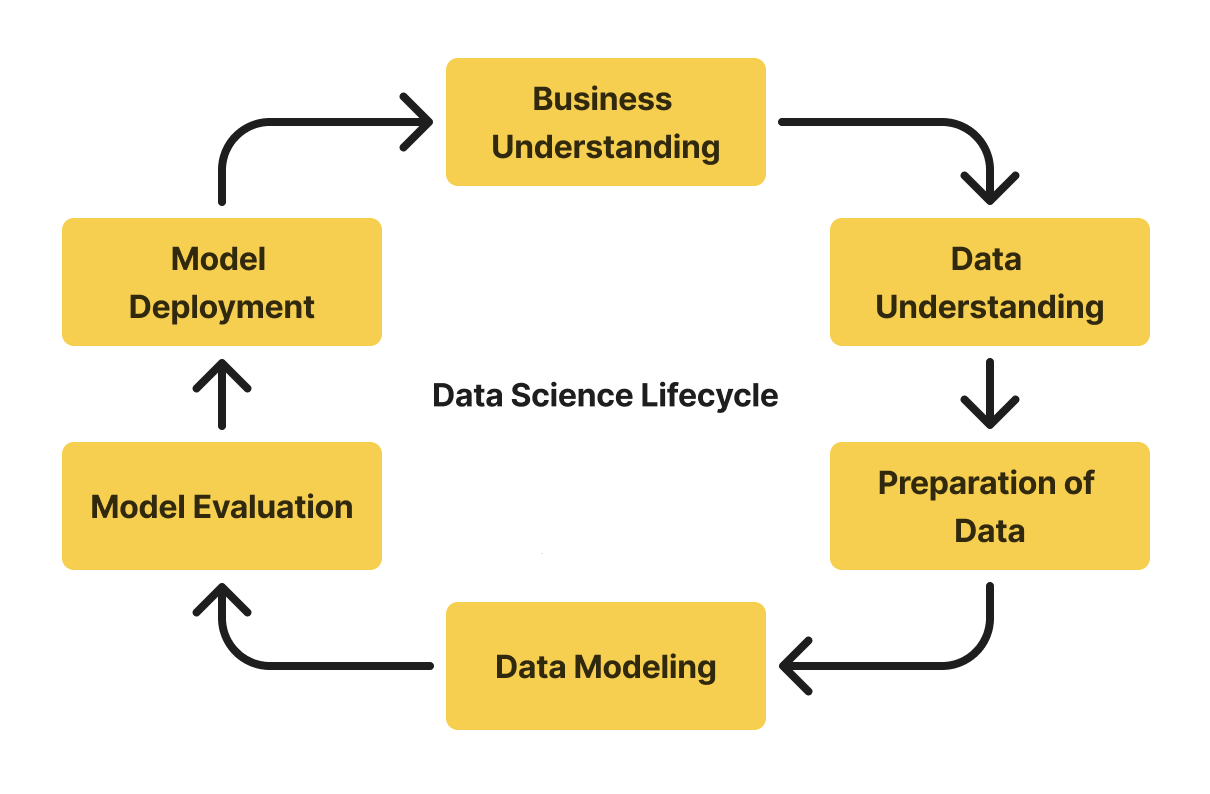
Business Understanding
Business Understanding is the first and arguably the most crucial stage of the Data Science Lifecycle. Before diving into the technical aspects of data science, it’s essential to fully understand the business problem you’re trying to solve. This ensures that the data science efforts are aligned with the organization’s strategic goals, and the insights produced are actionable and valuable.
1. Stakeholder Alignment
One of the first steps in business understanding is engaging with key stakeholders, such as business managers, product owners, and domain experts. These individuals can help articulate the business problem and define the expected outcomes. For example, in an e-commerce setting, a business objective could be to increase customer retention through more personalized recommendations.
- Key Questions:
- What is the primary business objective?
- How can data science help achieve this goal?
- Who will benefit from the insights and predictions generated?
Close collaboration with stakeholders is essential for identifying the right metrics and success indicators that will define the project’s success.
2. Defining Key Performance Indicators (KPIs)
Once the business objectives are clear, the next step is to define KPIs that will measure the success of the project. KPIs provide a quantifiable measure of progress and help determine whether the data science solution meets the business needs.
For example, if the goal is to reduce customer churn, KPIs might include:
- Customer churn rate: The percentage of customers who stop using a service over a given time period.
- Customer lifetime value (CLTV): A prediction of the net profit attributed to the entire future relationship with a customer.
- Prediction accuracy: How well the data model predicts customer behavior in real-time.
These metrics offer a concrete way to assess the project’s success and allow for adjustments during the lifecycle if the initial goals are not being met.
3. Problem Scoping
Once business goals are clearly defined, it’s time to scope out the specific data science problem. This involves breaking down the business objective into smaller, manageable tasks that can be addressed using data science techniques. For example, if the goal is to increase sales through personalized marketing, the data science problem may revolve around building a recommendation engine using customer purchase data.
At this stage, it’s also important to consider the resources available, such as the type of data, technology stack, and personnel. Understanding the limitations and opportunities early on can save time and effort down the line.
4. Translating Business Objectives to Data Science Tasks
The final step in the business understanding phase is translating high-level business objectives into specific data science tasks. This step ensures that the solution is data-driven and addresses the actual business need.
For instance:
- Business Objective: Reduce customer churn.
- Data Science Task: Build a predictive model to identify customers who are most likely to churn in the next 30 days, so targeted marketing can be applied to retain them.
The key is to ensure that every technical task contributes directly to the overarching business goal.
Data Understanding
After the business objectives are clear, the next step in the Data Science Lifecycle is Data Understanding. In this phase, the primary goal is to explore the data to understand its characteristics, quality, and relevance to the business problem. A deep understanding of the data allows data scientists to make informed decisions regarding data preparation, feature engineering, and model selection in later stages.
1. Data Collection
The first task in data understanding is acquiring the right data from various sources. Depending on the project, data might come from internal databases, external APIs, public datasets, or even web scraping.
Common data sources include:
- Databases: Structured data stored in relational databases (e.g., SQL).
- APIs: Data from third-party services such as financial markets or social media.
- Web scraping: Automated collection of data from web pages.
- Surveys or logs: Direct feedback or usage data collected from users.
The data collected should be relevant to the business problem and comprehensive enough to support the analysis.
2. Data Exploration
Once the data is collected, the next step is exploratory data analysis (EDA). This step involves summarizing the main characteristics of the data to uncover initial patterns, spot anomalies, and check assumptions.
Techniques in Data Exploration:
- Summary Statistics: Calculating metrics like mean, median, variance, and standard deviation to understand data distributions.
- Visualizations: Using charts (e.g., histograms, scatter plots) to visualize relationships between variables and detect trends or outliers.
- Correlation Analysis: Identifying how variables are related, which helps in feature selection for modeling.
Through data exploration, insights such as missing values, extreme outliers, or correlations between variables can be identified, helping shape the next steps in the lifecycle.
3. Data Quality Assessment
Understanding the quality of the data is a key part of this phase. Poor-quality data can lead to inaccurate models and misleading insights, making it crucial to assess the data early on.
Key aspects of data quality include:
- Missing Data: If key information is missing in certain records, strategies like imputation or data removal might be necessary.
- Outliers: Unusually high or low values can distort analyses. Depending on the context, outliers can either be removed or treated carefully.
- Consistency: The data should be consistent in terms of format, units, and ranges (e.g., ensuring date formats are uniform, categorical variables are coded consistently).
4. Data Relevance
After assessing data quality, it’s important to evaluate whether the data is relevant to the problem you’re trying to solve. Irrelevant data or noise can add complexity to the analysis and reduce model performance. During this phase, data scientists also ensure that enough features (variables) are available to capture meaningful patterns related to the business objective.
For example, in a customer churn prediction project, knowing customer interaction history, purchase patterns, and service usage could be more relevant than demographic data alone.
5. Hypothesis Generation
Based on data exploration and quality checks, data scientists can begin generating hypotheses about relationships in the data that might influence the business outcome. These hypotheses can guide the next phase of the lifecycle, such as which features to focus on or which models may perform best.
For example:
- Hypothesis: Customers who have not made a purchase in the last 60 days are more likely to churn.
- Hypothesis: An increase in browsing time on the website correlates with a higher likelihood of making a purchase.
These hypotheses can be tested and validated later during the modeling phase.
Preparation of Data
In the Data Preparation phase, the focus is on transforming the raw data into a clean and structured format that’s ready for modeling. This step is crucial because well-prepared data improves the performance and reliability of machine learning models.
1. Data Cleaning
This involves handling missing data, correcting errors, and removing duplicates. Methods such as imputation (filling in missing values) or simply dropping incomplete records are commonly used. The goal is to ensure that the dataset is accurate and free of inconsistencies.
2. Data Transformation
Data transformation refers to converting raw data into a suitable format. For example, scaling numeric values (using min-max or standard scaling), encoding categorical variables, and normalizing data help make features more appropriate for algorithms.
3. Feature Selection and Engineering
At this stage, relevant features (variables) are selected based on their importance to the model’s performance. Feature engineering involves creating new features or modifying existing ones to improve the model’s accuracy.
For example, if date and time information is important, new features like “day of the week” or “time of day” can be extracted to give the model more insight.
Exploratory Data Analysis (EDA)
Exploratory Data Analysis (EDA) is a crucial step in the data science process where data scientists explore the data to uncover patterns, spot anomalies, and test hypotheses before moving on to modeling. It helps refine understanding and guide the direction of further analysis.
1. Data Visualization
Data visualization tools like histograms, scatter plots, and box plots are used to observe relationships between variables and detect outliers or trends. For instance, visualizing sales data might reveal seasonality or trends that need to be accounted for in a model.
2. Statistical Summaries
Simple statistical methods such as mean, median, variance, and standard deviation provide quick insights into data distributions. These summaries help you understand the range, central tendencies, and variability in the data.
3. Hypothesis Testing
During EDA, data scientists often test initial hypotheses to confirm assumptions. For example, they might check if higher website activity correlates with higher purchase likelihood, guiding the selection of features for modeling.
Data Modeling
1. Model Selection
Selecting the appropriate model is key to success. Common models include:
- Linear regression for predicting continuous outcomes.
- Decision trees or random forests for classification or regression tasks.
- Neural networks for complex data patterns, especially in image and language tasks.
The choice depends on the problem and the type of data available.
2. Model Training
Once the model is chosen, it is trained on the dataset to learn patterns. Training involves feeding the model with data and adjusting its parameters to minimize errors.
3. Model Evaluation
Models are evaluated using performance metrics such as:
- Accuracy for classification tasks.
- RMSE (Root Mean Square Error) for regression.
- Precision, recall, F1-score for imbalanced datasets.
Model evaluation ensures the model performs well on unseen data.
Model Evaluation
Model Evaluation focuses on assessing the performance of a model to ensure it meets business requirements and performs well on new, unseen data.
1. Performance Metrics
Common metrics include:
- Accuracy: Measures the proportion of correctly classified instances.
- Precision, Recall, F1-Score: Used for imbalanced datasets to balance false positives and negatives.
- Root Mean Square Error (RMSE): Measures the differences between predicted and actual values in regression tasks.
2. Model Comparison
Multiple models are often trained and evaluated to determine which performs best. Cross-validation techniques (e.g., k-fold cross-validation) ensure that models generalize well and don’t overfit the data.
Model Deployment
Once a model has been trained and evaluated, the next step is Model Deployment, where the model is integrated into a live production environment to generate predictions or insights that can be used by the business.
1. Deployment Strategies
Models can be deployed in several ways depending on the business’s infrastructure:
- Cloud-based deployment: Models are hosted on cloud platforms like AWS or Google Cloud, allowing them to scale and be accessed by multiple users.
- On-premises deployment: Some organizations may prefer deploying models on their own servers due to data security concerns.
2. Monitoring and Maintenance
Once deployed, models must be monitored to ensure they continue to perform well. Key tasks include:
- Model Drift: Over time, data patterns may change, causing the model to lose accuracy. Regular monitoring helps detect these shifts.
- Retraining: Periodically updating the model with new data helps maintain its relevance and performance in changing environments.
Conclusion
The Data Science Lifecycle provides a structured approach to transforming raw data into actionable insights through stages like data acquisition, cleaning, feature engineering, modeling, and deployment. Each phase ensures that data science projects align with business objectives, offering value through informed decision-making. By following established frameworks like CRISP-DM and continuously monitoring models post-deployment, organizations can maximize the effectiveness of their data-driven strategies. As data science evolves, mastering these processes will remain crucial for staying competitive and innovative.


