Cross-validation is a critical technique in machine learning that helps assess the performance of models. It ensures models are not overfitted or underfitted by evaluating how well they generalize to unseen data. This guide explores various types of cross-validation, their applications, and how they enhance model reliability in real-world scenarios.
What is Cross-Validation?
Cross-validation is a resampling technique used to evaluate machine learning models on a limited data sample. Its primary goal is to assess how well a model generalizes to unseen data. In cross-validation, the data is split into multiple subsets, known as folds. The model is trained on a portion of the data and tested on the remaining portion, ensuring that each data point is used for both training and testing at least once.
By systematically rotating the training and test data, cross-validation helps in understanding how well the model performs on different subsets of the dataset. This is crucial because a model that performs well on training data might not perform as effectively on new, unseen data due to overfitting.
Cross-validation addresses this by providing multiple opportunities to validate the model’s performance across various subsets of the data, making it more reliable than a single train-test split.
In summary, cross-validation helps ensure that models are robust and capable of generalizing well, making it an indispensable tool for machine learning practitioners.
What is Cross-Validation Used For?
Cross-validation is primarily used to prevent overfitting, which occurs when a model learns the noise and details in the training data to the extent that it negatively impacts its performance on new data. By using cross-validation, we can get a more accurate estimate of a model’s true performance.
Key Use Cases:
- Preventing Overfitting: Cross-validation helps prevent models from being too closely aligned to the training data by testing them on various subsets.
- Evaluating Model Performance: Metrics such as accuracy, precision, recall, and F1 score are calculated using cross-validation to provide a reliable estimate of model performance.
- Model Selection: When selecting between different algorithms, cross-validation can help identify the one that performs best on the data.
- Hyperparameter Tuning: Cross-validation is integral to techniques like grid search or random search, which test different hyperparameter combinations to optimize the model’s performance.
Types of Cross-Validation
There are several types of cross-validation, each suited to different types of data and model requirements. Here are the most common ones:
1. Holdout Validation
Holdout Validation involves splitting the dataset into two parts: training and testing. The model is trained on one part and tested on the other. This method is simple but less reliable because the model’s performance can vary based on how the data is split.
- When to use: Holdout validation is useful when you have a large dataset and want a quick estimate of model performance.
2. LOOCV (Leave-One-Out Cross Validation)
LOOCV is a special case of k-fold cross-validation where k equals the number of data points in the dataset. For each iteration, one data point is left out for testing, and the model is trained on the rest.
- Computational Implications: LOOCV can be computationally expensive for large datasets since it requires training the model multiple times.
- Use Cases: It is ideal when you have a small dataset and want to maximize the use of all data points for training.
3. Stratified Cross-Validation
Stratified Cross-Validation is a variation of k-fold where the data is split in such a way that each fold has the same proportion of class labels. This is particularly useful for imbalanced datasets, where one class might be underrepresented.
- Common Use Cases: Stratified cross-validation is used in classification problems where the target variable has skewed distribution (e.g., fraud detection).
4. K-Fold Cross-Validation
K-fold cross-validation is one of the most popular techniques. It splits the data into k equal-sized folds. The model is trained on k-1 folds and tested on the remaining fold. This process is repeated k times, with each fold being used as the test set exactly once.
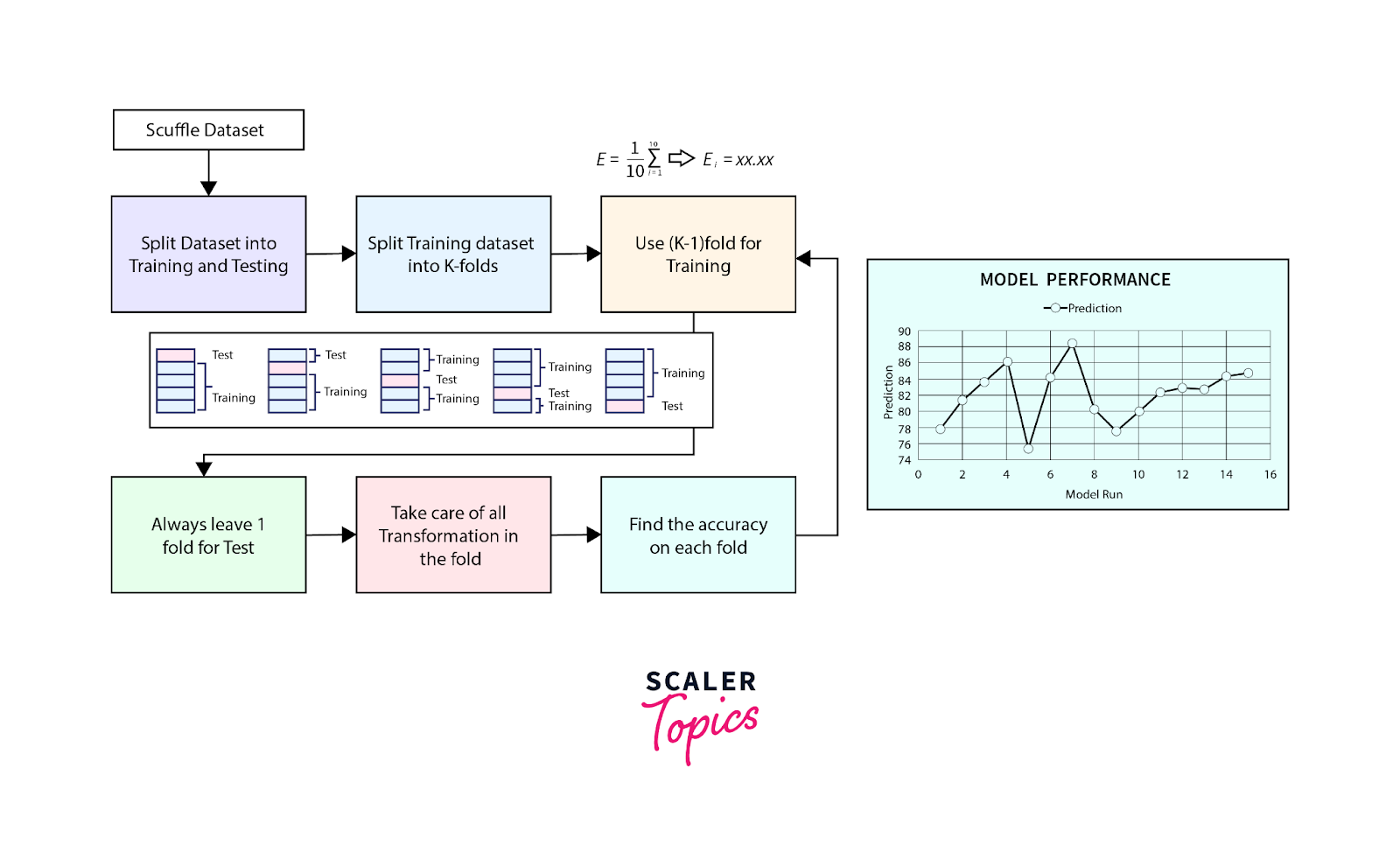
Source: Scaler Topics
- Pros: K-fold cross-validation provides a more accurate measure of model performance than a simple train/test split.
- Cons: It can be computationally expensive, especially for large datasets.
Example of K-Fold Cross-Validation
Let’s assume you have a dataset with 1000 data points, and you choose k=5. The data is split into 5 folds, with each fold containing 200 data points. In the first iteration, the model is trained on 800 data points and tested on the remaining 200. This process repeats until each fold has been used for testing.
K-fold cross-validation provides a more robust estimate of model performance by ensuring that the model is tested on different subsets of data.
Comparison between Cross-Validation and Holdout Method
The holdout method and cross-validation differ primarily in how they split and evaluate the data.
- Holdout Method: This method involves splitting the dataset into two parts (typically 80% training and 20% testing) and training the model on one part while testing it on the other. It’s simple and computationally efficient but prone to bias, as the performance can vary depending on the split.
- Cross-Validation: Cross-validation, specifically k-fold, provides a more reliable estimate by ensuring that every data point is used for both training and testing. It splits the data into multiple folds and tests the model on each fold, leading to less bias and variance in performance evaluation.
Advantages of Holdout Method:
- Computationally fast, especially for large datasets.
- Suitable for quick estimates of model performance.
Advantages of Cross-Validation:
- Provides a more accurate and generalized evaluation.
- Reduces the risk of overfitting by ensuring the model is tested on different subsets of data.
For large datasets, the holdout method may suffice, but for smaller datasets or when more accuracy is needed, cross-validation is the better choice.
Advantages and Disadvantages of Cross-Validation
Advantages:
- Improves Model Performance: Cross-validation helps to create models that generalize better to new, unseen data. By training and testing on different subsets, the model is less likely to overfit.
- Reduces Bias: Cross-validation reduces bias in the model evaluation process. It gives the model an opportunity to perform on various subsets, which provides a more reliable estimate of its real-world performance.
- Helps in Hyperparameter Tuning: Cross-validation is integral in hyperparameter tuning, particularly in methods like grid search and random search. These techniques test different hyperparameter combinations across folds, helping to find the optimal model settings.
Disadvantages:
- Computational Expense: For large datasets, cross-validation, especially techniques like LOOCV, can be computationally expensive as the model is trained multiple times. This can lead to longer training times and higher resource consumption.
- May Not Always Improve Performance: While cross-validation can reduce overfitting, it does not always guarantee better performance, particularly if the model is inherently flawed or if the data quality is poor.
Despite these challenges, cross-validation remains one of the most effective methods for evaluating and improving machine learning models.
Applications of Cross-Validation
Cross-validation has wide applications in machine learning projects, primarily focusing on model evaluation, selection, and hyperparameter tuning. Some key applications include:
- Model Selection: When choosing between different machine learning algorithms (e.g., decision trees, support vector machines, or neural networks), cross-validation helps identify which model performs best on the data.
- Hyperparameter Tuning: Cross-validation is integral to hyperparameter tuning methods like grid search and random search. These methods explore different hyperparameter combinations and evaluate their performance using cross-validation to find the optimal settings.
- Ensemble Methods: Techniques such as bagging and boosting rely on cross-validation to ensure that multiple models are trained and evaluated correctly before combining their outputs for a final prediction.
Cross-validation is critical in the machine learning pipeline to ensure models are reliable and optimized for real-world applications.
Python Implementation for K-Fold Cross-Validation
Here’s an example of how to implement K-Fold Cross-Validation in Python using the scikit-learn library:
Step-by-Step Python Implementation
# Step 1: Import necessary libraries
from sklearn.model_selection import KFold
from sklearn.datasets import load_iris
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# Step 2: Load the dataset
iris = load_iris()
X, y = iris.data, iris.target
# Step 3: Create a classifier (Support Vector Machine)
clf = SVC(kernel='linear')
# Step 4: Define the number of folds for cross-validation
kf = KFold(n_splits=5)
# Step 5: Perform K-Fold Cross-Validation
accuracies = []
for train_index, test_index in kf.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
# Train the model
clf.fit(X_train, y_train)
# Predict and evaluate
y_pred = clf.predict(X_test)
accuracies.append(accuracy_score(y_test, y_pred))
# Step 6: Evaluate model performance
print(f"Cross-Validated Accuracy: {sum(accuracies) / len(accuracies) * 100:.2f}%")Explanation:
In this example, we use the Iris dataset and a Support Vector Machine (SVM) classifier. The data is split into 5 folds using KFold, and the classifier is trained and tested on each fold. The accuracy of the model is then averaged across all the folds to give a reliable estimate of its performance.
Conclusion
Cross-validation is an essential technique for evaluating machine learning models, ensuring they generalize well to unseen data. By splitting the data into multiple subsets and rotating the training and testing process, cross-validation helps prevent overfitting and provides more reliable performance metrics. As machine learning models become more complex, cross-validation plays a critical role in hyperparameter tuning and model selection, ensuring that models are both accurate and robust. Applying cross-validation in your machine learning projects will lead to better model performance and more dependable outcomes.
References: