Did you know that poor data quality can cost businesses millions of dollars each year? In fact, companies that don’t prioritize data cleaning often face the consequences of inaccurate insights, wasted resources, and poor decision-making. Data cleaning is a crucial part of the data science process, ensuring that the data you work with is reliable, consistent, and ready for analysis.
This guide will walk you through the essential steps, tools, and benefits of data cleaning in data science, helping you ensure that your data is accurate, complete, and ready for use in your next project.
What is Data Cleaning in Data Science?
Data cleaning refers to the process of detecting and correcting (or removing) corrupt or inaccurate records from a dataset. This step is crucial in preparing raw data for analysis, ensuring it is free of errors, inconsistencies, and missing values that could negatively impact the outcomes of your data models.
The data cleaning process includes tasks such as removing duplicates, fixing structural errors, handling missing data, and filtering outliers. It is a fundamental part of any data science project and ensures the accuracy and reliability of the insights generated.
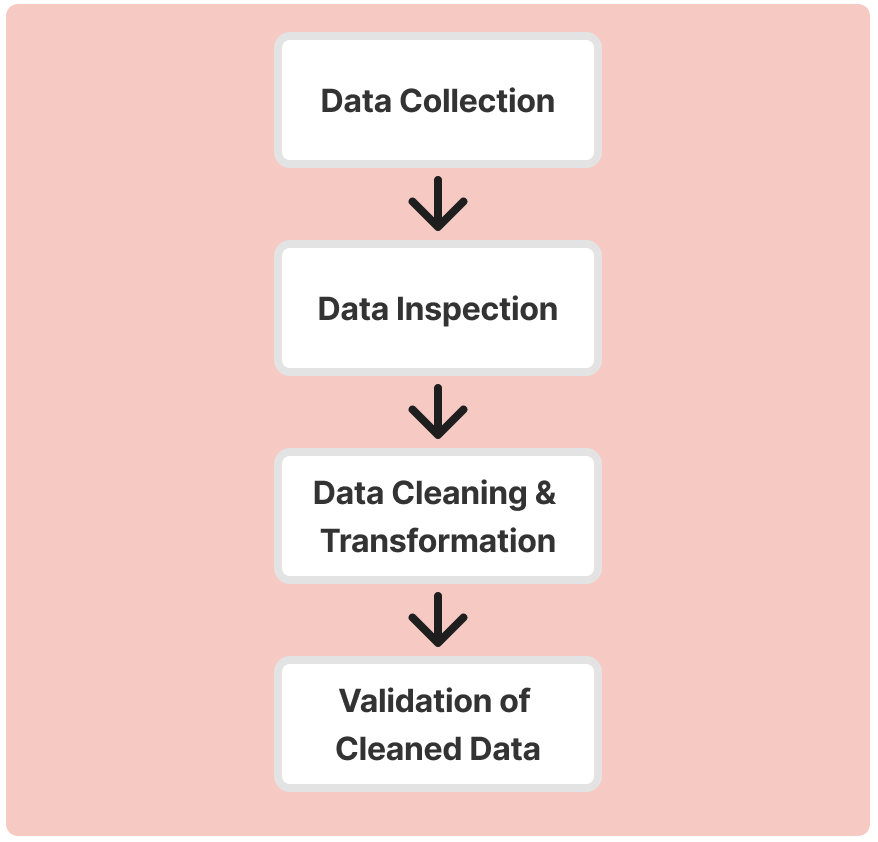
This systematic approach ensures that the data is ready for more advanced analysis or machine learning applications.
Why is Data Cleaning So Important?
Data cleaning is one of the most critical steps in the data science process. Poor-quality data can lead to inaccurate predictions, biased models, and flawed decision-making, which can have costly consequences for businesses. Here’s why data cleaning is essential:
1. Improved Decision-Making
Clean, accurate data allows businesses to make well-informed decisions. For example, a company using clean customer data will be better equipped to predict purchasing behavior, leading to more targeted marketing strategies and improved customer retention.
2. Reduced Costs
By cleaning data, organizations can eliminate unnecessary duplicates or irrelevant data, which reduces storage and processing costs. Additionally, clean data leads to more efficient operations, saving time and resources in the long run.
3. Enhanced Model Accuracy
Machine learning models rely on high-quality data to make accurate predictions. Poor data quality, such as missing values or outliers, can skew model results. Data cleaning ensures that your models perform at their best, producing reliable and actionable insights.
4. Avoiding Biased Models
Biased data can result in models that make unfair or incorrect predictions. By cleaning and validating data, data scientists can minimize bias, ensuring that the insights generated are objective and equitable.
These examples highlight how data cleaning contributes to better decision-making, cost reduction, and more accurate models, making it an indispensable part of any data science project.
What is the Difference Between Data Cleaning and Data Transformation?
| Aspect | Data Cleaning | Data Transformation |
| Purpose | To identify and correct errors or inconsistencies in data | To convert data into a format suitable for analysis |
| Tasks Involved | Removing duplicates, handling missing values, fixing errors, filtering outliers | Normalizing, scaling, encoding variables, aggregating data, feature engineering |
| Goal | Ensures accuracy and reliability of the dataset | Prepares data for analysis or modeling |
| Focus | Correcting, cleaning, and validating existing data | Modifying or converting data to improve usability and compatibility |
| Timing in Workflow | Early stage of the data preparation process | Follows data cleaning, prepping the data for analysis/modeling |
| Output | Clean, error-free data | Data in a format compatible with analysis tools and models |
| Impact on Data | Reduces errors and enhances data quality | Enhances data structure and format for better interpretation |
| Common Tools Used | Excel, OpenRefine, Python (pandas), SQL | Python (pandas, NumPy), SQL, ETL tools, Apache Spark |
How to Clean Data: Data Cleaning Process
The data cleaning process is critical to ensuring that your dataset is free of inconsistencies and ready for analysis or modeling. Below are the essential steps, along with best practices, tools, and examples to guide the process.
1. Remove Duplicate or Irrelevant Observations
- Description: Duplicate records often arise when datasets are merged or when data is collected from multiple sources. Irrelevant data refers to records that are outside the scope of the analysis (e.g., data from the wrong time period or location).
- Best Practice: Use SQL queries (e.g., SELECT DISTINCT) or Python’s pandas library (drop_duplicates()) to identify and remove duplicates.
- Example: In an e-commerce dataset, duplicate customer entries could inflate sales figures. By removing duplicates, we ensure the sales analysis is accurate.
2. Fix Structural Errors
- Description: Structural errors include typos, inconsistent formats (e.g., mixing “USA” and “United States”), and incorrect data types. These errors make data difficult to interpret and can affect the integrity of analysis.
- Best Practice: Use regular expressions (regex) or data-cleaning tools like OpenRefine to standardize categories. For correcting data types, tools like pandas can convert formats (e.g., .astype() for ensuring consistency in numeric or categorical data).
- Example: If a column of dates has mixed formats (e.g., “MM-DD-YYYY” and “YYYY-MM-DD”), the inconsistency may prevent accurate analysis. Standardizing all date formats solves this issue.
3. Filter Out Unwanted Outliers
- Description: Outliers are data points that fall outside the expected range, potentially skewing analysis. However, not all outliers are errors—sometimes they represent valuable data.
- Best Practice: Use Z-scores (standard deviation) or Interquartile Range (IQR) methods to detect outliers. Tools like Tableau and Matplotlib (for visualization) can help identify outliers graphically.
- Example: In a housing price dataset, if most houses are priced between $100K and $500K, but there are a few at $10 million, these outliers might distort your price predictions. Outliers can either be removed or adjusted based on their relevance.
4. Handle Missing Data
- Description: Missing values can disrupt data integrity and introduce bias. There are various strategies for handling them, from removing rows with missing data to using imputation techniques.
- Best Practice: For small amounts of missing data, consider deleting rows using tools like SQL (DELETE FROM). For more substantial missing data, use imputation techniques such as filling missing values with the mean, median, mode, or using algorithms like K-Nearest Neighbors (KNN) imputation.
- Example: In a customer dataset, missing age values can be filled with the median age of the remaining customers, preserving data integrity without introducing bias.
5. Validate and Quality Assurance (QA)
- Description: After data cleaning, it’s crucial to validate the dataset to ensure it meets the required standards of quality. Quality checks involve verifying the consistency, accuracy, and completeness of the data.
- Best Practice: Perform statistical validation using descriptive statistics to spot any remaining inconsistencies. Visualize the data using tools like Tableau or Matplotlib to ensure the cleaned data behaves as expected. You can also automate validation checks with scripts in Python or SQL.
- Example: After cleaning a dataset, run a summary statistics report (e.g., mean, median, standard deviation) to validate that the distribution of the data aligns with expected values.
Enhanced Data Cleaning Tips:
- Automate the Process: Where possible, automate repetitive cleaning tasks using Python scripts or tools like Trifacta to save time and reduce errors.
- Document Your Cleaning Steps: Maintain a data cleaning log or version control using platforms like Git to track changes and facilitate collaboration.
Components of Quality Data
1. Accuracy
- Definition: Data must represent reality as closely as possible. Errors, whether through misreporting or typos, lead to inaccurate insights.
- Example: In a sales dataset, inaccurate recording of product prices could skew revenue calculations.
- Best Practice: Use cross-validation techniques to verify data against trusted external sources.
2. Completeness
- Definition: Data should contain all the necessary fields for analysis. Missing data may result in incomplete or biased results.
- Example: If customer demographics are incomplete, a marketing campaign may fail to reach the target audience.
- Best Practice: Regularly audit datasets to identify and address gaps in data collection.
3. Consistency
- Definition: Data should be consistent across all records and datasets. Inconsistencies arise from mismatched data types, formats, or entry standards.
- Example: A customer may be listed with different formats of their name (“John Smith” vs. “J. Smith”), leading to duplication in analysis.
- Best Practice: Enforce standardized formats during data entry and cleaning processes.
4. Validity
- Definition: Data should adhere to defined rules or constraints. Invalid data, such as a negative age value, can distort analysis results.
- Example: A dataset containing age values that exceed a reasonable human lifespan indicates an issue.
- Best Practice: Implement validation rules during data entry, such as restricting age to a range of 0-120.
5. Uniformity
- Definition: Uniformity refers to ensuring that data is recorded in the same unit or format throughout the dataset.
- Example: A dataset containing both kilometers and miles for distance traveled would lead to discrepancies in analysis.
- Best Practice: Use consistent units (e.g., convert all distance data to kilometers) to ensure uniformity.
6. Timeliness
- Definition: Data must be up-to-date and relevant to the period being analyzed. Outdated data can lead to irrelevant or misleading insights.
- Example: Sales data from several years ago may not reflect current trends or customer preferences.
- Best Practice: Regularly update datasets and ensure that only recent data is used for real-time decision-making.
7. Relevance
- Definition: Data must be relevant to the specific question or analysis being performed. Irrelevant data adds noise and may distract from key insights.
- Example: Including irrelevant columns (such as geographic data for a local-only analysis) complicates the process without adding value.
- Best Practice: Filter out data that is not directly useful to the analysis at hand.
These components of quality data are essential to ensure that your analysis and models are based on accurate, complete, and reliable information.
Data Cleaning Tools
There are various tools available for data cleaning, each offering specific features suited to different tasks and types of data. Below are some of the most commonly used tools in data science for cleaning data:
| Tool | Key Features | Best Use Case |
| Excel | Easy-to-use interface, built-in functions for removing duplicates, filtering, and cleaning data manually. | Ideal for small datasets or quick, simple cleaning tasks. |
| Python (pandas) | Powerful libraries like pandas for handling missing values, removing duplicates, and transforming data programmatically. | Best for large datasets and automated data cleaning processes. |
| SQL | SQL queries like DELETE, UPDATE, and JOIN to filter, clean, and manipulate large datasets stored in relational databases. | Effective for cleaning data directly in databases or large data warehouses. |
| Tableau | Data visualization capabilities that help identify and correct errors through visual inspection. | Useful for visual data exploration and detecting outliers or anomalies. |
| OpenRefine | Open-source tool designed for cleaning messy data, with features for transforming, parsing, and removing duplicates. | Great for non-technical users or when dealing with messy, unstructured data. |
| Trifacta | Advanced data wrangling platform with automation features, built-in transformations, and machine learning assistance for cleaning data. | Best for large-scale data cleaning, especially in enterprise settings. |
Advantages and Benefits of Data Cleaning
Data cleaning is not just a preparatory step in data science; it offers significant advantages that can improve overall business performance and lead to more accurate insights. Below are some key benefits of maintaining clean and well-processed data:
1. Improved Decision-Making
- Benefit: Clean data ensures that decisions are based on accurate, reliable information. By eliminating errors and inconsistencies, businesses can trust their data when making strategic decisions.
- Example: A retail company that cleans and organizes its sales data can more accurately predict future trends, resulting in better inventory management and marketing strategies.
2. Increased Efficiency
- Benefit: Data cleaning streamlines workflows by removing irrelevant or duplicate information, reducing the amount of data that needs to be processed. This leads to faster analysis and more efficient data handling.
- Example: A financial institution that regularly cleans its transaction data can reduce processing times for fraud detection systems, leading to quicker responses.
3. Enhanced Model Accuracy
- Benefit: Machine learning models rely on high-quality data to generate accurate predictions. Clean data improves model performance by minimizing noise, outliers, and missing values, resulting in more reliable insights.
- Example: A healthcare organization can improve the accuracy of a predictive model for patient readmissions by ensuring that all patient records are clean and complete.
4. Cost Savings
- Benefit: Clean data reduces operational costs by preventing inefficiencies caused by inaccurate data, such as poor marketing campaigns, inventory mismanagement, or system failures. Companies can also save on storage costs by removing unnecessary or redundant data.
- Example: A company might save thousands of dollars by cleaning and streamlining its customer data, resulting in better-targeted marketing campaigns and reduced wastage.
5. Compliance and Risk Management
- Benefit: Many industries are subject to strict data regulations (e.g., GDPR, HIPAA). Clean data ensures that organizations are compliant with these regulations and reduces the risk of penalties or breaches.
- Example: A financial firm that maintains clean and accurate customer records is better prepared for regulatory audits and can avoid costly fines.
6. Better Customer Insights
- Benefit: Clean data helps businesses better understand customer behavior by providing accurate insights. This leads to improved customer satisfaction and personalized marketing strategies.
- Example: An e-commerce company can use clean customer data to tailor recommendations more effectively, increasing customer engagement and sales.
7. Data Integration
- Benefit: Clean data is easier to integrate from multiple sources, leading to more comprehensive analyses. This is especially useful in large organizations that use data from various departments.
- Example: A company that consolidates clean data from sales, marketing, and customer service departments can gain a more holistic view of business performance.
By prioritizing data cleaning, businesses can improve decision-making, reduce costs, and enhance the performance of machine learning models. Clean data is critical for deriving accurate insights and driving successful outcomes in any data-driven initiative.
Conclusion
In the world of data science, data cleaning is an essential step that ensures the accuracy, reliability, and relevance of your dataset. Clean data leads to better decision-making, more efficient workflows, and improved model performance. By addressing common issues like duplicates, missing values, and outliers, data cleaning provides a solid foundation for any analysis or machine learning project.
As data continues to grow in volume and complexity, the importance of maintaining high-quality data cannot be overstated. Investing time and resources into effective data cleaning practices will not only save costs but also unlock valuable insights that drive business success.
Whether you’re working with small datasets in Excel or large-scale enterprise data in Python or SQL, using the right tools and following best practices will ensure that your data is ready for analysis, providing a competitive edge in a data-driven world.


