Data integration in data mining is the process of combining data from multiple sources into a unified view for efficient analysis. It plays a crucial role in merging structured and unstructured data, allowing organizations to derive meaningful insights.
Ensuring data consistency, accuracy, and accessibility is essential for maintaining high-quality datasets. Without integration, businesses face challenges such as data silos, inconsistencies, and duplication, which can hinder decision-making.
By integrating data from different platforms such as databases, cloud storage, and applications, organizations can improve analytics, streamline operations, and enhance decision-making processes. Effective data integration enables real-time insights, supports big data processing, and strengthens business intelligence strategies across industries.
What is Data Integration in Data Mining?
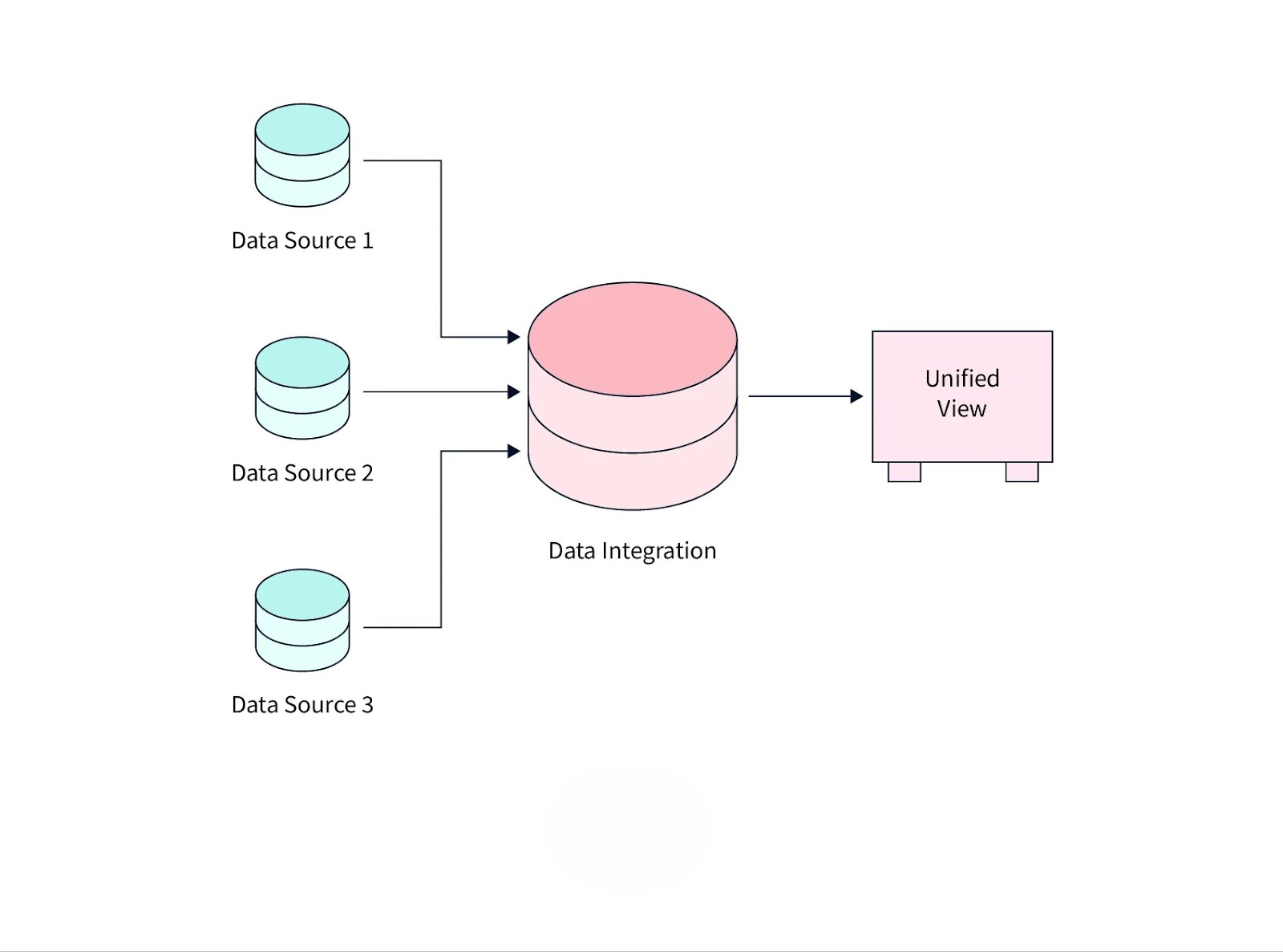
Data integration in data mining is the process of combining structured and unstructured data from different sources into a unified dataset. It enables organizations to analyze large volumes of data more effectively by eliminating inconsistencies and redundancies.
In big data analytics, data integration plays a critical role in consolidating information from multiple platforms, such as databases, cloud storage, and enterprise applications. It supports business intelligence by providing a single, reliable view of data, which helps in strategic decision-making. In cloud computing, data integration ensures seamless access to information across distributed environments.
For example, an e-commerce company may integrate customer data from various sales channels, including online stores, social media, and physical outlets. By consolidating this information, businesses can analyze purchasing patterns, improve customer experience, and optimize marketing strategies.
Why is Data Integration Important?
Data integration is essential for organizations looking to maximize the value of their data. By combining information from multiple sources, it ensures consistency, accessibility, and reliability in data-driven decision-making.
One of the primary benefits of data integration is the elimination of data silos. When information is stored across different systems without connectivity, it becomes difficult to access and analyze. Integration breaks these silos, enabling a unified view of data across departments and applications.
Another key advantage is improved data quality. By consolidating datasets, integration reduces inconsistencies, redundancies, and errors, ensuring that businesses work with accurate and reliable information.
Data integration also enhances the speed of data analysis. With real-time access to well-structured and unified data, organizations can generate insights faster, allowing for quicker decision-making in critical areas such as finance, customer management, and operations.
Effective data integration is a foundational element in business intelligence, big data analytics, and enterprise data management.
Data Integration Approaches
Data integration can be achieved through different approaches, depending on the organization’s requirements for data storage, processing, and accessibility. The two primary approaches are tight coupling and loose coupling, each offering unique advantages based on performance and flexibility.
Tight Coupling
Tight coupling refers to a centralized approach where data from multiple sources is physically integrated into a data warehouse or a single repository. This method ensures that all data is cleaned, transformed, and stored in a structured format before analysis.
Benefits of Tight Coupling:
- Provides faster query execution since data is already aggregated.
- Ensures consistency and standardization by storing data in a common format.
- Enables comprehensive analytics and reporting from a unified data source.
This approach is commonly used in enterprise data warehouses where structured data from different business units is merged for deep analytical insights.
Loose Coupling
Loose coupling relies on middleware, data virtualization, or federated databases to provide on-demand access to distributed data sources without physically moving or storing the data in one location. Instead of creating a centralized repository, this approach enables data access from different systems dynamically.
Benefits of Loose Coupling:
- Greater flexibility since data remains in its original source.
- Scalability by allowing integration across multiple systems without extensive restructuring.
- Reduces storage costs as data is not duplicated into a central repository.
Loose coupling is widely used in real-time applications where data is frequently updated across multiple databases, such as cloud-based analytics and distributed financial systems.
Both approaches serve different needs, with tight coupling being ideal for structured, long-term storage and analysis, while loose coupling offers agility and real-time data access.
Common Issues in Data Integration
Data integration presents several challenges that can affect data quality and consistency. These issues arise when merging datasets from different sources, leading to conflicts in structure, duplication, and inconsistency.
1. Schema Integration
Schema integration refers to the challenge of combining data from different databases with varying structures. Differences in naming conventions, data types, and table relationships can create conflicts when merging datasets.
Example: A customer database in one system might store customer names under the field “cust_name”, while another system uses “customer_fullname”. Integrating such databases requires mapping these fields correctly to avoid mismatches.
2. Redundancy Detection
Duplicate records often exist when data is integrated from multiple sources, leading to redundant or inconsistent entries. Detecting and eliminating these duplicates is critical to maintaining data accuracy.
Example: A single customer may appear multiple times in a database under different IDs due to variations in how their information was entered, such as “John Doe” vs. “J. Doe”. Integration processes must include deduplication techniques to remove such inconsistencies.
3. Resolution of Data Value Conflicts
Data conflicts occur when the same data point has different values in different sources. These inconsistencies can result from different data formats, measurement units, or recording standards.
Example: A global business might store financial data in different currencies, such as USD in one system and EUR in another. Without proper currency conversion, integration errors can lead to incorrect financial reports.
Addressing these issues requires data cleansing, transformation, and validation techniques to ensure that integrated datasets are accurate and reliable for analysis.
Data Integration Techniques
Different techniques are used to integrate data based on the complexity, scale, and requirements of an organization. These techniques ensure seamless access, transformation, and consolidation of data from various sources.
1. Manual Integration
In manual integration, data is extracted, cleaned, and merged manually by users before analysis. This approach is suitable for small-scale operations where data sources are limited.
Pros:
- Simple to implement without additional tools.
- Provides control over data merging.
Cons:
- Error-prone due to human involvement.
- Time-consuming and inefficient for large datasets.
2. Middleware Integration
Middleware tools act as intermediaries between multiple databases and applications, ensuring seamless data exchange. This technique enables real-time data updates across different systems.
Pros:
- Facilitates smooth communication between applications.
- Supports real-time data synchronization.
Cons:
- Requires additional software and maintenance.
- Can introduce latency if not optimized.
3. Application-Based Integration
Custom applications or APIs are developed to fetch and integrate data from various sources. This technique is commonly used in enterprise applications that require API-based connectivity.
Pros:
- Offers flexibility and customization.
- Works well with modern cloud-based systems.
Cons:
- Requires software development expertise.
- Integration complexity increases with system scale.
4. Uniform Access Integration
In this method, data remains physically separate in different systems but is accessed through a unified interface. This allows organizations to query multiple databases without moving data.
Pros:
- Eliminates the need for data duplication.
- Reduces storage costs.
Cons:
- Can be slower than centralized methods.
- Data retrieval depends on source system availability.
5. Data Warehousing
Data from multiple sources is extracted, transformed, and loaded (ETL) into a single storage repository for analytical processing. This technique is widely used for large-scale analytics and reporting.
Pros:
- Enables comprehensive historical data analysis.
- Provides a consistent and structured data format.
Cons:
- Requires significant storage resources.
- ETL processes can be complex and time-consuming.
Each technique serves different integration needs, and organizations choose methods based on data volume, performance requirements, and analytical goals.
Data Integration Tools
Various tools are available to facilitate data integration, ranging from on-premise solutions to cloud-based platforms. These tools help organizations streamline data merging, transformation, and analysis efficiently.
On-Premise Data Integration Tools
On-premise tools are installed and operated within an organization’s infrastructure, offering greater control and security over data.
Examples:
- Talend – Provides ETL (Extract, Transform, Load) capabilities for large-scale data integration.
- IBM InfoSphere – Offers data governance and real-time integration features for enterprise systems.
Open-Source Data Integration Tools
Open-source tools provide cost-effective integration solutions with flexible customization options.
Examples:
- Apache NiFi – Enables real-time data streaming and automation of data flows.
- Pentaho – A data integration and analytics platform with ETL capabilities.
Cloud-Based Data Integration Tools
Cloud-based tools allow organizations to integrate data across cloud environments with scalability and automation.
Examples:
- AWS Glue – A fully managed ETL service that prepares and transforms data for analytics.
- Google Cloud Data Fusion – Provides a no-code and code-based approach for cloud data integration.
Each tool serves different business needs, helping organizations efficiently integrate and manage their data across on-premise, open-source, and cloud environments.
Conclusion
Data integration is a critical process in data mining, ensuring that information from multiple sources is combined into a unified dataset for accurate analysis. By eliminating data silos, improving data quality, and enabling real-time insights, integration enhances business intelligence and decision-making.
Different approaches, such as tight and loose coupling, along with techniques like manual integration, middleware, and data warehousing, help organizations manage their data effectively. Various integration tools, including on-premise, open-source, and cloud-based solutions, provide flexible options for seamless data management.
To handle increasing data volumes efficiently, businesses should adopt automated data integration strategies that offer scalability, real-time processing, and minimal human intervention. As data complexity grows, integrating advanced solutions will be essential for leveraging big data analytics and gaining a competitive edge.
Read More:
References:


