Data extraction refers to the process of retrieving data from various sources, such as databases, websites, and files, for further processing or analysis. It plays a vital role in modern data management by enabling organizations to access critical information. This empowers data-driven decision-making and supports analytics and business strategies.
Want to learn more about Data Analytics, click here.
What is Data Extraction?
Data extraction is the process of retrieving structured or unstructured data from various sources, such as databases, files, APIs, or websites, for further analysis or processing. It serves as the foundational step in a data pipeline, ensuring that raw data is collected and prepared for transformation and integration into a centralized system, like a data warehouse or a data lake.
In a typical data pipeline, extraction is followed by data transformation and loading, collectively referred to as ETL (Extract, Transform, Load). Extraction focuses solely on gathering data in its raw form without altering its structure. The extracted data is often stored temporarily before being cleaned and formatted for further use.
A common misconception is equating data extraction with data scraping. While both involve retrieving data, data extraction retrieves data from structured sources like databases or APIs, often requiring authentication or predefined schemas. On the other hand, data scraping targets unstructured data from websites or non-standardized sources, often bypassing traditional APIs.
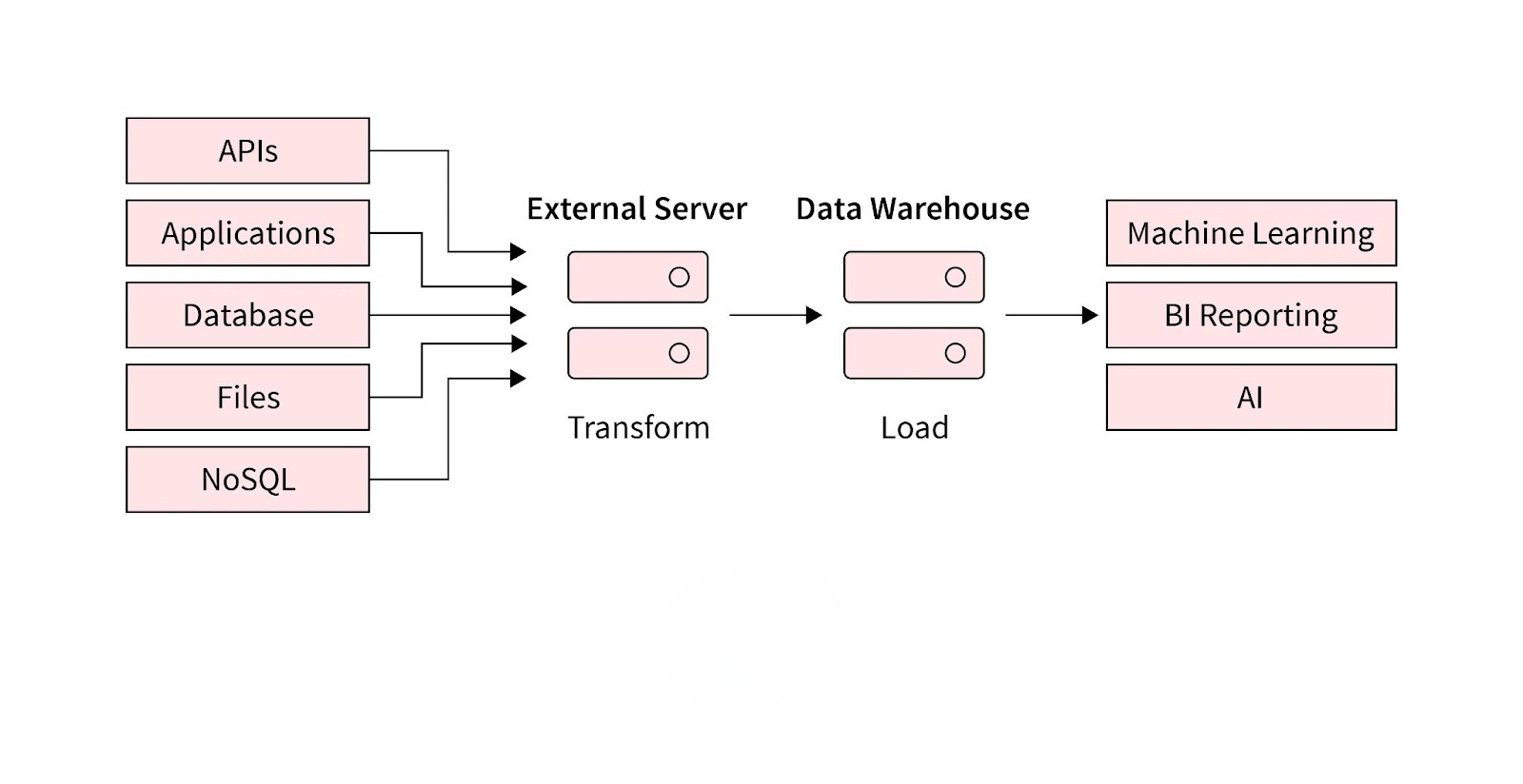
Data extraction is pivotal for businesses, enabling seamless access to diverse datasets needed for analytics, reporting, and decision-making. This step is critical in ensuring data accuracy and relevance in modern, data-driven workflows.
Data Extraction and ETL (Extract, Transform, Load)
Data Extraction is the critical first step in the ETL (Extract, Transform, Load) process, which forms the backbone of modern data management workflows. ETL is a method used to move data from various sources, transform it into a desired format, and load it into a data warehouse or analytics platform for decision-making.
Steps Involved in ETL:
- Extract: Data is gathered from different sources such as relational databases, APIs, flat files, or web pages. For example, extracting customer data from CRM systems enables businesses to analyze customer behaviors.
- Transform: Extracted data undergoes cleaning, deduplication, and formatting to ensure compatibility with the target system. For instance, combining sales data from various regions into a unified format for reporting.
- Load: The processed data is loaded into a central repository like a data warehouse. This enables faster querying and efficient reporting.
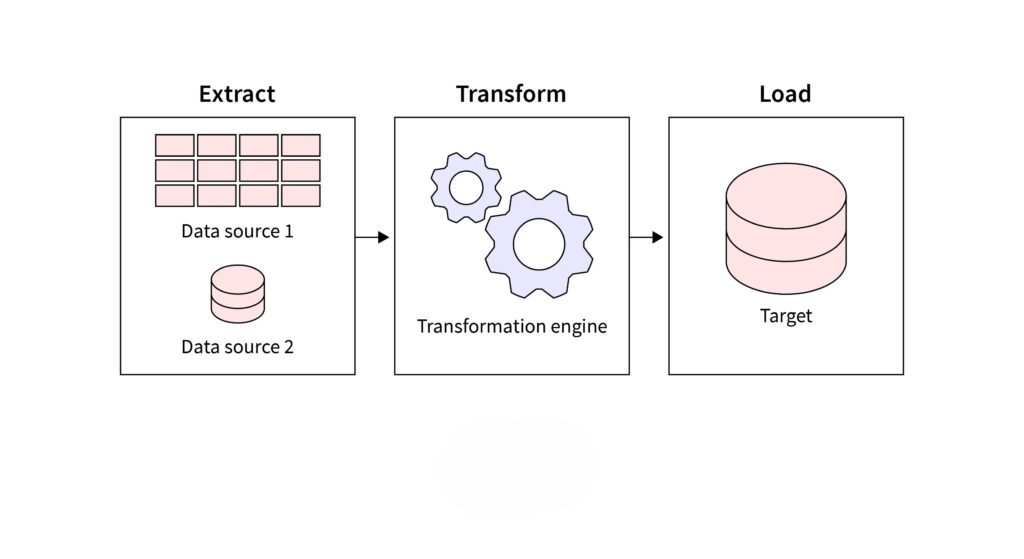
Importance of Data Extraction in ETL:
Extraction lays the foundation for all subsequent steps in the ETL workflow. Without reliable extraction, the transformation and loading stages become prone to errors and inefficiencies. For example, extracting incomplete or outdated data can lead to flawed analytics and poor business decisions.
In addition, effective data extraction ensures the integration of diverse data sources, paving the way for accurate and meaningful analysis. It also supports real-time data processing by continuously feeding new information into the pipeline.
Data Extraction without ETL
While data extraction is often part of the ETL (Extract, Transform, Load) process, there are scenarios where it operates independently. Standalone data extraction is typically employed for targeted tasks where transformation and loading are unnecessary or handled separately.
Situations for Independent Data Extraction:
- Ad-hoc Analysis: Extracting specific data sets directly from sources like databases or APIs for immediate analysis, bypassing the need for transformation or loading.
- Data Archiving: Extracting historical data from legacy systems for secure storage without integrating it into a larger system.
- Real-Time Insights: Gathering live data from sources like web applications or IoT devices for instant monitoring or decision-making.
Examples of Standalone Extraction:
- Market Research: Pulling survey data directly from platforms like Google Forms to analyze responses.
- Customer Insights: Exporting user behavior data from a CRM for campaign personalization.
- Financial Reporting: Extracting transaction records from accounting software for regulatory compliance.
Standalone extraction proves invaluable in providing quick access to critical information without the overhead of complete ETL workflows.
Types of Data Extraction
Data extraction can be categorized based on the method and purpose, ensuring tailored solutions for diverse use cases.
1. Full Extraction
Full extraction involves retrieving the entire dataset from a source without considering prior changes or updates. This method is typically used during initial data migration or when the source data is relatively small.
Scenarios:
- Migrating data from legacy systems to a modern database.
- Creating backups of entire datasets for archival purposes.
Advantages:
- Provides a complete snapshot of the data.
- Straightforward and easy to implement.
Disadvantages:
- Time-consuming and resource-intensive for large datasets.
- Repeated full extractions can lead to redundancy.
2. Incremental Extraction
Incremental extraction retrieves only the data that has changed since the last extraction. It is ideal for scenarios requiring regular updates without reprocessing the entire dataset.
Scenarios:
- Maintaining real-time dashboards with updated information.
- Syncing transactional data between systems.
Advantages:
- Efficient in terms of time and computational resources.
- Reduces storage requirements by avoiding redundant data.
Challenges:
- Requires robust tracking mechanisms for data changes.
- May involve complex logic to detect and extract updated records.
3. API-Based Extraction
This method leverages APIs to extract specific data points directly from applications or systems, offering granular control over what is retrieved.
Scenarios:
- Pulling user analytics data from platforms like Google Analytics.
- Integrating data from third-party applications into internal systems.
Advantages:
- Precise and customizable data retrieval.
- Real-time access to specific datasets.
Challenges:
- Subject to API rate limits and downtime.
- Requires handling diverse data formats and ensuring compatibility.
Each type of extraction has its unique strengths, ensuring flexibility for varied data requirements.
Data Extraction Tools
Several tools streamline the data extraction process, making it more efficient and reliable for businesses. Below are some popular options:
1. Talend
Talend is an open-source platform offering comprehensive data integration solutions, including data extraction.
Features:
- Supports various data sources like databases, APIs, and flat files.
- Drag-and-drop interface for ease of use.
Benefits: - Strong community support and extensive documentation.
Best For: Enterprises looking for an all-in-one data integration solution.
2. Apache NiFi
Apache NiFi automates the flow of data between systems, ensuring secure and real-time data extraction.
Features:
- Built-in processors for data routing, transformation, and extraction.
Benefits: - High scalability and fault tolerance.
Best For: Organizations managing large-scale, real-time data flows.
3. Fivetran
Fivetran is a fully managed platform designed for extracting and loading data into data warehouses.
Features:
- Automated schema updates and error handling.
Benefits: - Minimal maintenance and fast setup.
Best For: Businesses seeking a plug-and-play data pipeline solution.
Criteria for Selection
When choosing a tool, consider:
- Data Sources: Ensure compatibility with your data systems.
- Ease of Use: Look for user-friendly interfaces for quick deployment.
- Scalability: Verify the tool can handle your data volume.
- Cost: Balance features against budget constraints.
Benefits of Using Data Extraction Tools
Data extraction tools play a critical role in modern data management by simplifying and automating complex processes. Here are some key benefits:
1. Efficiency in Handling Large Volumes of Data
Data extraction tools streamline the processing of massive datasets from diverse sources, enabling faster data collection and integration. This efficiency allows organizations to focus on analysis rather than manual data retrieval.
2. Automation of Repetitive Tasks
With automated workflows, these tools eliminate the need for manual interventions in repetitive tasks such as file transfers, data formatting, and loading. Automation reduces human error and saves valuable time for data teams.
3. Improved Data Accuracy and Consistency
By applying standardized processes, data extraction tools ensure the data is consistent, clean, and ready for analysis. Features like error handling, data validation, and logging enhance overall data quality.
Examples and Use Cases of Data Extraction
Data extraction enables organizations across industries to harness the full potential of their data. Here are some key examples and use cases:
1. E-Commerce: Customer Behavior Analysis
E-commerce platforms leverage data extraction to analyze customer behavior, preferences, and purchasing patterns. Extracted data from web platforms, such as website activity logs and social media interactions, helps businesses design personalized marketing strategies and improve user experiences.
2. Healthcare: Patient Record Integration
Healthcare providers utilize data extraction to integrate patient records from multiple systems, such as hospital databases, insurance claims, and wearable health devices. This unified data enables accurate diagnoses, personalized treatment plans, and improved patient care.
3. Education: Data-Driven Curriculum Design
Educational institutions use data extraction to analyze student performance, feedback, and trends in learning behaviors. Insights derived from this data help educators design more effective curricula and address individual learning needs.
4. Real-World Success Story: Domino’s Big Data Integration
Domino’s implemented a robust data extraction strategy to consolidate data from various sources like online orders, customer feedback, and delivery logs. This integration enabled the company to optimize delivery routes, predict customer preferences, and enhance overall service efficiency.
Data Extraction and Its Role in Business Intelligence
Data extraction is a foundational element of business intelligence (BI), supporting the collection of raw data for analysis and decision-making. By extracting data from diverse sources—such as databases, cloud platforms, and third-party APIs—businesses can consolidate information into data warehouses for streamlined access and reporting.
This process enables analytics tools to process clean and organized data, uncovering actionable insights that drive strategic decisions. For example, retail businesses can analyze sales trends to optimize inventory, while financial institutions can identify fraud patterns to enhance security. The role of data extraction extends to predictive analytics, enabling organizations to forecast market trends and customer behaviors.
By facilitating seamless data flow into BI systems, data extraction empowers organizations to harness the full potential of their data. It ensures that businesses remain agile and competitive in an increasingly data-driven landscape.
The Future of Data Extraction
The future of data extraction lies in its integration with advanced technologies like cloud computing and the Internet of Things (IoT). As businesses increasingly adopt cloud platforms, the demand for scalable and efficient data extraction tools will continue to grow. IoT devices generate vast amounts of data in real-time, necessitating robust extraction methods to handle this influx effectively.
However, challenges like data privacy and security remain critical. Organizations must implement strict compliance measures and encryption technologies to protect sensitive information during extraction.
Emerging trends such as AI-driven data extraction are set to revolutionize the field. AI tools can automate the identification and extraction of relevant data with minimal human intervention, enhancing speed and accuracy. As technology evolves, data extraction will play an even more integral role in enabling seamless data integration, driving innovation, and addressing the complexities of modern data ecosystems.
Conclusion
Data extraction serves as a cornerstone of modern data management, enabling businesses to harness valuable information from diverse sources. This article has explored its integration with ETL workflows, standalone applications, and types such as full, incremental, and API-based extraction. Tools like Talend and Fivetran highlight its efficiency, while real-world use cases demonstrate its transformative impact across industries like e-commerce, healthcare, and education.
As businesses continue to rely on data-driven insights, the role of data extraction in ensuring accuracy and scalability remains paramount. By adopting advanced tools and staying ahead of emerging trends, organizations can unlock the full potential of their data ecosystems.
References:
- What is Data Extraction? Definition and Examples | Talend
- What is Data Extraction? Data Extraction Tools & Techniques | Stitch


