Data ingestion is the process of importing, transferring, loading, and processing data from multiple sources into a storage system for further analysis. It serves as the first step in the data pipeline, ensuring that data from various structured and unstructured sources is collected and made available for analytics, reporting, and decision-making.
Unlike ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform), which focus on data transformation, data ingestion primarily emphasizes seamless data collection and movement before any processing occurs. It enables organizations to consolidate data from diverse sources such as databases, IoT devices, APIs, and cloud platforms into centralized repositories like data lakes or data warehouses.
For example, in real-time stock market analysis, data ingestion continuously collects and streams stock prices, trades, and news updates from multiple exchanges. This allows financial analysts and automated trading systems to make quick and informed investment decisions based on the most recent market trends.
Data ingestion plays a critical role in big data analytics, machine learning, and cloud computing, ensuring that data flows efficiently across enterprise systems and applications.
Why is Data Ingestion Important?
Data ingestion plays a crucial role in modern data-driven environments, ensuring that information from multiple sources is collected, processed, and made available for analysis. It enhances business intelligence and enables organizations to act on real-time insights efficiently.
Enables Real-Time Decision-Making
Businesses rely on real-time data ingestion to make informed decisions. Industries such as finance, e-commerce, and cybersecurity need immediate data updates to detect fraud, optimize pricing, and enhance user experiences. Without an efficient ingestion pipeline, delays in data collection could lead to missed opportunities or operational inefficiencies.
Supports Machine Learning and Analytics
Machine learning models require large volumes of accurate and up-to-date data to generate reliable predictions. Data ingestion ensures that structured and unstructured data from diverse sources is continuously supplied to data lakes, warehouses, and analytics platforms, enabling effective training and real-time inferencing for AI applications.
Reduces Latency in Data Workflows
In industries like finance, healthcare, and IoT, low-latency data ingestion is essential. For example, in healthcare, real-time patient monitoring systems ingest data from medical devices to provide instant alerts on critical health conditions. Similarly, IoT devices in smart cities require continuous data collection to manage traffic systems efficiently.
Types of Data Ingestion
Data ingestion can be classified into different types based on how data is collected, processed, and delivered to storage or analytics systems. Each method is suited for specific use cases, depending on factors like data volume, latency requirements, and processing speed.
1. Batch Processing
Batch processing collects data at scheduled intervals and processes it in bulk. This approach is commonly used when real-time updates are not required, allowing businesses to optimize resources by processing data at off-peak hours.
Example: E-commerce platforms generate transaction logs throughout the day, which are processed in batches overnight to update sales reports and inventory records.
2. Real-Time Data Ingestion
Real-time data ingestion continuously streams data as it is generated. This is essential for applications requiring instant data processing to support real-time decision-making.
Example: Banks use real-time data ingestion to detect fraudulent transactions. If an unusual spending pattern is identified, the system can immediately trigger security measures such as card blocking or customer alerts.
3. Streaming Data Processing
Streaming data processing involves ingesting data with low latency, ensuring that events are processed almost immediately after they occur. Technologies such as Apache Kafka, Apache Flink, and Apache Spark Streaming are used for handling streaming data efficiently.
Example: Live traffic monitoring systems use streaming data processing to analyze vehicle movement, detect congestion, and optimize traffic signals dynamically.
4. Micro-Batching
Micro-batching is a hybrid approach between batch and real-time processing, where small data chunks are ingested at high frequency. This method balances the efficiency of batch processing with the responsiveness of real-time ingestion.
Example: Smart cities use micro-batching for sensor data processing, where environmental sensors collect air quality data every few seconds and send it for near-real-time analysis.
5. Lambda Architecture for Data Ingestion
Lambda architecture combines batch processing for historical data with real-time ingestion for current data, providing a scalable and flexible ingestion strategy. It ensures that large-scale analytics systems can work with both historical trends and real-time insights.
Example: Healthcare monitoring systems use lambda architecture to analyze historical patient records while simultaneously processing real-time data from wearable health devices.
Choosing the right data ingestion type depends on business requirements, latency needs, and the complexity of data sources, ensuring that organizations optimize performance while maintaining data accuracy.
The Data Ingestion Pipeline
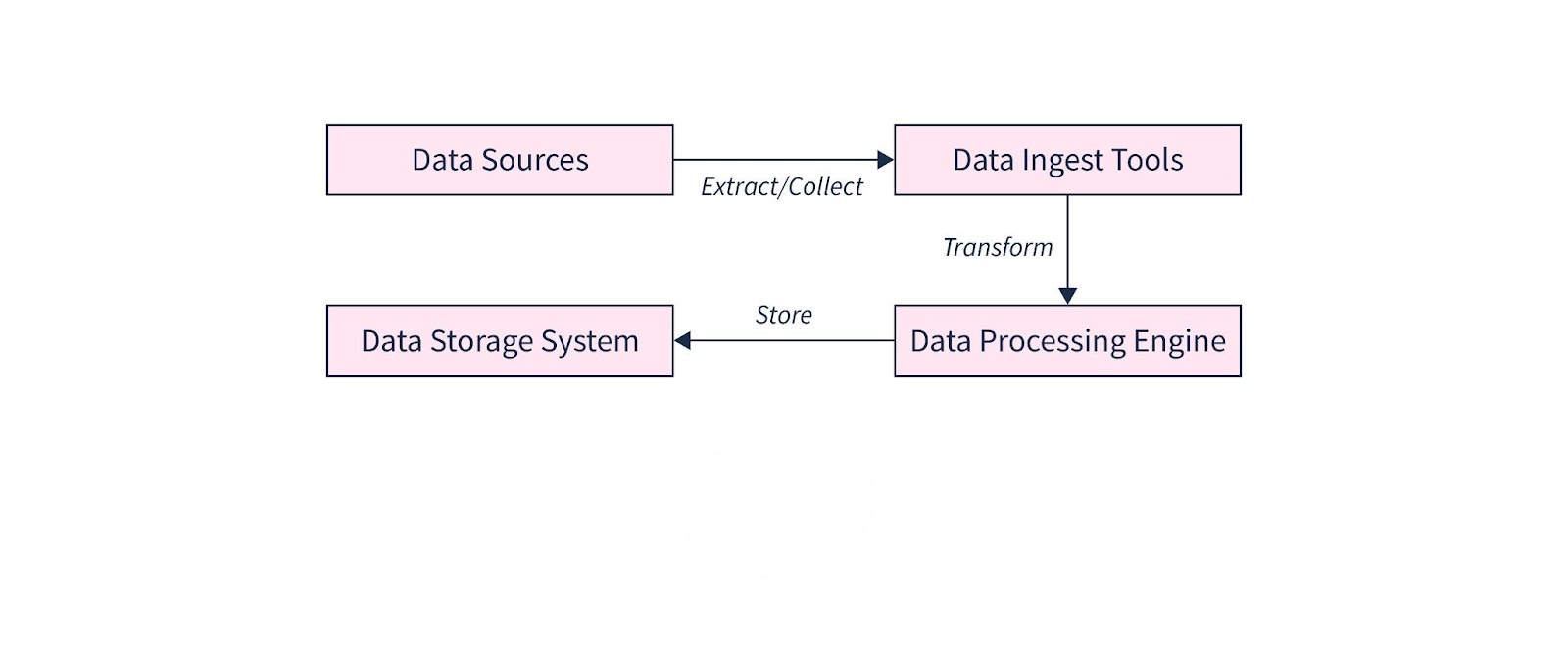
A data ingestion pipeline is a structured process that moves data from multiple sources to a centralized storage system for analysis. It ensures data is collected, processed, and stored efficiently, making it accessible for business intelligence and analytics.
Extracting Data from Sources
The first stage of the ingestion pipeline involves gathering data from various sources, including APIs, relational databases, IoT devices, cloud platforms, and third-party applications. The extracted data can be structured, semi-structured, or unstructured, depending on the source.
For example, an e-commerce platform collects customer behavior data from website interactions, mobile app usage, social media engagements, and sales transactions.
Transforming and Cleaning Data for Accuracy
Once extracted, data undergoes transformation and cleaning to remove inconsistencies and ensure accuracy. This includes standardization, deduplication, handling missing values, and converting data formats to maintain uniformity across systems.
For instance, customer transaction records from multiple sources might have different date formats, naming conventions, or redundant entries. Data transformation ensures a standardized format that can be processed efficiently.
Loading into a Data Warehouse or Lake for Analytics
The final stage involves loading the processed data into a storage system such as a data warehouse or data lake. Data warehouses store structured data optimized for analytical queries, while data lakes support a mix of structured and unstructured data.
In an e-commerce scenario, the integrated data is stored in a warehouse, allowing analysts to generate insights on customer preferences, purchase trends, and marketing effectiveness.
By following these steps, an ingestion pipeline ensures seamless data flow, enabling businesses to make data-driven decisions efficiently.
Data Ingestion vs. ETL vs. ELT
Data ingestion, ETL (Extract, Transform, Load), and ELT (Extract, Load, Transform) are key data integration methods, each designed for different processing needs. While data ingestion focuses on collecting and transferring data, ETL and ELT add transformation steps to structure the data for analytics.
| Feature | Data Ingestion | ETL (Extract, Transform, Load) | ELT (Extract, Load, Transform) |
| Processing Order | Transfers raw data as is | Transforms data before loading | Loads data first, then applies transformations |
| Use Case | Supports streaming and batch ingestion | Used for traditional data warehouses | Best suited for cloud-based analytics and big data processing |
| Example | IoT data streaming into a real-time database | Generating business reports from structured databases | AI and machine learning pipelines processing large datasets |
Key Differences
- Data ingestion is the broadest process, referring to collecting and moving data to a storage system, regardless of transformation.
- ETL transforms data before storing it, making it ideal for structured data and compliance-driven environments.
- ELT loads data first and transforms it later, leveraging the scalability of modern cloud platforms for big data processing.
Each approach serves different business needs, with ETL optimized for structured reporting, ELT for big data analytics, and data ingestion as the foundational process that enables both.
Benefits of Data Ingestion
Data ingestion ensures that organizations can efficiently collect, process, and analyze data, making it a vital component of modern data architecture.
- Improves Data Accessibility: A structured ingestion process ensures that data is collected from multiple sources and made readily available for analysis. This enhances efficiency in data-driven operations.
- Enhances Decision-Making: By supporting AI, business intelligence, and predictive analytics, data ingestion enables organizations to derive insights from real-time and historical data, improving strategic decisions.
- Supports Large-Scale Data Processing: Modern ingestion pipelines are built to handle terabytes of data, integrating with cloud platforms and distributed systems to process massive datasets efficiently.
- Reduces Latency for Real-Time Insights: Low-latency data ingestion allows businesses to act quickly on incoming data, enabling real-time monitoring, automation, and analytics-driven decision-making.
Challenges in Data Ingestion
Despite its advantages, data ingestion presents several challenges that organizations must address to ensure efficient and reliable data processing.
- Data Quality Issues: Data ingestion pipelines must handle duplicate, missing, or inconsistent data that can impact analytics accuracy. Without proper cleansing and validation mechanisms, poor-quality data can lead to incorrect insights and decisions.
- Security and Compliance: Organizations handling sensitive data must comply with regulations such as GDPR, HIPAA, and CCPA. Ensuring data encryption, access control, and proper auditing processes is critical to maintaining compliance and preventing data breaches.
- High Infrastructure Costs: Managing large-scale data ingestion requires significant computational resources. Ensuring scalability while optimizing storage, bandwidth, and processing costs can be a challenge, particularly in cloud-based environments.
- Data Schema Evolution: Database structures often change over time, requiring ingestion pipelines to adapt without disrupting existing workflows. Handling schema modifications dynamically prevents system failures and data inconsistencies.
Data Ingestion Tools
Various tools are available to facilitate data ingestion, each offering different capabilities based on scalability, automation, and integration with existing systems. These tools can be categorized into open-source, cloud-based, and enterprise solutions.
Open-Source Tools
Open-source data ingestion tools provide cost-effective and flexible solutions for managing data pipelines. They are widely used for real-time and batch processing.
- Apache NiFi – Automates data flow between systems with a user-friendly interface.
- Apache Kafka – Enables high-throughput, distributed, real-time data streaming.
- Talend – Provides ETL and data integration capabilities for structured and unstructured data.
Cloud-Based Solutions
Cloud-based ingestion tools are designed to handle large-scale data workloads with seamless integration into cloud storage and analytics platforms.
- AWS Glue – A fully managed ETL service that prepares and transforms data for analytics.
- Google Dataflow – Supports real-time and batch data processing using Apache Beam.
- Azure Data Factory – Enables data movement and transformation across cloud and on-premise environments.
Enterprise Data Ingestion Tools
Enterprise-grade tools provide advanced features for large organizations with complex data needs, offering automation, governance, and compliance support.
- IBM InfoSphere – Helps in high-volume data integration with built-in data governance.
- Informatica PowerCenter – Provides scalable data ingestion with strong security and compliance features.
Selecting the right tool depends on factors such as data volume, processing speed, security requirements, and cloud compatibility to ensure efficient and reliable data ingestion.
Use Cases and Applications of Data Ingestion
Data ingestion plays a crucial role in various industries by ensuring seamless data collection and processing. Different use cases highlight its importance in handling real-time, large-scale, and high-velocity data.
- Cloud Data Lake Ingestion: Organizations use cloud platforms like AWS, Google Cloud, and Azure to ingest structured and unstructured data into data lakes for real-time and batch processing. Cloud-based ingestion allows businesses to store, analyze, and retrieve large datasets efficiently while ensuring scalability.
- AI and Machine Learning Pipelines: AI and machine learning models require structured, high-quality data for accurate predictions. Data ingestion ensures that relevant data is collected, cleaned, and fed into ML pipelines, supporting applications such as fraud detection, recommendation systems, and natural language processing.
- Financial Market Data Streaming: Stock exchanges and trading platforms ingest high-velocity financial transactions in real-time to track market fluctuations, execute trades, and detect anomalies. Efficient ingestion pipelines enable financial institutions to make data-driven decisions instantly.
- Healthcare Data Processing: Patient monitoring systems and diagnostic applications rely on real-time data ingestion from medical devices, electronic health records, and wearables. This enables early detection of health risks and faster decision-making in critical care situations.
Future Trends in Data Ingestion
As data ingestion evolves, new technologies and methodologies are emerging to enhance efficiency, scalability, and automation. The future of data ingestion will be driven by AI, cloud-native solutions, and hybrid models.
Automated Data Ingestion with AI
AI-powered ingestion tools are transforming data pipelines by automating schema mapping, data quality checks, and anomaly detection. These intelligent systems reduce manual intervention, improve data accuracy, and streamline ingestion workflows.
Cloud-Native Data Ingestion
Serverless architectures are revolutionizing data ingestion by eliminating the need for dedicated infrastructure. Cloud-native ingestion solutions dynamically scale based on workload demand, reducing operational overhead and improving cost efficiency.
Hybrid Data Ingestion Models
Organizations are increasingly adopting hybrid models that integrate on-premises and cloud-based ingestion pipelines. This approach provides flexibility, ensuring seamless data movement while addressing security, compliance, and latency concerns.
With advancements in AI, cloud computing, and hybrid architectures, data ingestion will continue to evolve, making real-time and large-scale data processing more accessible and efficient.
Read More:
References: