Classification is a key task in machine learning that involves predicting discrete categories or labels for data points. It is a fundamental type of supervised learning, where the algorithm learns from labeled datasets to make predictions on unseen data. Classification models are widely used to solve real-world problems such as email spam detection, disease diagnosis, and image recognition.
The importance of classification lies in its ability to automate decision-making processes, making it essential for a variety of industries. The goal is to develop models that generalize well to new data, ensuring high accuracy across diverse applications.
What is Classification in Machine Learning?
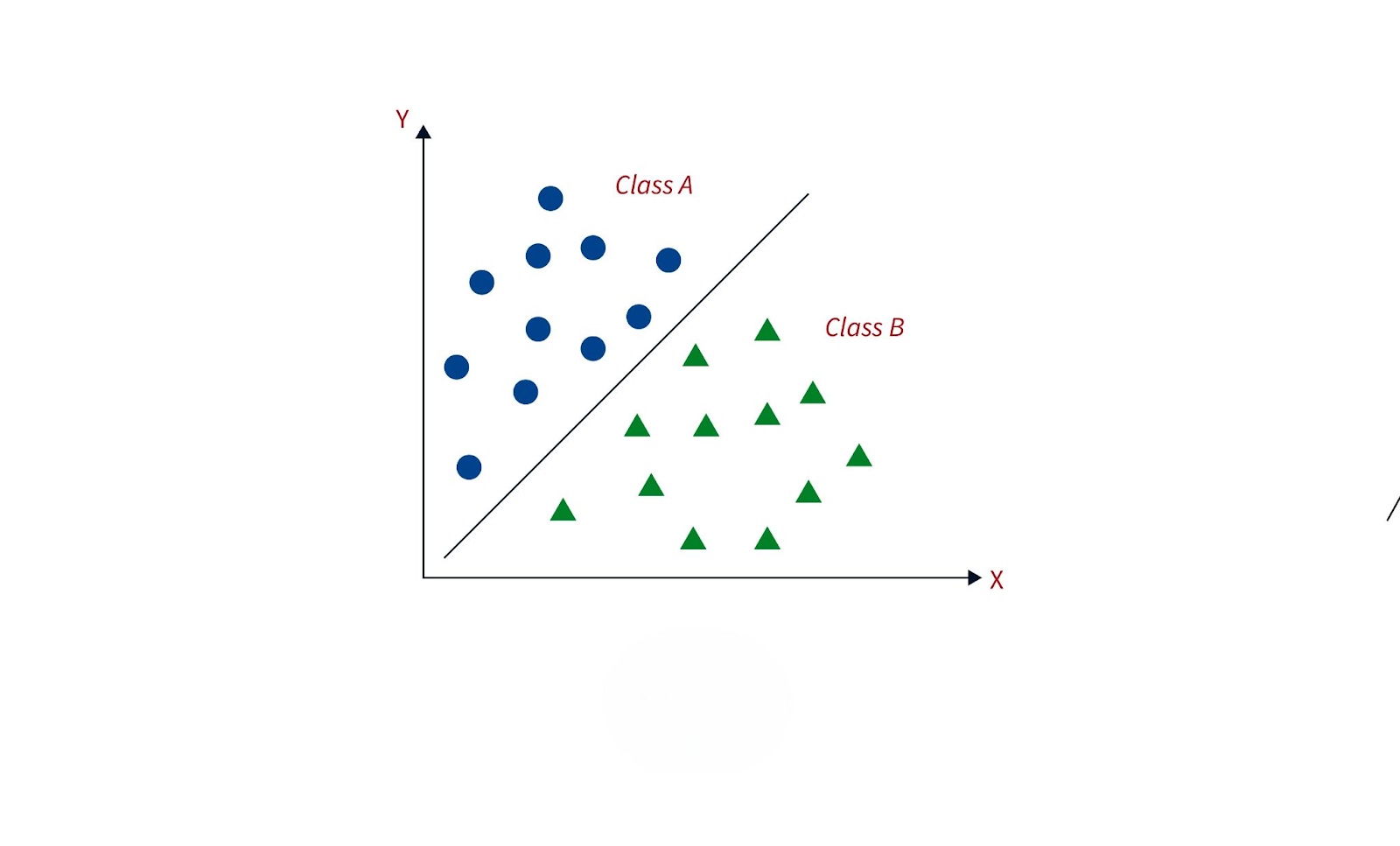
Classification is a supervised learning technique where the goal is to assign input data to predefined categories or labels. The model is trained using labeled data, which helps it learn the relationship between input features and target outcomes. Once trained, the model predicts which category new, unseen data belongs to, making classification essential for tasks like spam detection or disease diagnosis.
Classification vs. Regression
While both classification and regression belong to supervised learning, their objectives differ. Classification predicts discrete labels (e.g., spam or not spam), whereas regression estimates continuous values (e.g., house prices or temperature). The choice between the two depends on the nature of the problem: classification is used when the outcome involves distinct categories, and regression is used when predicting numerical values.
Lazy vs. Eager Learners
Classification algorithms can also be divided into lazy and eager learners:
- Lazy learners (e.g., k-Nearest Neighbors) store the training data and delay the model-building process until predictions are required. These models are easy to implement but computationally expensive at prediction time.
- Eager learners (e.g., Decision Trees) process the training data in advance, building a complete model during training. These models are faster during prediction but may require more time and resources during training.
Classification helps automate decision-making, making it indispensable across many real-world applications.
Types of Classification Tasks in Machine Learning
Classification tasks vary based on the number of categories and the nature of the labels predicted. Below are the main types of classification tasks commonly used in machine learning.
1. Binary Classification
Binary classification involves predicting between two possible outcomes. This is the simplest form of classification, with examples such as email spam detection (spam or not spam) or disease prediction (positive or negative). The model learns to separate the data points into two distinct classes based on their features.
2. Multi-Class Classification
In multi-class classification, the model assigns an input to one of several categories. An example is handwritten digit recognition, where the labels range from 0 to 9. Unlike binary classification, multi-class problems require the algorithm to handle more complex decision boundaries to distinguish between multiple classes.
3. Multi-Label Classification
Multi-label classification involves predicting multiple labels for a single input. For example, an image classifier may identify several objects in one photo, such as “car,” “person,” and “bicycle.” Multi-label classification is common in image tagging, text categorization, and recommendation systems.
4. Imbalanced Classification
Imbalanced classification occurs when the distribution of data among classes is uneven, with some classes being underrepresented. For instance, fraud detection systems often encounter this issue since fraudulent transactions represent only a small fraction of total transactions.
Techniques to Handle Imbalanced Classification
- Sampling Techniques:
- Oversampling: Increases the number of samples in the minority class to balance the dataset.
- Undersampling: Reduces the number of samples in the majority class to achieve balance.
- SMOTE (Synthetic Minority Over-sampling Technique): Generates synthetic samples for the minority class to improve class distribution.
- Cost-Sensitive Algorithms:
These algorithms assign higher penalties to misclassifying minority class instances, encouraging the model to focus more on those classes. Techniques like weighted loss functions help models perform better on imbalanced datasets.
Real-Life Applications of Classification
Classification models play a significant role across various industries, helping organizations automate decisions and improve outcomes through data-driven insights.
Healthcare
In healthcare, classification algorithms are used to predict diseases based on patient data. Models like logistic regression and random forests help classify whether a patient is likely to develop a condition, such as diabetes or heart disease. Additionally, classification aids in diagnostic systems, where models identify the presence of diseases, such as cancer, by analyzing medical images or test results.
Education
Educational institutions use classification models to predict student performance and identify students at risk of dropping out. By analyzing factors such as attendance, grades, and engagement, schools can provide personalized support to students who need it. This ensures better academic outcomes and reduces dropout rates, promoting more effective educational practices.
Transportation
In the transportation sector, classification models help autonomous vehicles make real-time decisions by identifying objects on the road, such as pedestrians, vehicles, and road signs. Traffic management systems also rely on classification algorithms to predict traffic patterns and optimize routes, reducing congestion and improving safety.
Sustainable Agriculture
In agriculture, classification models assist in crop yield prediction by analyzing weather patterns, soil quality, and planting data. Additionally, these models detect pests and diseases by examining plant images, allowing farmers to take preventive action. This use of classification helps improve resource management and ensures sustainable farming practices.
Classification Algorithms
There are a variety of classification algorithms in machine learning, ranging from linear models to advanced deep learning techniques. The choice of algorithm depends on the type of problem, data size, and complexity of the relationships in the data.
1. Linear Classifiers
Logistic Regression
Logistic regression is one of the most widely used linear classifiers, especially for binary classification tasks. It models the probability of an event occurring as a function of the input features. The output is transformed using a sigmoid function, mapping predictions to values between 0 and 1. Logistic regression is commonly applied in fraud detection, credit scoring, and disease diagnosis.
Naive Bayes
Naive Bayes is a probabilistic algorithm based on Bayes’ theorem, with the assumption that features are independent of each other. Despite this assumption, it performs well in applications like spam detection and text classification. It is computationally efficient and can handle large datasets effectively.
2. Non-Linear Classifiers
Decision Trees and Random Forest
Decision trees split data into branches based on feature values, with each branch representing a potential outcome. They are intuitive and easy to interpret but prone to overfitting. Random Forest improves on decision trees by building an ensemble of multiple trees, averaging their predictions to increase accuracy and reduce overfitting. Both are used in healthcare, finance, and retail.
K-Nearest Neighbors (KNN)
KNN is a lazy learning algorithm that classifies data points based on the majority label of their closest neighbors. It is simple but computationally intensive for large datasets. KNN is often applied in pattern recognition tasks like image or handwriting recognition.
Support Vector Machines (SVM)
SVM aims to find the optimal hyperplane that separates data points into distinct classes. It performs well in high-dimensional spaces, making it suitable for text classification and bioinformatics tasks. SVM can handle both linear and non-linear problems through the use of kernels.
3. Advanced Techniques
XGBoost
XGBoost is an optimized gradient boosting algorithm that delivers high performance on structured datasets. It is highly effective in competitive machine learning tasks, such as Kaggle competitions, due to its ability to handle missing data and prevent overfitting through regularization.
Neural Networks
Neural networks, particularly deep learning models, are used for complex tasks such as image recognition and speech processing. These networks consist of multiple layers of neurons, each learning different levels of abstraction from the data. Although powerful, neural networks require large datasets and significant computational resources for training.
Characteristics and Workflow of Classification Models
Building a classification model involves a systematic workflow to ensure the model performs effectively. Each step is essential for achieving accurate predictions and reliable results.
Understanding the Problem
The first step is to clearly define the objective of the classification project. This involves identifying the target variable (label) and understanding the nature of the input data. For example, a bank may aim to predict whether a loan applicant will default or not, making loan approval decisions more efficient. Understanding the business context ensures the model’s predictions align with practical goals.
Data Preparation
Data preparation involves cleaning the raw data to ensure quality and consistency. Tasks include handling missing values, removing duplicates, and correcting inconsistencies. This step ensures the input data is ready for analysis and minimizes the risk of errors during training.
Feature Extraction
Feature extraction focuses on identifying the most relevant variables that contribute to accurate predictions. Techniques such as dimensionality reduction (e.g., PCA) help reduce the number of features without losing critical information. Proper feature extraction improves the model’s efficiency and accuracy by focusing only on useful data.
Model Selection
Selecting the right classification algorithm is crucial. The choice of model depends on factors like the size of the dataset, data structure, and project requirements. For instance, logistic regression might be used for binary classification, while random forests or neural networks are better suited for complex tasks with large datasets.
Training and Evaluation
Once the model is selected, it is trained on the labeled dataset. During training, the model learns the relationships between input features and the target variable. Evaluation is performed using validation datasets or cross-validation techniques to measure performance. Key evaluation metrics like accuracy, precision, recall, and F1-score help assess how well the model generalizes to new data.
Fine-Tuning and Deployment
After evaluation, the model is fine-tuned by adjusting hyperparameters to optimize performance. This can involve tuning parameters like learning rates or tree depths, depending on the algorithm used. Once the model is optimized, it is deployed in a real-world environment, integrated into business systems or applications where it can make predictions in real time.
Evaluation Metrics for Classification Models
Evaluating a classification model’s performance requires appropriate metrics to ensure it generalizes well to unseen data. Below are the most common metrics used to assess classification models.
1. Accuracy
Accuracy measures the proportion of correct predictions out of the total predictions made. It is calculated as:
$$\text{Accuracy} = \frac{\text{Correct Predictions}}{\text{Total Predictions}}$$
While accuracy is straightforward, it can be misleading in imbalanced datasets. For example, if 95% of transactions are non-fraudulent, a model predicting all transactions as non-fraudulent will have high accuracy, despite failing to detect fraud.
2. Precision, Recall, and F1-Score
These metrics are particularly useful for imbalanced datasets:
- Precision: Precision measures the proportion of correctly predicted positive instances out of all predicted positives. It helps in reducing false positives.
$$\text{Precision} = \frac{\text{True Positives}}{\text{True Positives} + \text{False Positives}}$$ - Recall: Recall (or sensitivity) measures the proportion of actual positive instances correctly identified by the model.
$$\text{Recall} = \frac{\text{True Positives}}{\text{True Positives} + \text{False Negatives}}$$ - F1-Score: The F1-score is the harmonic mean of precision and recall, providing a balanced metric for models dealing with imbalanced data.
$$\text{F1-Score} = 2 \times \frac{\text{Precision} \times \text{Recall}}{\text{Precision} + \text{Recall}}$$
3. ROC-AUC (Receiver Operating Characteristic – Area Under Curve)
The ROC curve plots the true positive rate (recall) against the false positive rate at different threshold values. AUC (Area Under the Curve) quantifies the model’s ability to distinguish between classes. An AUC score closer to 1 indicates better performance, with a perfect classifier scoring an AUC of 1.0.
4. Confusion Matrix
The confusion matrix provides a detailed breakdown of the model’s predictions, showing the relationship between true and predicted classes. It includes the following components:
- True Positives (TP): Correctly predicted positive instances
- True Negatives (TN): Correctly predicted negative instances
- False Positives (FP): Incorrectly predicted positives
- False Negatives (FN): Incorrectly predicted negatives
The confusion matrix offers valuable insights into where the model makes errors, helping practitioners fine-tune the model to improve performance.
Emerging Classification Algorithms and Techniques
Advancements in machine learning are continually introducing new algorithms and techniques, expanding the capabilities of classification models.
Transformers for Classification
Transformers, originally developed for natural language processing (NLP), have found applications in other fields like computer vision. Models such as BERT (Bidirectional Encoder Representations from Transformers) and Vision Transformers (ViT) enable efficient feature extraction and classification by processing entire sequences or images in parallel. Transformers excel in tasks requiring a deep understanding of contextual relationships, making them highly effective in text classification and sentiment analysis.
Deep Ensemble Methods
Deep ensemble methods combine the strengths of multiple models to enhance prediction accuracy and robustness. These methods train several deep learning models and aggregate their predictions to reduce errors. Bagging, boosting, and stacking are popular ensemble techniques. This approach is particularly useful in critical applications like financial forecasting and healthcare diagnosis, where higher accuracy and resilience to noise are essential.
Explainable AI (XAI) Techniques
As classification models become more complex, understanding how predictions are made is crucial. Explainable AI (XAI) techniques aim to make machine learning models more transparent and interpretable. Methods such as LIME (Local Interpretable Model-Agnostic Explanations) and SHAP (SHapley Additive exPlanations) provide insights into feature importance, helping practitioners understand the rationale behind predictions. XAI is especially valuable in regulated industries like finance and healthcare, where accountability and transparency are critical.
These advancements are shaping the future of classification, enabling more accurate, reliable, and interpretable models across diverse fields.
Conclusion
Classification models are a cornerstone of machine learning, automating decision-making processes across industries like healthcare, finance, transportation, and education. By understanding various algorithms, workflows, and evaluation metrics, practitioners can develop models that are both accurate and reliable.
Looking ahead, advancements such as transformers, ensemble methods, and explainable AI will continue to improve classification performance. As more applications emerge, classification models will play an even greater role in solving complex problems and advancing the field of machine learning. Building robust models that generalize well is key to leveraging the full potential of classification techniques in real-world scenarios.
References:
- Classification | Machine Learning | Google for Developers
- 5 Classification Algorithms for Machine Learning | Built In


