Understanding the difference between classification and regression is crucial for solving machine learning problems effectively. Both tasks involve making predictions based on data, but they differ in their output type and the algorithms used. Selecting the right approach ensures accurate results and better decision-making for various applications.
What is Classification?
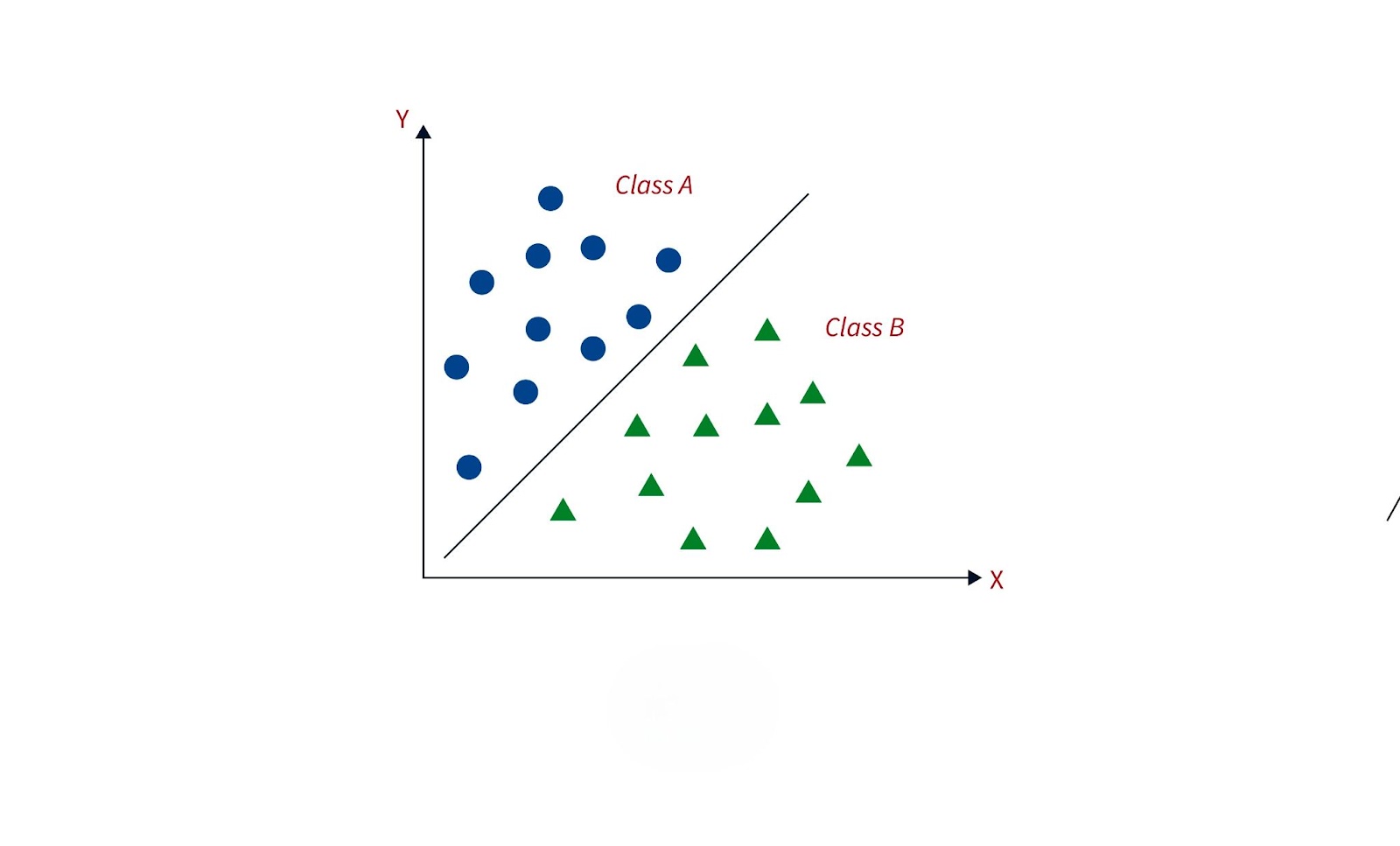
Classification in machine learning is a supervised learning technique where the goal is to predict discrete categories or labels. The algorithm learns from labeled data, mapping input features to predefined classes. It assigns a class label to each new data point based on what it has learned from the training dataset. Classification is essential for tasks that involve distinguishing between multiple outcomes, such as determining whether an email is spam or legitimate.
Common Applications of Classification
- Email Spam Detection: Identifying whether an email is spam or not based on its content and metadata.
- Image Recognition: Recognizing objects, such as distinguishing between cats and dogs in an image.
- Medical Diagnosis: Predicting whether a patient has a specific disease, such as identifying cancer from diagnostic images.
- Sentiment Analysis: Classifying customer reviews as positive, neutral, or negative.
- Credit Scoring: Assessing if a loan applicant should be classified as a high or low credit risk.
Types of Classification Algorithms
Several algorithms are used to solve classification problems, each with unique strengths and applications:
- Logistic Regression: Despite its name, it is a classification algorithm. It is often used for binary classification, such as predicting yes/no outcomes.
- Decision Trees: These provide an interpretable model by splitting data into branches based on feature values, making predictions at the leaves.
- k-Nearest Neighbors (k-NN): This algorithm assigns a class to a new instance based on the majority class of its nearest neighbors.
- Support Vector Machines (SVM): SVM creates a hyperplane that separates different classes and is often used for high-dimensional data.
- Random Forest: An ensemble technique that builds multiple decision trees and combines their outputs for more accurate predictions.
Classification tasks use metrics like accuracy, precision, recall, and F1-score to evaluate performance, ensuring the model can effectively differentiate between categories.
What is Regression?
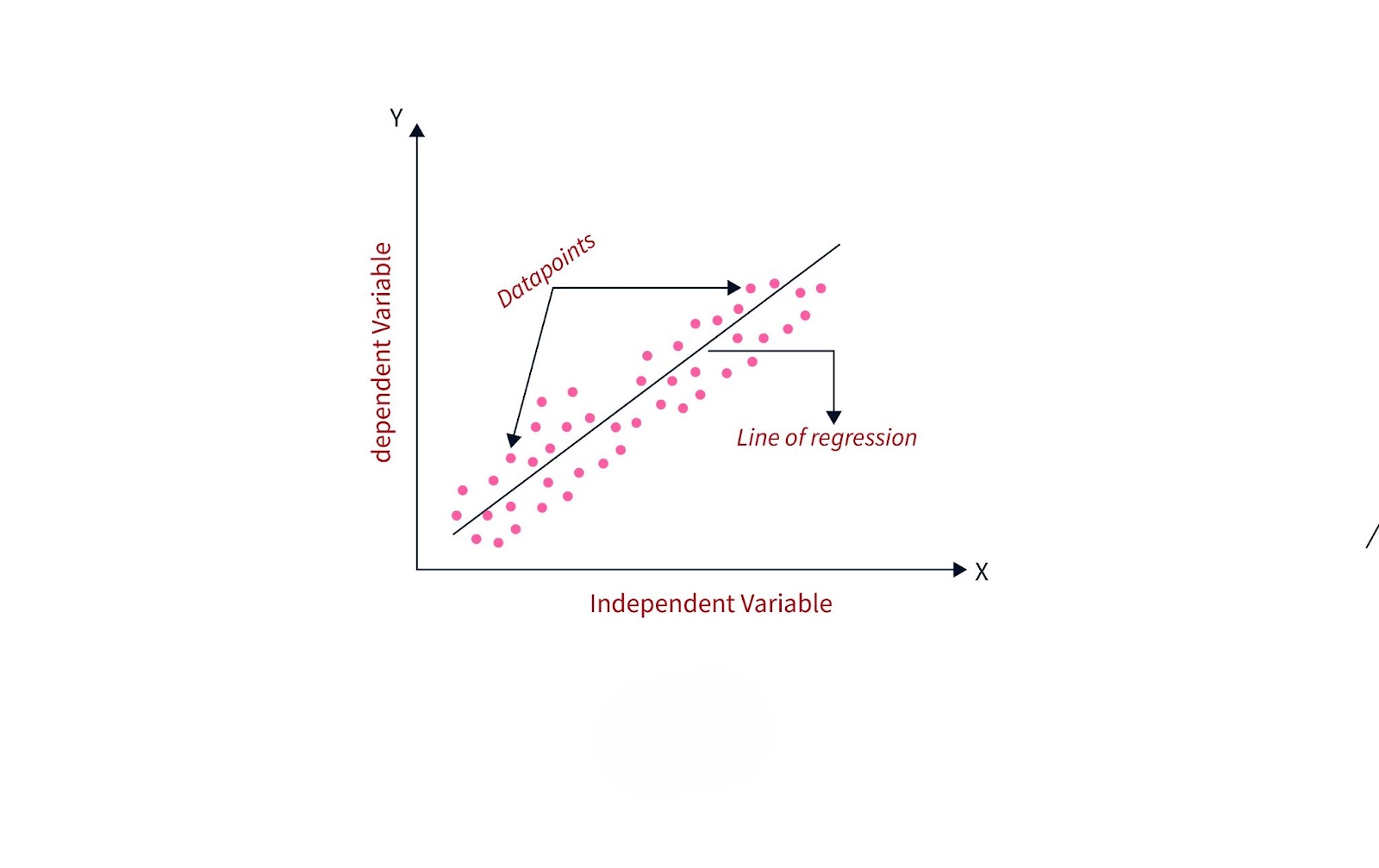
Regression in machine learning is a supervised learning technique used to predict continuous values based on input data. It finds the relationship between independent variables (features) and a dependent variable (target) by fitting a curve or line that best describes the data. Regression models are essential in tasks that require estimating numerical outcomes, such as predicting sales, temperatures, or house prices.
Common Applications of Regression
- House Price Prediction: Estimating property values based on features like location, size, and amenities.
- Stock Market Trends: Forecasting future stock prices using historical data and market indicators.
- Sales Forecasting: Predicting future sales volumes based on seasonal trends and customer behavior.
- Weather Prediction: Estimating temperature or rainfall levels based on past climate data.
- Healthcare: Predicting patient recovery times or medical costs based on clinical data.
Types of Regression Algorithms
Several regression algorithms are used depending on the nature of the problem and data characteristics:
- Linear Regression: The simplest regression technique, which models the relationship between input and output variables as a straight line. It works well for datasets with linear relationships.
- Polynomial Regression: Extends linear regression by adding polynomial terms to capture non-linear relationships between variables.
- Support Vector Regression (SVR): An adaptation of SVM for regression tasks, it fits the best line within a margin of tolerance for prediction errors.
- Ridge and Lasso Regression: These techniques address multicollinearity and overfitting by applying regularization. Ridge regression minimizes the sum of squared coefficients, while Lasso regression performs feature selection by shrinking less important coefficients to zero.
- Logistic Regression: Although it belongs to the regression family, it is often used for binary classification problems.
Regression models use performance metrics like mean squared error (MSE), root mean squared error (RMSE), and R-squared to evaluate how well they predict continuous outcomes.
Key Differences between Classification and Regression
Classification and regression are two core machine learning techniques that differ in their purpose, output type, algorithms, and performance metrics. The table below summarizes their key differences:
| Aspect | Classification | Regression |
| Prediction Output | Discrete labels or categories | Continuous numerical values |
| Algorithms Used | Logistic Regression, Decision Trees, SVM | Linear Regression, Polynomial Regression, SVR |
| Performance Metrics | Accuracy, Confusion Matrix, F1-score | Mean Squared Error (MSE), R-squared, RMSE |
| Use Cases | Spam detection, Image classification | House price prediction, Stock forecasting |
| Nature of Learning | Identifies patterns for classification tasks | Models the relationship between variables |
| Handling of Data | Works with categorical or labeled data | Works with numerical or continuous data |
| Training Process | Learns to separate data points into classes | Learns to predict values by minimizing errors |
| Complexity | Can be simple for binary tasks but complex for multi-class problems | Complexity increases with non-linear relationships |
When to Use Classification vs Regression?
Classification is ideal when the objective is to categorize data points into predefined labels, such as identifying whether a transaction is fraudulent or not. For example, logistic regression is used for binary outcomes, while decision trees and SVMs work well for multi-class problems.
Regression is used when the outcome is a numerical value, such as predicting future stock prices. Techniques like linear regression or SVR are suitable for tasks that involve continuous data and trends.
Some real-world applications may require both methods. For example, a healthcare model may first classify patients as high-risk or low-risk (classification) and then estimate the cost of treatment (regression). Choosing the right approach ensures that the model aligns with the problem type and delivers meaningful insights.
Examples of Classification and Regression Algorithms
Both classification and regression have a variety of algorithms designed to solve specific problems efficiently. Below is an overview of the most popular algorithms for each task.
Classification Algorithms
- Logistic Regression: Primarily used for binary classification tasks (e.g., spam or not spam).
- k-Nearest Neighbors (k-NN): Classifies new data points based on the majority label of its nearest neighbors. It is simple and effective for small datasets.
- Decision Trees: Splits data into branches based on feature values, making predictions at the leaf nodes. It is easy to interpret and useful for both binary and multi-class problems.
Regression Algorithms
- Linear Regression: Models the relationship between input features and a continuous target variable using a straight line.
- Support Vector Regression (SVR): Extends SVM for regression tasks by fitting the best line within a margin of tolerance for error.
- Polynomial Regression: Captures non-linear relationships by introducing polynomial terms into the model. It is useful when the data shows curvature rather than a straight-line pattern.
Conclusion
Classification and regression are essential tools in machine learning, each serving different prediction needs. Use classification when the problem requires predicting discrete categories, and regression when the output is a continuous value. Understanding the differences ensures the appropriate model is chosen, leading to accurate predictions and actionable insights.
References:


