Data preprocessing is a critical first step in data science that ensures the quality and reliability of datasets used for analysis. Raw data often contains noise, inconsistencies, and missing values, all of which can hinder model performance. Poor-quality data leads to inaccurate outcomes, regardless of how sophisticated the model is. Preprocessing addresses these issues, transforming raw data into clean and structured formats that allow algorithms to function effectively. In this article, we will explore the importance of data preprocessing, its key techniques, and how it is applied in various industries to improve the accuracy of machine learning models.
Understanding Data in Data Science
Data Types
In data science, data can be broadly categorized into three types:
- Structured Data: This refers to data that is organized into rows and columns, such as in relational databases or spreadsheets. Structured data is easy to analyze using traditional statistical methods. Examples include sales records, employee data, and transaction logs.
- Unstructured Data: Unstructured data lacks a predefined format, making it more challenging to process. Examples include images, videos, social media posts, and audio files. Analyzing unstructured data requires advanced techniques like natural language processing (NLP) or image recognition.
- Semi-Structured Data: This type lies between structured and unstructured data. It doesn’t conform to a rigid structure but contains tags or markers that make it easier to process. Common examples include JSON files, XML files, and log data from servers.
Data Summary
Before diving into preprocessing, it’s essential to generate a summary of the data to understand its structure and content. This includes:
- Descriptive Statistics: Summarizing numerical data through means, medians, and standard deviations.
- Data Visualization: Graphical tools like histograms or scatter plots help identify trends, patterns, and anomalies.
- Initial Assessments: Detecting outliers, missing values, or inconsistencies to determine the appropriate preprocessing steps.
Understanding the type and state of the data provides the groundwork for effective preprocessing.
What is Data Preprocessing?
Data preprocessing refers to the critical steps applied to raw data to make it suitable for analysis. These steps involve cleaning, transforming, and integrating the data so that it becomes structured and free of noise. Without preprocessing, raw data may be inconsistent, incomplete, or too complex to be used directly in machine learning models.
Preprocessing also involves data wrangling, a step where data is reshaped, and inconsistencies are removed. For example, timestamps may be reformatted into a standard structure, categorical data might be encoded as numerical values, and missing data can be imputed or removed altogether.
Unlike data preparation, which is more about organizing data for storage, preprocessing is directly aimed at improving data quality for modeling. Machine learning models, in particular, require well-preprocessed data to avoid overfitting, underfitting, or inaccurate predictions.
Key objectives of data preprocessing include:
- Ensuring consistency in data formats.
- Removing redundant or irrelevant features.
- Making data more accessible to machine learning algorithms through scaling or encoding.
Without proper preprocessing, even the best-designed models will struggle to provide meaningful or accurate results, making preprocessing a crucial component of data science projects.
Why is Data Preprocessing Important?
Data preprocessing is vital because raw data is rarely perfect. Real-world datasets typically suffer from several issues such as missing values, noise, and inconsistency. Without proper handling, these problems can skew the results of any analysis or model. Preprocessing addresses these issues by cleaning the data and transforming it into a format that is optimal for analysis.
Here are key reasons why data preprocessing is essential:
- Handling Missing Data: Missing values can distort analyses, leading to biased results. Imputing missing data or removing incomplete records ensures that the dataset remains reliable and representative of the problem being addressed.
- Reducing Noise: Noise in data refers to irrelevant or redundant information that does not contribute to understanding the problem. Preprocessing techniques like filtering and smoothing help eliminate this noise, allowing the model to focus on the essential data points.
- Ensuring Consistency: When datasets come from different sources, they may have inconsistent formats. For instance, one dataset might record dates in DD/MM/YYYY format, while another uses MM/DD/YYYY. Preprocessing standardizes these formats.
- Improving Model Performance: Clean and well-structured data ensures that machine learning algorithms can learn effectively. This leads to better performance in tasks like classification, regression, or clustering.
Ultimately, preprocessing makes datasets usable, ensuring that models are trained on accurate, consistent, and meaningful data, thereby improving the quality and reliability of predictions.
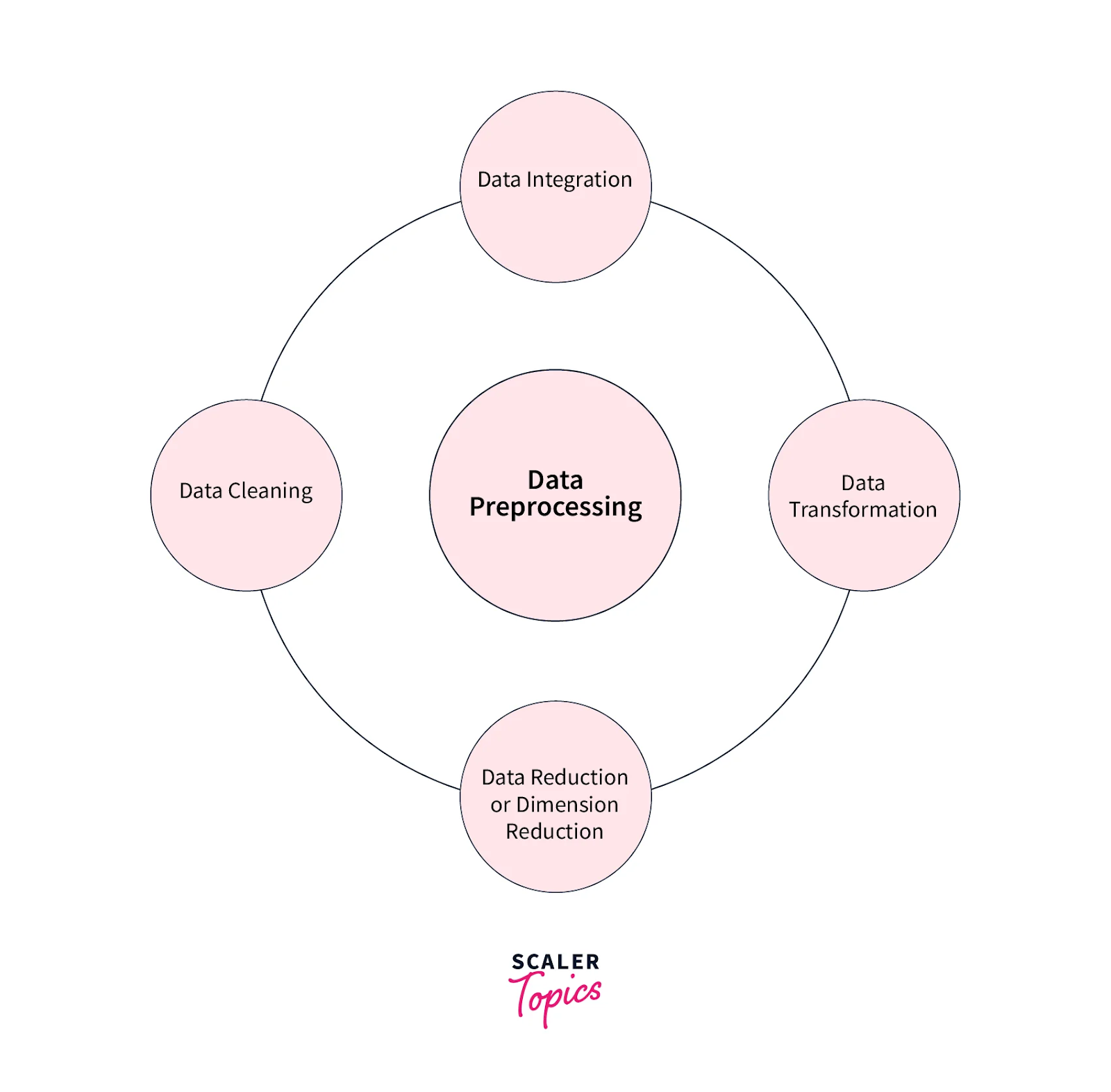
Key Steps in Data Preprocessing
Source: SCALER
1. Data Cleaning
Data cleaning is one of the most crucial steps in preprocessing. It involves:
- Handling Missing Values: Methods include deleting rows with missing data or using techniques like mean or median imputation.
- Dealing with Outliers: Outliers can distort analysis, and techniques like z-score normalization can help detect and remove them.
- Reducing Noise: Noisy data (errors or irrelevant information) can be smoothed using binning, regression, or clustering techniques.
2. Data Integration
Data integration combines data from multiple sources into a coherent dataset. This is critical in industries where data is collected from various systems, such as customer data from multiple sales channels. Integration ensures that the merged dataset is complete and avoids data redundancy.
- Example: A retail company might need to integrate sales data from online and physical stores to get a complete picture of customer behavior.
3. Data Transformation
Data transformation involves converting data into a suitable format for analysis. This step includes:
- Normalization: Adjusting data to a common scale (e.g., using min-max scaling or Z-score normalization).
- Encoding: Converting categorical data into numerical format (e.g., one-hot encoding).
- Example: In customer data, transforming age into age ranges (e.g., 18-25, 26-35) can improve model interpretability.
4. Data Reduction
Large datasets often contain irrelevant or redundant features, making models unnecessarily complex. Data reduction techniques such as:
- Principal Component Analysis (PCA): Reduce the dataset’s dimensionality while preserving as much variance as possible.
- Feature Selection: Identify the most relevant features and discard the rest to simplify the model and reduce computation time.
5. Data Wrangling
Data wrangling involves reshaping and transforming the dataset into the desired format for analysis. This step is often used when datasets are complex or unstructured.
- Example: Transforming a dataset that logs timestamps into separate date, time, and year columns to enable easier analysis.
Effective data wrangling ensures that datasets are clean, well-structured, and ready for model input.
Data Preprocessing Techniques
Data Cleansing
Data cleansing identifies and resolves issues in datasets, such as duplicate records, inconsistent formatting, or erroneous data types. For example, dates stored as strings need to be converted to a date-time format for proper analysis. Cleansing removes these issues, ensuring a dataset is error-free.

Source: SCALABLE PATH
Feature Engineering
Feature engineering involves creating new variables or modifying existing ones to enhance the model’s predictive power. This step requires domain knowledge to derive meaningful features.
Common Feature Engineering Examples:
- Date and Time Features: Deriving new features from a timestamp, such as extracting the day of the week or hour of the day, which can be significant in time-sensitive applications.
- Combining Features: Creating interaction terms between features to capture more complex relationships in the data.
Dimensionality Reduction
Dimensionality reduction reduces the number of variables or features in a dataset, simplifying the model while retaining important information. Techniques such as Principal Component Analysis (PCA) and t-SNE are commonly used to reduce the feature set while preserving variability and improving computation speed.
Dimensionality reduction is especially useful for large datasets, such as image data or high-dimensional customer data, where the sheer number of features can overwhelm a machine learning model.
Applications of Data Preprocessing
Data preprocessing is indispensable across industries:
- Healthcare: In healthcare, preprocessing patient records, medical imaging, and wearable sensor data ensures that models predicting disease risks or outcomes are based on clean, accurate data.
- Finance: In the financial sector, accurate preprocessing of stock market data, transaction records, and historical prices ensures that models used for risk assessment and fraud detection yield reliable results.
- E-commerce: Preprocessing is critical for building recommendation engines, where data from customer interactions, reviews, and purchases are transformed into structured data that can be used by recommendation algorithms.
- Manufacturing: Preprocessing sensor data from industrial machines helps predict equipment failures and schedule maintenance, reducing downtime and improving efficiency.
Challenges in Data Preprocessing
Preprocessing comes with its own set of challenges:
- Scalability: Preprocessing large datasets is resource-intensive and time-consuming. Techniques like distributed computing (e.g., Apache Spark) or efficient algorithms (like batch processing) are necessary to handle big data.
- Automation: Each dataset is unique, making it difficult to automate preprocessing fully. Human oversight is often needed to adjust preprocessing techniques to the specific characteristics of the data.
- Data Privacy: Handling sensitive data like customer information or medical records during preprocessing requires compliance with privacy regulations, adding complexity to the process.
Despite these challenges, the benefits of preprocessing—improving data quality, enhancing model performance, and ensuring accurate predictions—are well worth the effort.
Conclusion
Data preprocessing is an essential part of the data science workflow, transforming raw, unstructured data into a format suitable for analysis. Through techniques such as data cleaning, transformation, integration, and feature engineering, preprocessing prepares data for accurate and efficient machine learning model training. Regardless of the industry—be it healthcare, finance, or e-commerce—preprocessing ensures that models can perform at their best, providing actionable insights. Though it comes with challenges like scalability and automation, preprocessing remains critical to building robust and accurate models. Investing time in proper data preprocessing ultimately pays off in improved model performance and better decision-making.
References:
- Data Preprocessing in Data Science – Scaler Topics
- Data Preprocessing: Definition, Key Steps and Concepts
- Data Preprocessing – an overview | ScienceDirect Topics


