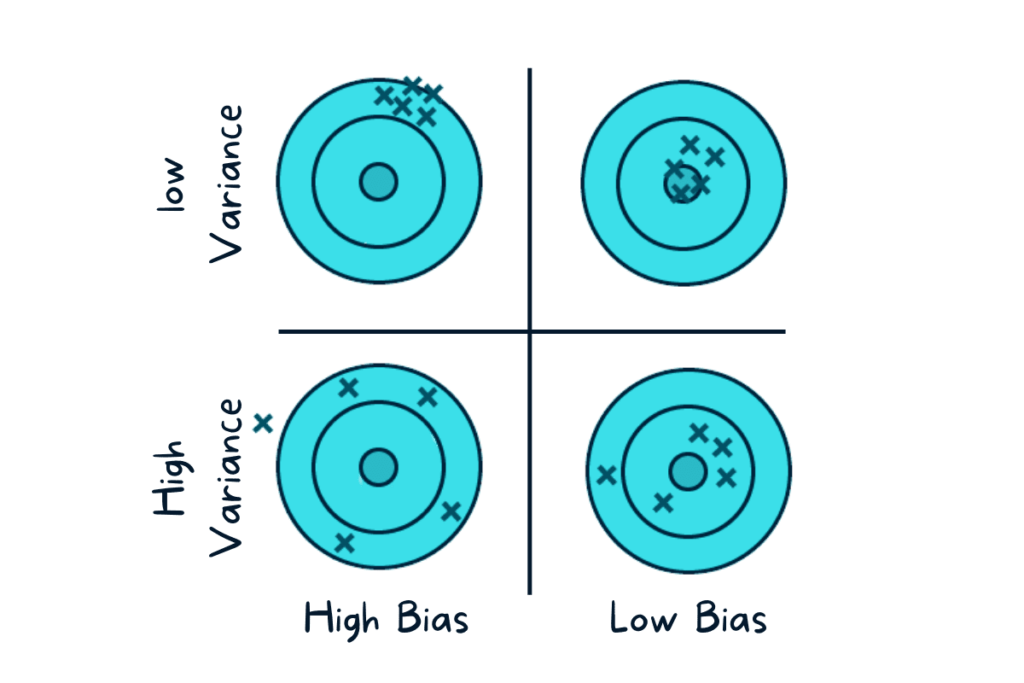
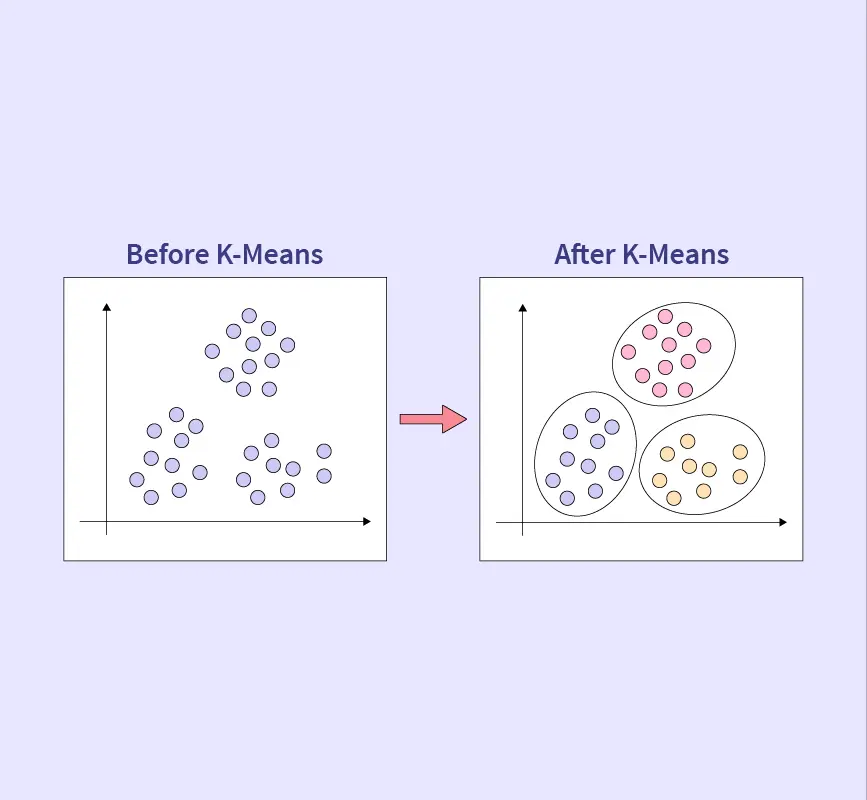
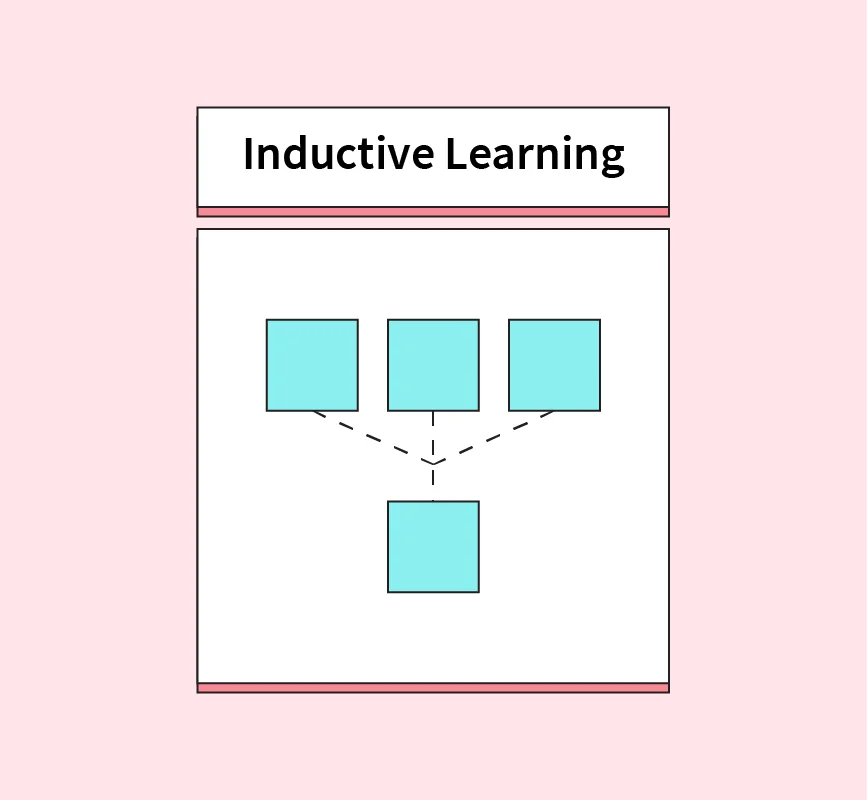
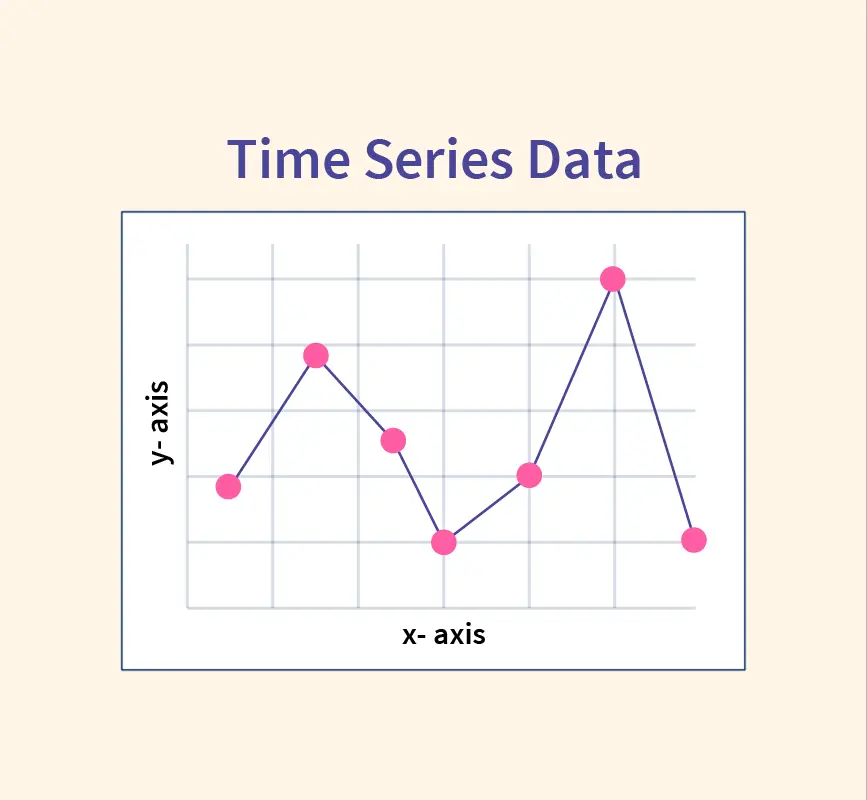
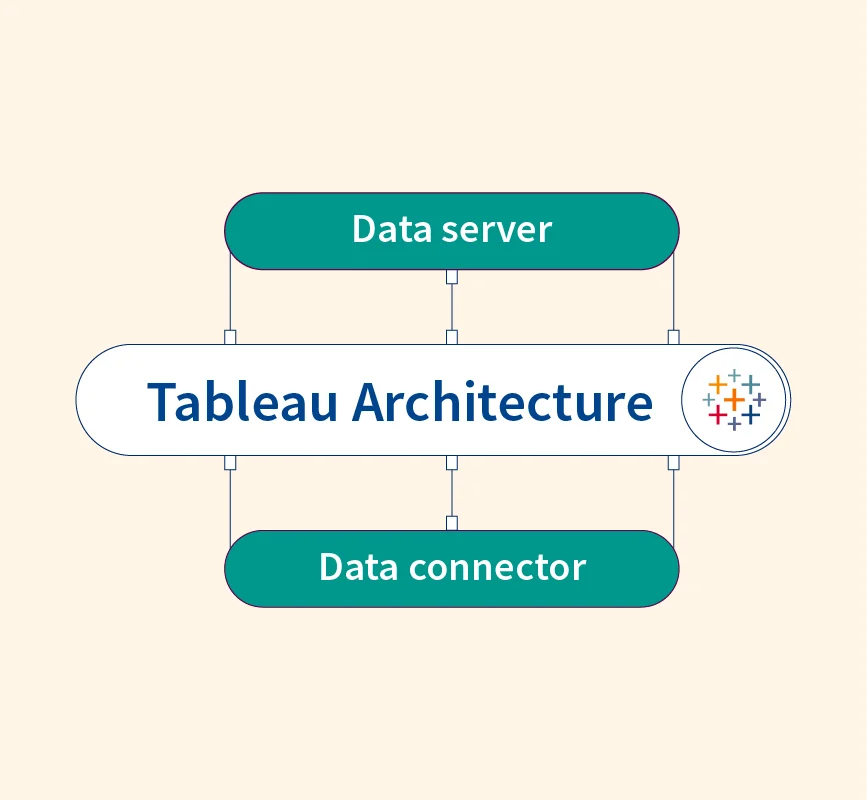
Normalization In Machine Learning
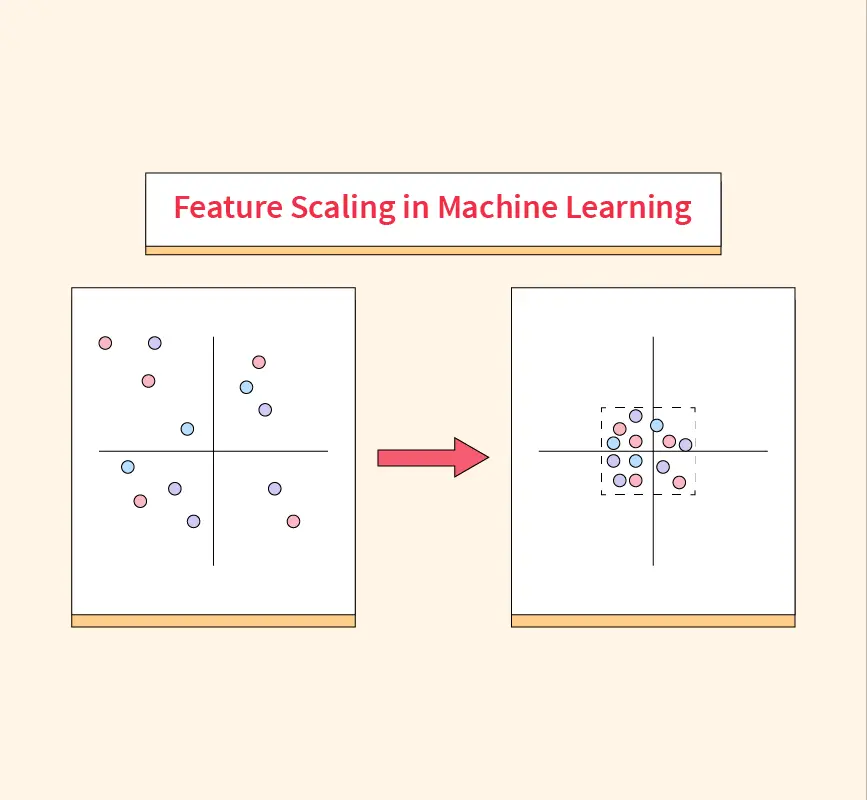
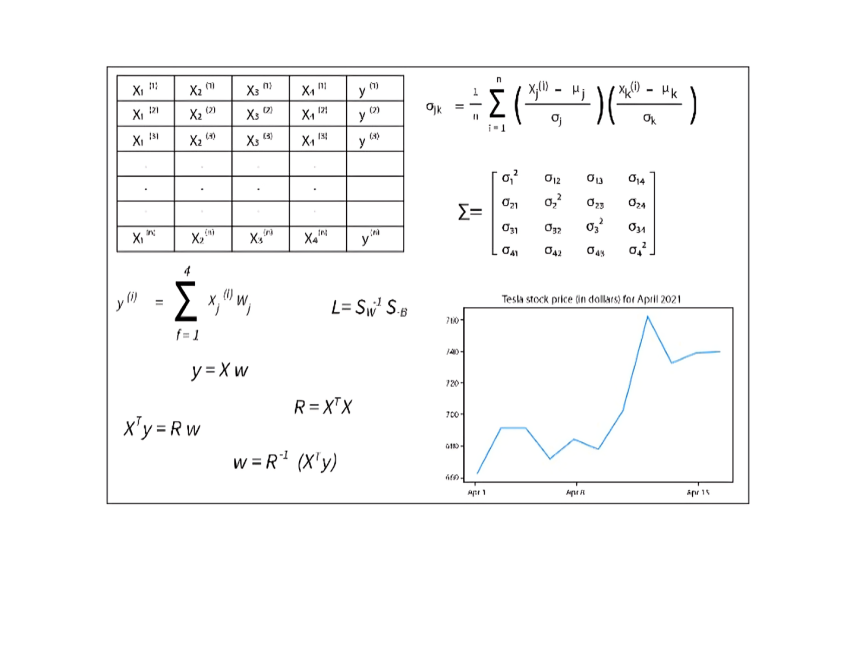
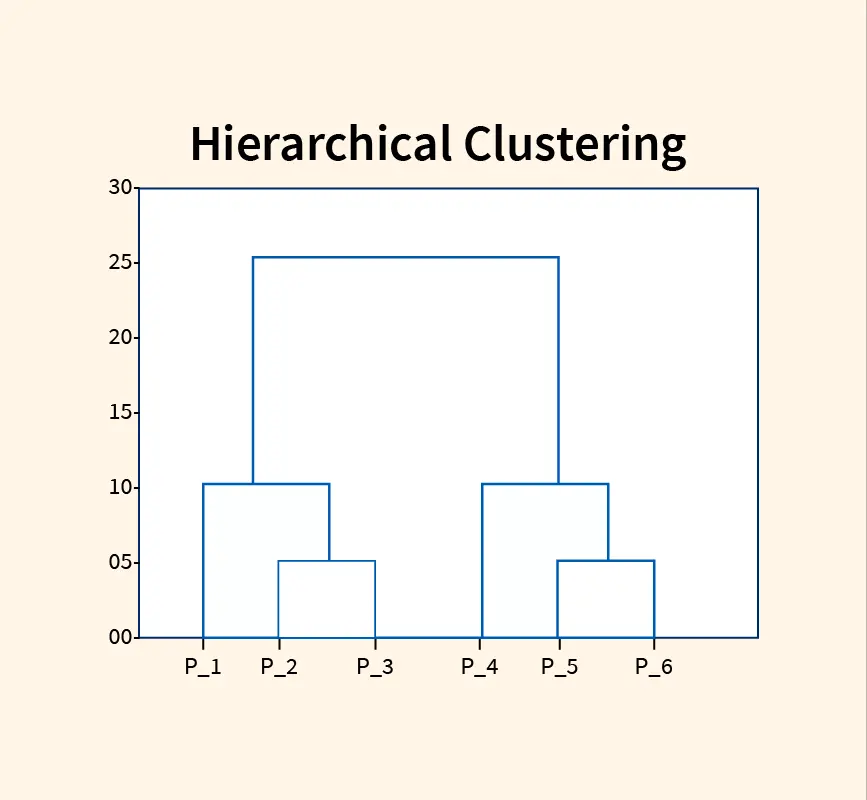
In machine learning, the quality of your model is heavily influenced by the data it is trained on. One essential step in data preprocessing is ensuring that the data is properly scaled to improve model performance. This is where normalization comes into play. Normalization is a technique used to scale numerical data features into a ...