Clustering is a key technique in machine learning, widely used for finding patterns and grouping similar data points. It belongs to unsupervised learning, meaning that it works without labeled data or predefined categories. Instead, clustering automatically identifies natural groupings within a dataset based on certain characteristics, such as distance or similarity. This makes it especially useful for exploring data, identifying patterns, and making sense of large, complex datasets.
Whether you’re analyzing customer behavior, organizing search results, or segmenting images, clustering helps uncover hidden structures that might not be immediately obvious. By grouping similar data points together, it simplifies the process of understanding and interpreting data.
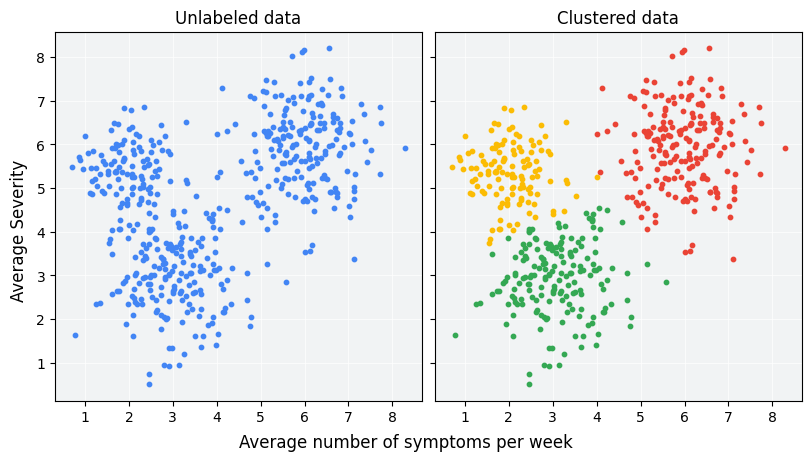
What is Clustering?
Clustering is a process in machine learning where data points are grouped based on their similarities. The main goal is to place similar items in the same group (called a cluster) while separating dissimilar items into different clusters. In simple terms, clustering helps organize data so that the points in one group are more alike than points in another group.
For example, in customer segmentation, clustering can group customers based on buying behavior or preferences. Distance metrics, like Euclidean distance, are often used to measure how similar or different data points are, helping to create these clusters.
Types of Clustering
Hard Clustering
In hard clustering, each data point belongs to only one cluster. This means that once a data point is assigned to a cluster, it cannot belong to any other cluster.
Example of Hard Clustering
Imagine you’re analyzing customers of a store. You want to group them based on their shopping habits, so you divide them into three clusters: “frequent buyers,” “occasional buyers,” and “rare buyers.” Once a customer is placed in one of these clusters, they stay there. K-means clustering is a popular method for hard clustering, where each data point (customer) is assigned to the nearest cluster based on a set of features like purchase frequency.
Soft Clustering
In soft clustering, data points can belong to multiple clusters with varying degrees of membership. Instead of assigning a point to just one cluster, the algorithm calculates how likely the point belongs to different clusters.
Example of Soft Clustering
In a similar customer analysis, soft clustering would allow a customer to belong to both “frequent buyers” and “occasional buyers,” with different degrees of membership. For instance, a customer might be 70% frequent buyer and 30% occasional buyer. Fuzzy c-means clustering is a well-known example where each point has a membership score for different clusters.
Uses of Clustering
Clustering has a wide range of applications across different fields. Here are a few examples:
- Market Segmentation: Businesses can use clustering to group customers based on similarities like demographics, purchasing behavior, or preferences. This helps in creating targeted marketing strategies.
- Social Network Analysis: Clustering can help identify communities or groups within a network, such as finding people with similar interests or interaction patterns.
- Search Result Grouping: Search engines use clustering to group similar search results, helping users find related information more easily.
- Medical Imaging: In medical research, clustering can be used to analyze X-rays, MRIs, or other images, grouping similar tissue types or identifying abnormalities.
- Image Segmentation: Clustering groups pixels in an image that have similar characteristics, like color or intensity, helping to separate objects from the background.
- Anomaly Detection: Clustering can also help identify unusual data points that don’t fit into any cluster, which is useful for detecting fraud or errors in systems.
Types of Clustering Algorithms
There are several types of clustering algorithms, each designed to group data points in unique ways. Let’s explore the most common ones:
1. Centroid-based Clustering
Centroid-based algorithms group data points around central values known as centroids. The algorithm works by iteratively refining these central points until the best grouping is achieved.
Example: The most well-known algorithm in this category is k-means clustering. Suppose you’re analyzing customer data for a retail store. The algorithm will divide the customers into predefined clusters, like high spenders, occasional shoppers, and bargain hunters, based on similarities in their purchase habits. Each cluster is centered around a calculated point (centroid), and all customers in that cluster are closer to that centroid than any other.
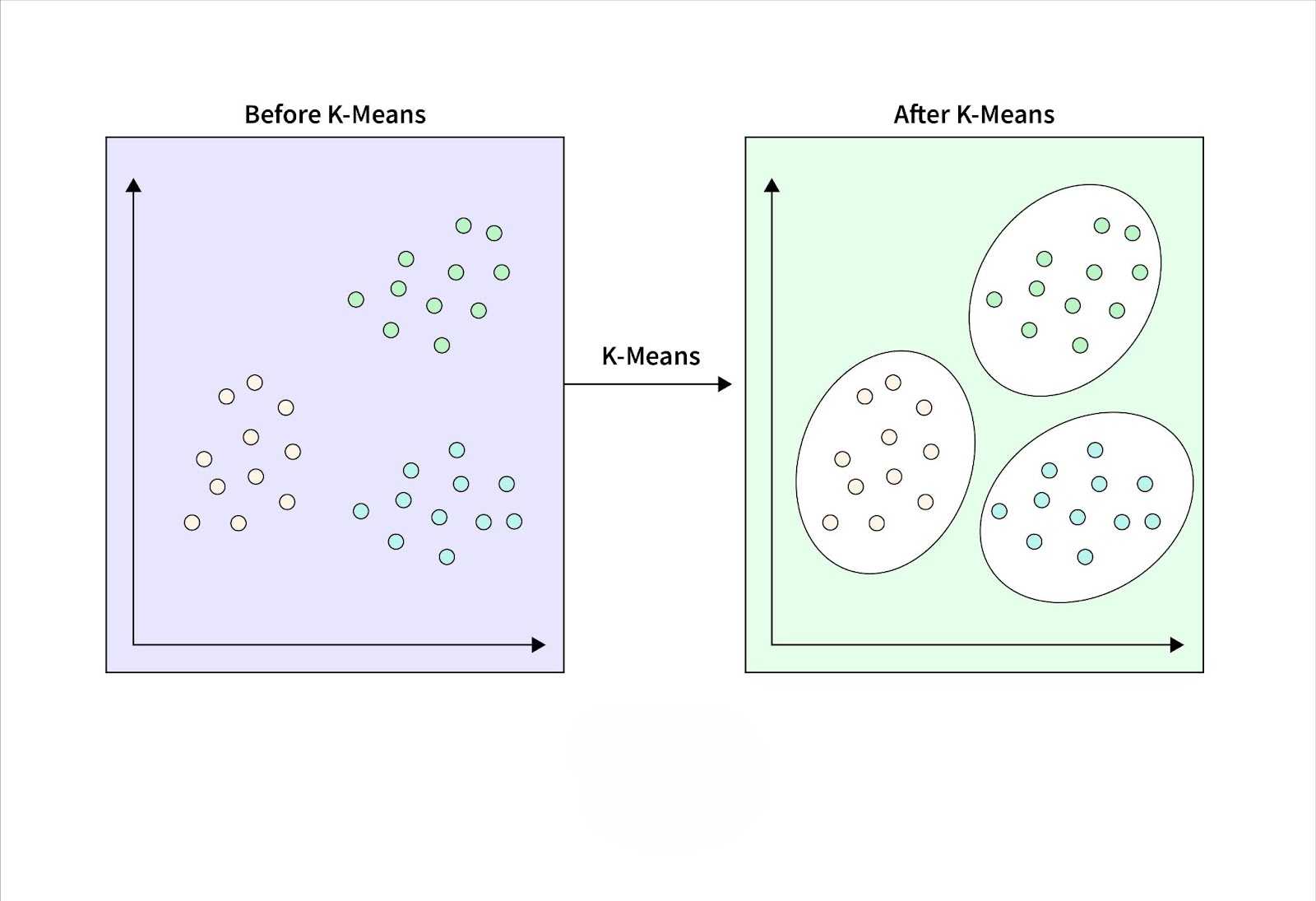
Strengths: It’s simple and efficient for large datasets.
Weaknesses: You need to specify the number of clusters in advance, and it struggles with non-spherical clusters.
2. Density-based Clustering
Density-based clustering groups data points that are closely packed together, identifying regions of high density. Unlike centroid-based methods, it can find clusters of varying shapes and sizes.
Example: A popular algorithm in this category is DBSCAN (Density-Based Spatial Clustering of Applications with Noise). In a geographical dataset, DBSCAN could be used to group densely populated urban areas and identify isolated outliers, such as remote villages.
Strengths: It can identify clusters of arbitrary shapes and can automatically ignore noise and outliers.
Weaknesses: It struggles with datasets that have varying densities or sparse regions.
3. Connectivity-based Clustering (Hierarchical)
Connectivity-based algorithms, also known as hierarchical clustering, build clusters based on data point similarities. This method creates a tree-like structure (called a dendrogram), which shows the relationship between different clusters at various levels. The user can decide the number of clusters by cutting the tree at the desired level.
Example: In biological research, hierarchical clustering is often used to group organisms based on genetic similarity. By analyzing DNA data, scientists can create a hierarchy of species showing their evolutionary relationships.
Strengths: It doesn’t require you to predefine the number of clusters and can reveal natural groupings in the data.
Weaknesses: It can be computationally expensive, especially for large datasets.
4. Distribution-based Clustering
Distribution-based clustering assumes that data points within a cluster follow a particular statistical distribution. One of the most common algorithms in this category is the Gaussian Mixture Model (GMM). GMM assumes that each cluster follows a Gaussian (normal) distribution, and it assigns probabilities to data points being in each cluster.
Example: In finance, GMM can be used to model stock market behavior, where each cluster represents a different market condition (e.g., bull market, bear market). Each data point (stock) is assigned a probability of belonging to a particular market condition.
Strengths: It is flexible and can handle overlapping clusters well.
Weaknesses: It requires prior knowledge about the distribution of the data and can be sensitive to the initial settings.
Applications of Clustering in Different Fields
Clustering is widely used across various industries and fields to solve practical problems. Here are some key applications:
- Finance: Clustering is used to segment customers based on spending behavior or risk profiles, helping financial institutions offer personalized services or detect fraud.
- Marketing: Companies use clustering to group customers by characteristics like age, location, or purchasing habits. This helps in creating targeted marketing campaigns that better engage specific customer groups.
- Fraud Detection: In industries like banking and insurance, clustering can help identify unusual patterns in transaction data, which could indicate fraudulent activities.
- Medical Diagnosis: Clustering algorithms are applied to medical data, such as identifying patient groups with similar symptoms or detecting patterns in medical images to assist in diagnoses.
- Customer Service: Businesses use clustering to group customers by support needs, making it easier to provide tailored customer service and improve satisfaction.
- Manufacturing: In manufacturing, clustering is used to monitor machinery or processes, identifying patterns that could indicate potential breakdowns or inefficiencies.
- Genetics: In genetic research, clustering helps group similar genes or biological data, aiding in understanding genetic relationships or disease patterns.
- Earthquake Studies: Geologists use clustering to group seismic activity patterns, helping to predict and understand earthquake occurrences in different regions.
- Insurance: Clustering helps insurance companies identify customer groups based on risk factors or claim histories, allowing for more accurate premium pricing.
- Biology: In biological research, clustering can group species based on shared traits or genetic data, helping scientists understand evolutionary relationships.
- City Planning: Urban planners use clustering to analyze population data, land usage, or traffic patterns to improve city layouts and infrastructure planning.
- Cybersecurity: Clustering helps detect patterns of malicious activities in networks, enabling faster identification of cybersecurity threats.
- Sports Analysis: Clustering groups athletes or teams based on performance data, helping coaches make data-driven decisions about training and strategy.
- Climate Analysis: Environmental scientists use clustering to study weather patterns or climate change effects by grouping similar regions or conditions.
- Crime Analysis: Law enforcement agencies use clustering to identify crime hotspots and patterns, allowing for more effective deployment of resources and preventive measures.
Conclusion
Clustering is a powerful and versatile tool in machine learning, especially in unsupervised learning, where it helps uncover hidden patterns in data. By grouping similar data points together, clustering enables better data exploration and decision-making in a variety of fields like finance, marketing, healthcare, and beyond. Whether you’re using hard clustering or soft clustering, the ability to organize and make sense of complex datasets is essential for modern applications.
As machine learning continues to evolve, clustering algorithms are also improving, offering more efficient ways to handle large-scale data and identify meaningful groupings. With ongoing research and advancements, clustering will remain a key technique for discovering insights and solving real-world problems.
Frequently Asked Questions (FAQs) on Clustering
What are the advantages of clustering analysis?
Clustering helps discover hidden patterns in data without needing labels. It’s great for exploring datasets, reducing the complexity of data, and even detecting anomalies like fraud. It also helps with segmenting data into meaningful groups for better analysis and decision-making.
Which is the fastest clustering method?
The speed of a clustering algorithm depends on the size of the dataset and the algorithm itself. K-means is often considered one of the faster algorithms for many datasets because of its simplicity. However, for very large datasets, other methods like DBSCAN might be more efficient in certain cases.
What is the difference between clustering and classification?
Clustering is unsupervised, meaning there are no predefined labels, and the goal is to find natural groupings in data. Classification, on the other hand, is supervised, where the algorithm learns from labeled data to assign new data points to predefined categories.
What does the quality of a clustering result depend on?
The quality of clustering depends on factors like the distance metric used (e.g., Euclidean distance), the number of clusters (like in k-means), and the structure of the data itself. Additionally, how well the algorithm fits the data and the initial settings can affect the outcome.
What is the best clustering method?
There isn’t a single “best” clustering method. The right choice depends on the type of data you’re working with, the problem you’re trying to solve, and how much computational power is available. For example, k-means works well for simple datasets, while DBSCAN is better for data with noise and clusters of different shapes.
Is clustering supervised or unsupervised?
Clustering is an unsupervised learning technique because it doesn’t use labeled data. The algorithm automatically identifies groups within the data based on similarities without any predefined labels.
What is meant by k-means clustering?
K-means clustering is a popular algorithm that divides data into a specific number (k) of clusters. The algorithm works by finding the best centroids (central points) for each cluster and assigning data points to the nearest cluster based on these centroids. It’s one of the simplest and fastest clustering methods.


