Convolutional Neural Networks (CNNs) are a type of deep learning model commonly used in image recognition tasks. Unlike traditional neural networks, CNNs are designed to automatically detect patterns from images, making them highly efficient in visual data processing. Deep learning, a subset of machine learning, enables machines to mimic the way humans learn from experience, and CNNs play a key role in this by identifying objects, faces, and scenes within images.
CNNs have revolutionized computer vision tasks like facial recognition, object detection, and even medical image analysis, significantly outperforming traditional methods. Their ability to process image data efficiently has made them an essential tool in fields ranging from healthcare to autonomous vehicles.
What is a Convolutional Neural Network (CNN)?
A Convolutional Neural Network (CNN) is a type of deep learning model specifically designed for processing structured grid data, such as images. The core idea of CNNs is to automatically detect and learn important features in an image, like edges, colors, and textures, through a series of layers. Instead of manually defining these features, CNNs use a mathematical operation called convolution to scan through the image and capture essential details, which makes them highly effective for image classification and recognition tasks.
One of the key strengths of CNNs is their ability to learn hierarchical representations of images. This means that early layers in a CNN may detect simple patterns like lines and edges, while deeper layers combine these patterns to identify more complex shapes, objects, or even entire scenes.
CNNs are widely used in various fields, not only for image processing but also for tasks like video analysis, natural language processing, and even game development, where understanding and interpreting large amounts of visual data is crucial.
Inspiration Behind CNN and Parallels with the Human Visual System
Convolutional Neural Networks (CNNs) are inspired by the human brain’s visual processing capabilities. The human visual system interprets images by breaking them down into smaller components, which is what CNNs are designed to mimic. Let’s break down the parallels between the two:
Local Receptive Fields:
Just like how neurons in the human brain focus on small portions of the visual field, each neuron in a CNN looks at a specific region of the image, known as the receptive field. This localized approach allows CNNs to detect fundamental patterns such as edges, lines, or textures, which are the building blocks of any image.
Shared Weights (Weight Sharing):
CNNs use the same filters (or weights) across different parts of an image. This concept is similar to how neurons in the visual cortex apply the same processing function across multiple areas of the visual field. This weight-sharing technique allows CNNs to efficiently recognize the same pattern, such as a vertical line or curve, no matter where it appears in the image. This reduces the number of parameters and ensures faster training.
Hierarchical Feature Learning:
CNNs learn features in a hierarchical manner, where the first layers detect simple patterns (like edges or corners), and deeper layers combine these simple features to recognize more complex structures (like shapes and objects). This mirrors how the human brain processes visual data, starting from basic elements and progressively understanding more complex objects. For instance, early layers in the brain detect colors and edges, while higher-level processing areas recognize faces or entire scenes.
Spatial Awareness:
CNNs also maintain spatial relationships in images, meaning the position of objects relative to one another is preserved through the layers. This is essential for tasks like object detection or segmentation, where understanding the spatial layout is critical—just like how the brain identifies not just the objects we see but their relative positions.
By replicating these biological principles, CNNs can efficiently process and interpret visual data, making them the foundation for many applications such as image recognition, medical diagnostics, and autonomous driving.
Key Components of a Convolutional Neural Network Include
Convolutional Neural Networks (CNNs) consist of several key components that work together to process and analyze visual data. Each component plays a specific role in extracting features and making predictions. Let’s take a closer look at these core components:
1. Convolutional Layers:
These layers apply filters (also called kernels) to the input image, scanning it and extracting important features like edges, textures, or patterns. The filter moves across the image using a process called convolution, producing feature maps that highlight important aspects of the input data. Two important concepts here are:
- Stride: This defines how much the filter moves across the image. A larger stride results in smaller feature maps.
- Padding: Sometimes, extra pixels are added around the edges of the image to allow the filter to capture features at the boundaries. This helps maintain the size of the output feature map.
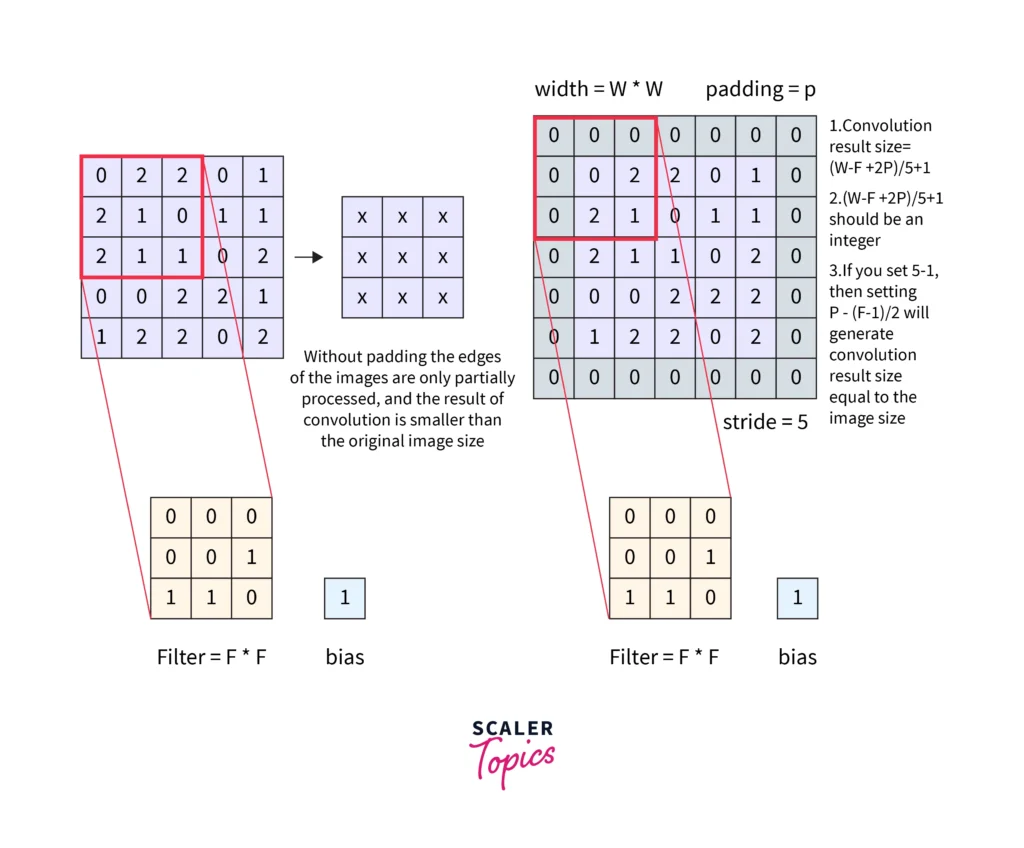
2. Pooling Layers:
Pooling layers reduce the size of the feature maps, making the network more computationally efficient while retaining important information. Pooling combines adjacent pixels into a single value, reducing the overall number of parameters. Two common types of pooling are:
- Max Pooling: Takes the maximum value from a group of neighboring pixels, helping to retain the most important features.
- Average Pooling: Takes the average value from the group of pixels, providing a more generalized summary of the area.
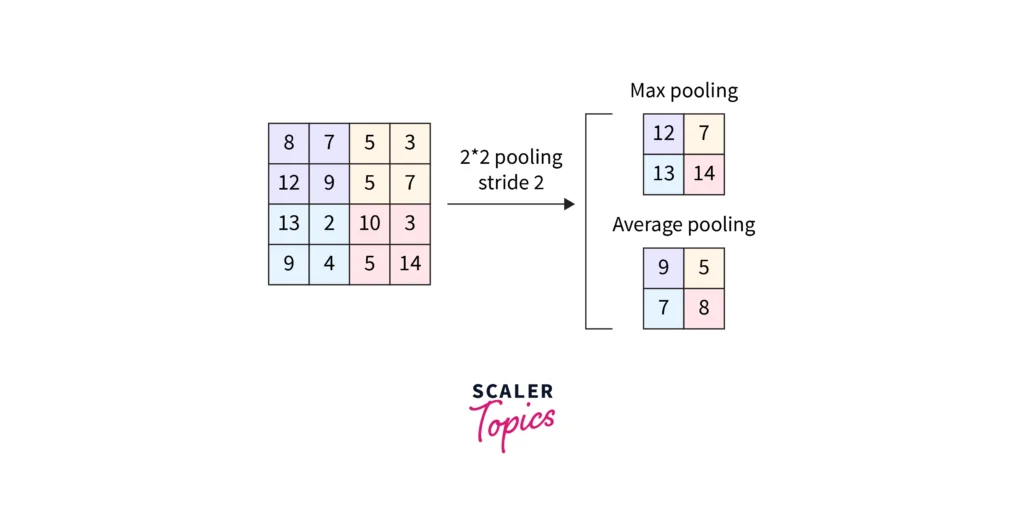
3. Activation Functions:
Activation functions introduce non-linearity into the network, allowing it to learn complex patterns. Without non-linearity, the network would only be able to learn linear relationships, limiting its effectiveness. The most commonly used activation function in CNNs is:
- ReLU (Rectified Linear Unit): ReLU replaces negative values in the feature maps with zero, keeping only positive values. This speeds up training and improves performance by preventing negative activations from propagating through the network.
4. Fully Connected Layers:
After feature extraction is complete, the fully connected layers take over. These layers are similar to those in traditional neural networks and are responsible for classifying the input image based on the features learned by the convolutional and pooling layers. The final output could be a probability distribution over different categories (in the case of classification tasks) or a numerical value (for regression tasks).
These core components work together to transform raw image data into meaningful outputs, enabling CNNs to perform tasks like image recognition, object detection, and more.
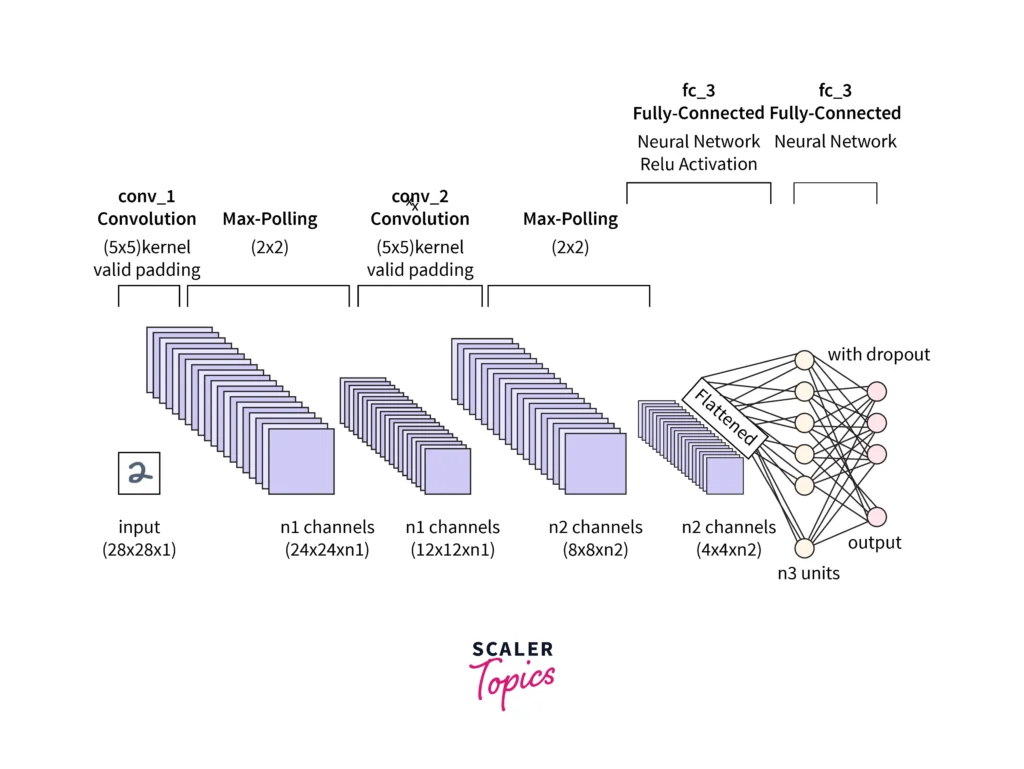
Convolutional Neural Network Design
The design of a Convolutional Neural Network (CNN) involves configuring its architecture and selecting the appropriate parameters to solve specific tasks like image classification or object detection. Several factors go into designing a CNN, including the choice of layers, network depth, and hyperparameters. Here are the key elements to consider:
1. Network Architecture:
CNNs come in various architectures, each designed for different purposes. Some popular architectures include:
- LeNet: One of the earliest CNN architectures, LeNet was designed for digit recognition tasks.
- AlexNet: Introduced in 2012, AlexNet marked a breakthrough in image classification and led to significant improvements in the accuracy of CNNs.
- VGG: VGG is known for its simplicity, using small convolutional filters throughout the network while achieving high accuracy in image recognition tasks.
- ResNet: ResNet introduced the concept of residual learning, allowing very deep networks by solving the problem of vanishing gradients.
- MobileNet: MobileNet is designed for efficiency and speed, making it ideal for mobile and embedded applications.
2. Hyperparameters:
Hyperparameters control the behavior of the CNN and need to be fine-tuned to improve the model’s performance. Important hyperparameters include:
- Filter Size: Refers to the size of the kernel used in convolutional layers. Typical sizes are 3×3 or 5×5.
- Stride: Controls how much the filter moves across the input image.
- Number of Filters: Determines how many filters are used in each convolutional layer. More filters allow the network to learn more features.
- Learning Rate: This controls how much the model’s parameters are updated during training. A well-chosen learning rate can significantly impact the performance and speed of the network.
3. Depth of the Network:
The depth refers to the number of layers in a CNN. Deeper networks can learn more complex representations, but they also require more data and computational power. Shallow networks might not capture enough features, while very deep networks can run into problems like vanishing gradients, where the gradients become too small to update the weights effectively. Techniques like residual connections in ResNet help address this issue.
Designing an effective CNN architecture requires balancing accuracy with efficiency. The choice of architecture and hyperparameters can significantly impact both the performance of the model and its ability to generalize to new data.
Convolutional Neural Network Training
Training a Convolutional Neural Network (CNN) involves adjusting its parameters so that it can accurately classify or predict based on the input data. The training process is iterative, where the network learns from the data and improves over time. Here are the key steps involved in training a CNN:
1. Data Preparation:
Before training, the data must be preprocessed to ensure the model performs well. This includes:
- Image Normalization: Scaling the pixel values to a common range (typically 0 to 1) so the network can learn efficiently.
- Data Augmentation: Techniques like flipping, rotating, or cropping images are used to artificially expand the dataset and help the model generalize better by learning from various perspectives.
2. Loss Function:
The loss function measures the difference between the predicted output and the actual label. CNNs aim to minimize this loss to improve their accuracy. Common loss functions used in CNNs are:
- Cross-Entropy Loss: Often used for classification tasks, this loss function calculates the difference between the predicted class probabilities and the actual class labels.
- Mean Squared Error (MSE): Used for regression tasks, MSE calculates the average squared difference between the predicted values and the true values.
3. Optimizer:
The optimizer adjusts the network’s weights based on the gradients calculated during training. Popular optimizers for CNNs include:
- Stochastic Gradient Descent (SGD): Updates the weights based on the gradient of the loss function for each data point.
- Adam: A more advanced optimizer that adapts the learning rate during training, leading to faster convergence and better performance.
4. Backpropagation:
Backpropagation is a key step in training CNNs. It calculates the gradients of the loss function with respect to the weights of the network. These gradients are used to update the weights and minimize the loss function. Backpropagation is performed after each forward pass, where the input data moves through the network layers, and the output is generated.
The training process is repeated over multiple epochs, where the model sees the entire training dataset multiple times. With each epoch, the CNN improves its ability to recognize patterns and make more accurate predictions. After training, the network’s performance is evaluated on a separate set of data (validation or test set) to ensure it generalizes well to unseen data.
CNN Evaluation
After training a Convolutional Neural Network (CNN), evaluating its performance is crucial to ensure it generalizes well to new, unseen data. There are several methods and metrics used to assess how well the model performs:
1. Accuracy:
This metric measures the percentage of correct predictions made by the CNN. It’s widely used for classification tasks, but it can be misleading if the dataset is imbalanced (i.e., one class dominates the dataset).
2. Precision and Recall:
These metrics are especially important when dealing with imbalanced datasets.
- Precision: The ratio of true positive predictions to the total number of positive predictions. High precision means the model is good at avoiding false positives.
- Recall: The ratio of true positive predictions to the actual positives in the dataset. High recall indicates the model is good at identifying all positive cases, minimizing false negatives.
3. F1 Score:
The F1 score is the harmonic mean of precision and recall, offering a balanced measure when both precision and recall are important. It is especially useful when dealing with imbalanced classes.
4. Confusion Matrix:
This is a table that shows the true positives, true negatives, false positives, and false negatives. It provides a more detailed view of how well the model is performing for each class and can highlight if the CNN is struggling with certain classes.
5. Validation and Test Sets:
To evaluate the model’s performance properly, it’s essential to use a separate validation set during training. This helps prevent overfitting, where the model becomes too specialized in the training data and performs poorly on new data. After training, the model is evaluated on a test set, which is entirely unseen by the model during training, to get a final assessment of its performance.
6. Overfitting Prevention:
Overfitting occurs when the model learns the training data too well, including noise or irrelevant patterns. To prevent overfitting, techniques like early stopping (stopping training when performance on the validation set starts to decline) and dropout (randomly dropping neurons during training to avoid over-reliance on certain features) are used.
Evaluating a CNN thoroughly with these metrics helps ensure it’s not only accurate but also generalizes well, making reliable predictions in real-world applications.
Different Types of CNN Models
Over the years, several CNN architectures have been developed to address various challenges in computer vision tasks. Each model has unique characteristics that make it suitable for specific applications. Here are some of the most popular CNN models:
1. LeNet (1998):
LeNet is one of the first CNN models, designed for handwritten digit recognition tasks such as reading zip codes. Although simple by today’s standards, it introduced key concepts like convolutional layers and pooling, which form the basis of modern CNN architectures.
2. AlexNet (2012):
AlexNet was a major breakthrough in deep learning and CNNs. It won the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) in 2012 and significantly improved image classification accuracy. AlexNet introduced the use of ReLU activation and dropout to prevent overfitting, and it demonstrated that deeper CNNs could handle large datasets effectively.
3. VGG (2014):
VGG is known for its simplicity and depth. It uses small (3×3) convolutional filters stacked one after another to extract more detailed features. VGG achieved high performance in image recognition tasks, but its main drawback is that it requires a lot of computational resources due to its large number of parameters.
4. ResNet (2015):
ResNet introduced the concept of residual learning, which allowed the creation of extremely deep networks (up to hundreds of layers) without suffering from vanishing gradients. By using skip connections, ResNet solved the problem of degrading accuracy in very deep networks, making it a standard in many vision tasks.
5. GoogleNet/Inception (2014):
GoogleNet, also known as Inception, introduced a novel concept called the Inception Module, which applies filters of different sizes to the same input simultaneously. This allowed the network to capture multi-scale features while keeping computational costs low. GoogleNet won the ILSVRC in 2014.
6. MobileNet (2017):
MobileNet is designed for efficient performance on mobile and embedded devices. It uses depthwise separable convolutions, which significantly reduce the number of parameters while maintaining accuracy. MobileNet is widely used in real-time applications like mobile vision tasks and augmented reality.
These models have paved the way for advancements in image recognition, object detection, and other visual tasks. The choice of CNN architecture depends on factors like the size of the dataset, available computational resources, and the complexity of the problem.
Overfitting and Regularization in CNNs
Overfitting is a common challenge in Convolutional Neural Networks (CNNs), where the model becomes too specialized in the training data and fails to generalize well to new, unseen data. When a CNN overfits, it performs very well on the training set but poorly on the validation or test set. Regularization techniques are used to prevent this from happening and improve the model’s ability to generalize.
Here are some common techniques to combat overfitting in CNNs:
1. Dropout:
Dropout is a popular regularization technique that randomly “drops” (disables) a set percentage of neurons during each training iteration. By doing so, the network is forced to rely on different subsets of neurons, preventing it from becoming overly dependent on any single feature. This helps the model generalize better by learning more robust features.
2. Data Augmentation:
Data augmentation artificially expands the training dataset by applying random transformations to the images, such as flipping, rotating, or cropping. This increases the diversity of the training data and helps the CNN learn to recognize objects in various conditions, reducing overfitting. It ensures that the model is not memorizing the specific training images but learning more generalized features.
3. Early Stopping:
Early stopping involves monitoring the model’s performance on the validation set during training. If the validation performance stops improving or starts worsening while the training performance continues to improve, training is stopped. This prevents the model from learning noise or irrelevant patterns in the training data.
4. L2 Regularization (Weight Decay):
L2 regularization adds a penalty to large weight values in the loss function, encouraging the model to maintain smaller weights. This prevents the model from becoming too complex and reduces its ability to memorize the training data.
By applying these regularization techniques, CNNs can generalize better and achieve higher accuracy on unseen data, ensuring reliable performance in real-world applications.
Deep Learning Frameworks for CNNs
Several deep learning frameworks have been developed to simplify the process of building and training Convolutional Neural Networks (CNNs). These frameworks provide pre-built functions and tools that allow developers to design, train, and deploy models with ease. Here are some of the most popular deep learning frameworks used for CNN development:
1. TensorFlow:
Developed by Google, TensorFlow is one of the most widely-used deep learning frameworks. It provides flexibility and scalability, making it suitable for both research and production environments. TensorFlow offers extensive support for CNNs and includes features for data preprocessing, model building, and deployment. It also has a high-level API called Keras, which simplifies model building with CNNs.
2. Keras:
Keras is a user-friendly, high-level API built on top of TensorFlow. It allows for quick prototyping and easy implementation of CNN models with minimal code. Keras is especially popular among beginners due to its simplicity, while still being powerful enough for advanced tasks.
3. PyTorch:
PyTorch, developed by Facebook’s AI Research lab, is another popular framework for building CNNs. PyTorch is known for its dynamic computational graph, which makes it easier to debug and experiment with different network architectures. PyTorch is highly favored by researchers and is also gaining popularity in industry applications.
4. MXNet:
MXNet is a scalable deep learning framework that’s used for a wide variety of applications. It is particularly suited for training CNNs on large datasets across multiple GPUs, making it a good choice for large-scale projects. MXNet also supports deployment on cloud platforms, making it ideal for enterprise solutions.
5. Caffe:
Caffe is an older but still widely-used framework specifically designed for fast training of deep learning models, particularly CNNs. It is optimized for speed and often used in research settings or applications where speed is critical. However, it lacks some of the flexibility offered by TensorFlow or PyTorch.
Each of these frameworks provides powerful tools for building CNN models, and the choice of framework often depends on the specific requirements of the project, such as ease of use, scalability, or support for advanced features.
Practical Applications of CNNs
Convolutional Neural Networks (CNNs) have revolutionized many fields by enabling machines to process and understand visual data. Their ability to automatically extract and learn features from images makes them highly valuable in various real-world applications. Here are some of the key areas where CNNs are commonly used:
1. Image Recognition:
CNNs are widely used in image recognition tasks, where they identify objects or patterns within images. Applications include:
- Facial Recognition: Used in security systems and smartphones to identify individuals.
- Object Detection: Employed in autonomous vehicles, drones, and robotics to detect objects in the environment.
2. Medical Imaging:
In healthcare, CNNs are used to analyze medical images such as X-rays, MRIs, and CT scans to detect abnormalities. Some examples include:
- Cancer Detection: CNNs can identify early signs of cancer from medical scans, improving diagnostic accuracy.
- Diabetic Retinopathy Detection: CNNs are used to detect signs of diabetic retinopathy in retinal images, helping prevent vision loss.
3. Autonomous Vehicles:
CNNs are critical for self-driving cars, where they process camera feeds in real-time to detect lanes, traffic signs, pedestrians, and other vehicles, ensuring safe navigation and decision-making.
4. Natural Language Processing (NLP):
While CNNs are primarily used for visual data, they also have applications in NLP tasks, such as sentiment analysis or text classification. CNNs can be used to detect patterns in textual data, contributing to tasks like spam detection or emotion recognition.
5. Video Analysis:
CNNs are used to analyze video frames for tasks like activity recognition, video summarization, and anomaly detection. This is applied in areas like surveillance and sports analytics.
6. Augmented and Virtual Reality (AR/VR):
CNNs power AR/VR applications by recognizing objects in the real world and overlaying virtual elements. These technologies are used in gaming, training simulations, and interactive learning environments.
CNNs continue to push the boundaries of what machines can achieve in visual recognition tasks. Their practical applications extend across many industries, improving everything from medical diagnostics to autonomous driving.
Advantages of CNNs
- Automatic Feature Extraction: CNNs automatically detect important features from images without manual intervention, simplifying the process.
- Spatial Invariance: CNNs can recognize patterns, such as shapes and edges, regardless of their position in the image.
- Parameter Efficiency: Using shared weights reduces the number of parameters, making CNNs more efficient and less prone to overfitting.
- High Accuracy: CNNs excel in visual tasks like image classification and object detection, achieving state-of-the-art accuracy.
- Reduced Computational Cost: Techniques like pooling and weight sharing help reduce computational costs while preserving important information.
- Versatility Across Domains: CNNs are adaptable and can be used in various fields, including video analysis, natural language processing, and medical imaging.
Disadvantages of CNNs
- High Computational Cost: CNNs require a lot of computational power, making them resource-intensive to train.
- Dependence on Large Datasets: CNNs need large amounts of labeled data to perform effectively, which can be a challenge in some cases.
- Vulnerability to Adversarial Attacks: Small changes to input images can lead to incorrect predictions, making CNNs vulnerable to attacks.
- Lack of Interpretability: CNNs function like “black boxes,” making it hard to explain how they reach certain conclusions.
- Overfitting Risk: CNNs can overfit if not properly regularized, leading to poor performance on new data.
Case Study of CNN for Diabetic Retinopathy
Convolutional Neural Networks (CNNs) have proven to be highly effective in healthcare, especially for analyzing medical images. One real-world application is in the detection of diabetic retinopathy, a condition that can lead to blindness if not diagnosed and treated early. CNNs are used to analyze retinal images and identify early signs of the disease by detecting features such as hemorrhages, microaneurysms, and other abnormalities.
In this case, the CNN is trained on a large dataset of labeled retinal images. During training, the network learns to identify patterns that indicate diabetic retinopathy. Once trained, the CNN can analyze new images and classify them as either healthy or showing signs of the disease, often with high accuracy.
Using CNNs for diabetic retinopathy detection has several benefits:
- Faster Diagnosis: CNNs can process large volumes of images in a fraction of the time it would take for a human doctor to examine them.
- Improved Accuracy: CNNs are capable of detecting subtle patterns that might be missed by human observers, leading to more reliable diagnoses.
- Scalability: CNNs allow medical facilities to screen more patients, especially in regions where access to specialists is limited.
This case study highlights how CNNs can assist in early detection of diseases, improving outcomes for patients and reducing the burden on healthcare professionals.
Conclusion
Convolutional Neural Networks (CNNs) have transformed the way machines interpret visual data, becoming essential in fields like image recognition, medical diagnostics, and autonomous driving. With their ability to automatically extract features and adapt to different types of data, CNNs offer significant advantages in performance and accuracy. However, they also come with challenges such as high computational cost, dependence on large datasets, and vulnerability to adversarial attacks.
Despite these limitations, the impact of CNNs in artificial intelligence and machine learning continues to grow. Ongoing research aims to address these challenges, making CNNs even more efficient and reliable for future applications.


