Boosting is a powerful ensemble learning technique used in machine learning to improve model accuracy. Unlike other methods such as bagging, which reduces variance by training models independently, boosting focuses on reducing bias by training weak models sequentially. Each weak learner corrects the mistakes of the previous one, creating a strong predictive model.
Boosting is widely used in various real-world applications, including fraud detection, medical diagnosis, and customer churn prediction. By leveraging multiple weak models, boosting enhances accuracy and robustness in complex datasets. This method is particularly effective when dealing with non-linear relationships and high-dimensional data. Understanding how boosting works and its different types can help data scientists and machine learning practitioners improve predictive performance across multiple domains.
What is Boosting?
Boosting is an iterative machine learning technique that combines multiple weak learners to create a strong predictive model. The primary idea behind boosting is to train models sequentially, where each new model focuses on correcting the errors of the previous ones. This approach helps reduce bias and variance, making the overall model more accurate.
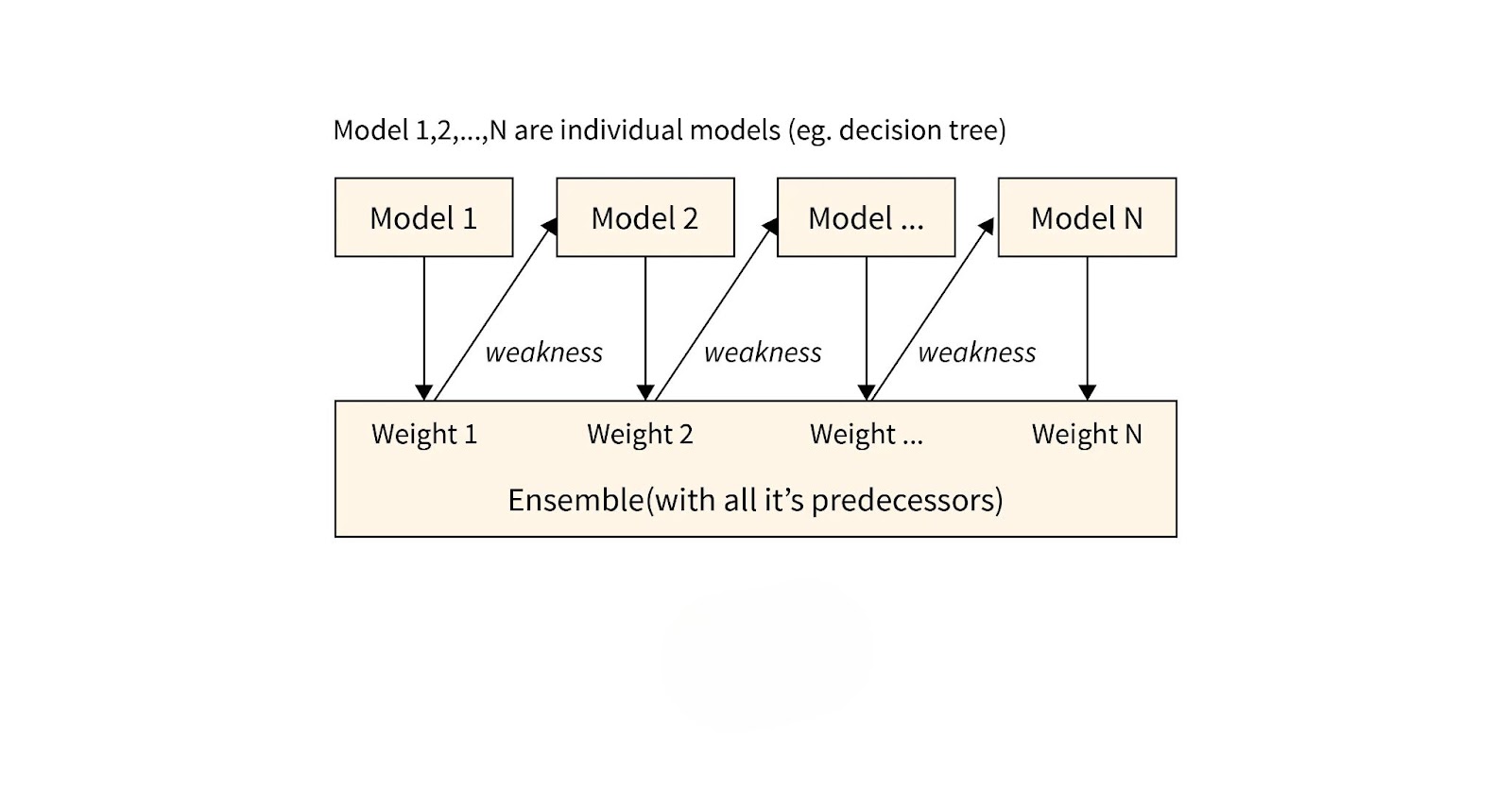
Boosting algorithms adjust the weights of training instances, giving more importance to misclassified samples. As a result, the model learns complex patterns in the data. Unlike bagging, which trains models independently, boosting ensures that each iteration refines the overall predictive performance, making it a preferred choice for many machine learning applications.
How Does Boosting Work?
Boosting follows a systematic approach where weak learners are trained iteratively to enhance overall performance. Here’s a step-by-step breakdown:
Step 1 – Initial Weak Learner Formation
A weak learner, often a decision tree with shallow depth, is selected as the base model. It is trained on the dataset, and predictions are made.
Step 2 – Assigning Weights & Training Iteratively
Each data point is assigned a weight. Misclassified samples receive higher weights in the next iteration, forcing the new model to focus on difficult cases. This iterative training continues until an optimal strong learner is created.
Step 3 – Combining Weak Learners into a Strong Model
The models are combined using weighted voting or averaging to form a single, robust model that outperforms individual weak learners.
Step 4 – Final Prediction & Model Performance Evaluation
The final model makes predictions by aggregating the outputs of all weak learners. The performance is evaluated using accuracy metrics such as mean squared error (MSE) or F1-score, ensuring significant improvement over standalone models.
Types of Boosting Algorithms
Boosting encompasses several algorithms, each designed for specific applications.
1. Adaptive Boosting (AdaBoost)
AdaBoost assigns higher weights to misclassified samples and retrains weak learners iteratively. This process continues until an optimal model is formed.
Example: Used in face recognition systems.
2. Gradient Boosting (GBM)
GBM optimizes model learning by using gradient descent to minimize errors. Weak learners are trained sequentially to correct residual errors.
Example: Customer churn prediction.
3. Extreme Gradient Boosting (XGBoost)
XGBoost is a highly efficient version of gradient boosting, optimized for speed and scalability. It incorporates regularization to prevent overfitting.
Example: Popular in Kaggle competitions and high-performance predictive modeling.
4. LightGBM & CatBoost
- LightGBM: Designed for large datasets, it speeds up training without compromising accuracy.
- CatBoost: Optimized for categorical data, reducing preprocessing time.
Boosting vs Bagging – Key Differences
Boosting and bagging are ensemble techniques but differ in execution and outcomes.
| Feature | Boosting | Bagging |
| Learning Approach | Sequential | Parallel |
| Bias Reduction | High | Moderate |
| Variance Reduction | Moderate | High |
| Computational Cost | Higher | Lower |
| Risk of Overfitting | Higher | Lower |
Boosting focuses on reducing bias by training models sequentially, making it effective for complex data but computationally expensive. Bagging, on the other hand, reduces variance by training models independently and averaging predictions, making it more stable for simpler datasets.
Advantages & Benefits of Boosting in Machine Learning
Boosting offers several advantages:
- Reduces Bias & Variance: By combining weak learners, boosting significantly improves model accuracy and minimizes errors.
- Handles Complex Data Well: Boosting algorithms can model intricate relationships, making them ideal for datasets with non-linear patterns.
- Works with Weak Learners: Even simple base models, such as decision stumps, can yield high accuracy when used in boosting frameworks.
- Computational Efficiency: Algorithms like XGBoost and LightGBM enhance speed and efficiency, making boosting scalable for large datasets.
Challenges & Limitations of Boosting
Despite its advantages, boosting has some challenges:
- Vulnerability to Outliers: Boosting assigns high importance to misclassified points, which can make it sensitive to noisy data.
- Risk of Overfitting: If too many weak learners are added, the model may become too complex and overfit the training data.
- Computational Cost: Training sequentially increases computational overhead, making boosting slower compared to simpler ensemble methods like bagging.
Conclusion
Boosting is a powerful technique that enhances model accuracy by combining weak learners iteratively. It is widely used in machine learning applications where high precision is required. However, practitioners must balance accuracy with computational efficiency and be cautious of overfitting. By understanding different boosting algorithms and their applications, data scientists can select the right approach for their projects. Experimenting with boosting techniques can lead to superior predictive performance and valuable insights from complex datasets.
References:
- What is Boosting? – Boosting in Machine Learning Explained – AWS
- Boosting (machine learning) – Wikipedia


