Introduction to Bayes Theorem in Machine Learning
Bayes Theorem is a cornerstone in probability theory, widely used in machine learning for various predictive and inferential tasks. Named after Reverend Thomas Bayes, this theorem provides a mathematical framework for updating probabilities based on new evidence. In machine learning, especially in classification tasks, it helps model uncertainty by leveraging the principles of conditional probability.
Bayes Theorem is crucial in dealing with the inherent uncertainty in real-world data. It allows algorithms to make educated guesses about unknowns by continuously updating their understanding as new data becomes available. Machine learning models like the Naïve Bayes classifier are built on this theorem, finding applications in spam detection, recommendation systems, and medical diagnosis.
What is Bayes Theorem?
At its core, Bayes Theorem is a formula that calculates the likelihood of an event based on prior knowledge. The theorem is expressed as:
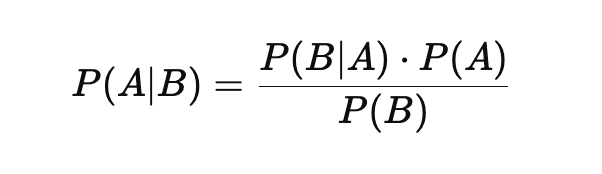
Where:
- P(A|B) is the posterior probability, the probability of event A occurring given that B is true.
- P(B|A) is the likelihood, the probability of B occurring given that A is true.
- P(A) is the prior probability of A occurring.
- P(B) is the marginal likelihood, the total probability of B occurring.
This formula allows machine learning models to update their predictions as new information is introduced, which is essential for dynamic systems where conditions constantly change.
Historical Context
Bayes Theorem originated in the 18th century and was formally introduced posthumously in Thomas Bayes’ work. Over time, it has evolved to become a fundamental principle in statistics, artificial intelligence, and machine learning.
Detailed Mathematical Derivation of Bayes Theorem
Bayes Theorem can be derived from the concept of conditional probability. Conditional probability tells us the likelihood of an event A occurring, given that another event B has occurred. This is expressed as:
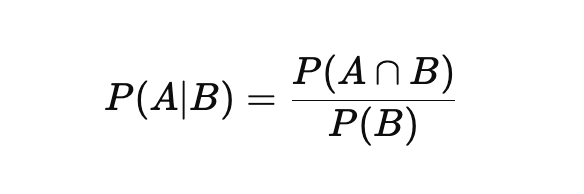
Where:
- P(A∣B) is the probability of event A given event B.
- P(A∩B) is the joint probability of both events A and B occurring.
- P(B) is the probability of event B occurring.
Similarly, we can express the probability of event B given event A as:
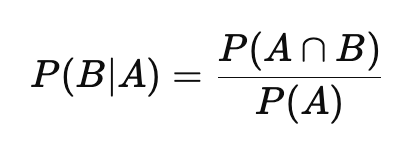
Now, rearranging these two equations gives us:
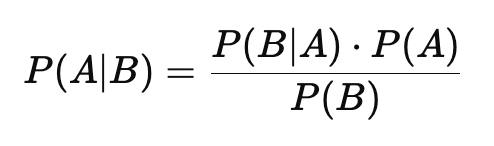
P(B) gives the well-known Bayes Theorem formula:
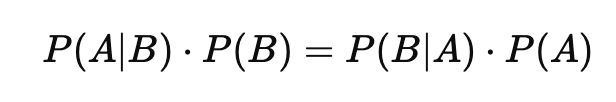
This formula allows us to calculate the posterior probability P(A∣B)P(A|B)P(A∣B), which is the updated probability of event A occurring after considering new evidence B.
Example: Disease Testing
Consider a medical test for a rare disease. Let:
- P(D) be the probability of having the disease (prior probability).
- P(T∣D) be the probability of testing positive given that you have the disease (likelihood).
- P(T) be the overall probability of testing positive (marginal likelihood).
- P(D∣T) be the probability of having the disease given that you tested positive (posterior probability).
By applying Bayes Theorem, we can update the probability of having the disease based on the test result.
Prerequisites for Understanding Bayes Theorem
To fully comprehend and apply Bayes Theorem in machine learning, it’s essential to have a solid understanding of fundamental probability concepts. These prerequisites form the building blocks of Bayes’ Theorem and are integral to grasping how it functions in predictive modeling. Below are the key statistical concepts that underpin Bayes Theorem, explained with examples relevant to machine learning:
1. Experiment
An experiment is any process that produces a measurable outcome. In probability theory, it refers to an action or process that leads to one or more outcomes. For instance, in the context of machine learning, an experiment could involve testing a classifier’s performance by feeding it a specific dataset.
Example: Running a spam classifier on a set of emails is an experiment where the outcome could be whether an email is classified as spam or not spam.
2. Sample Space
The sample space is the set of all possible outcomes of an experiment. It represents every potential result that can occur. In machine learning, the sample space often refers to the entire set of possible predictions or classifications.
Example: For a binary classification model (spam vs. not spam), the sample space consists of two possible outcomes: {Spam, Not Spam}.
3. Event
An event is a specific outcome or a collection of outcomes from the sample space. Events can either be simple (one outcome) or compound (multiple outcomes). In machine learning, events are typically defined by specific criteria or conditions being met.
Example: In a spam detection model, the event could be “an email is classified as spam.” It represents one particular outcome from the sample space.
4. Random Variable
A random variable assigns a numerical value to the outcomes of an experiment. In machine learning, random variables often represent features or outputs that we model using probability distributions.
Example: In a model predicting loan defaults, the random variable could represent the likelihood of defaulting based on a set of features (e.g., credit score, income).
5. Exhaustive Event
Exhaustive events cover the entire sample space, meaning that no other possible outcomes exist beyond these events. In classification tasks, the exhaustive events represent all potential categories into which data can be classified.
Example: In a multi-class classification model for detecting spam, malware, and phishing, the exhaustive events are {Spam, Malware, Phishing}.
6. Independent Event
Two events are independent if the occurrence of one does not influence the occurrence of the other. In machine learning, this concept is crucial for algorithms like Naïve Bayes, which assumes that features are independent of each other.
Example: In spam classification, if the presence of the word “free” in an email does not affect the probability of the word “offer” appearing, the two words are considered independent events (a core assumption in Naïve Bayes).
7. Conditional Probability
Conditional probability measures the probability of an event occurring given that another event has already occurred. This is the foundation of Bayes Theorem, as it allows us to update our predictions based on new evidence.
Example: In a medical diagnosis model, the probability of a patient having a disease (event A) given that they tested positive for certain symptoms (event B) is an example of conditional probability.
8. Marginal Probability
Marginal probability refers to the probability of an event occurring, regardless of the outcomes of any other events. It represents the overall likelihood of an event and is used to normalize the results in Bayes Theorem.
Example: In a fraud detection model, the marginal probability could represent the overall likelihood of fraud occurring within a dataset, without considering any other factors.
Understanding these foundational concepts is essential to effectively applying Bayes Theorem in machine learning. Each of these elements plays a role in calculating probabilities, making them invaluable for creating models that leverage Bayes Theorem for tasks like classification, diagnosis, and decision-making under uncertainty.
How to Apply Bayes Theorem in Machine Learning
Bayes Theorem plays a significant role in machine learning, especially in probabilistic models. For example, it is extensively used in classification tasks where the goal is to determine the probability of a particular class label given some features.
Classification Tasks
In machine learning, Bayes Theorem helps classifiers determine the probability that a given data point belongs to a specific category. For instance, in spam detection, Bayes Theorem evaluates the probability that an email is spam based on words or phrases it contains.
Spam Detection Example
Imagine an email contains the word “prize.” Bayes Theorem can compute the probability that this email is spam given that it contains this word, taking into account the prior probability of emails being spam and the likelihood that the word “prize” appears in spam versus non-spam emails.
What is Naïve Bayes Classifier in Machine Learning?
The Naïve Bayes classifier is a simple yet effective algorithm based on Bayes Theorem. It assumes that features are independent of each other, which simplifies the computation of probabilities. Despite its “naïve” assumption, it works remarkably well in many real-world scenarios, particularly with large datasets and when features are conditionally independent.
There are different variations of Naïve Bayes, such as:
- Gaussian Naïve Bayes: Used for continuous data and assumes a Gaussian distribution.
- Multinomial Naïve Bayes: Used for discrete data like word counts in text classification.
- Bernoulli Naïve Bayes: Suitable for binary/Boolean features.
Handling of Continuous Data with Bayes Theorem
When working with continuous data, Naïve Bayes applies the Gaussian distribution to model the likelihood of features. The Gaussian Naïve Bayes classifier assumes that the continuous values associated with each class follow a normal distribution. The formula for the probability density function of a Gaussian distribution is:
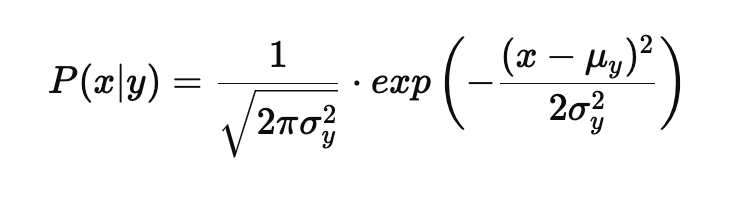
Where:
- μy is the mean of the feature values for class y.
- σy2 is the variance of the feature values for class y.
- x is the input feature value.
This method is used in tasks like predicting housing prices, where features like square footage or number of bedrooms are continuous.
Bayesian Inference in Machine Learning
Bayesian Inference refers to the process of updating the probability of a hypothesis as more evidence becomes available. Unlike frequentist approaches that provide a single estimate of the parameter, Bayesian Inference gives a probability distribution over all possible values. This allows machine learning models to refine their predictions over time as they “learn” from new data.
In Bayesian Inference, the posterior probability is calculated using Bayes Theorem, where:
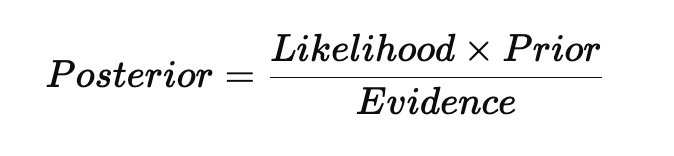
This method is widely used in fields such as recommendation systems and self-driving cars, where models need to update in real-time.
Real-world Applications of Bayes Theorem
Bayes Theorem has become a foundational tool in many real-world applications across various industries, particularly in machine learning and AI. Its ability to calculate conditional probabilities makes it invaluable for tasks that involve prediction and classification. Below are some of the most prominent applications of Bayes Theorem:
1. Natural Language Processing (NLP)
- Spam Detection: One of the most common uses of Bayes Theorem is in spam filters for email systems. The Naïve Bayes classifier analyzes the probability that an email is spam based on its content. Words like “free,” “win,” or “prize” are assigned likelihoods based on how frequently they appear in known spam messages compared to legitimate emails.
- Sentiment Analysis: Bayes Theorem is used to predict the sentiment of a text—whether a customer review or social media post is positive, negative, or neutral. By training on labeled data, models can estimate the likelihood that a particular word or phrase indicates a specific sentiment, helping businesses monitor brand perception.
2. Medical Diagnosis and Disease Prediction
- In the medical field, Bayes Theorem is used to update the probability of a patient having a disease based on new diagnostic test results. For instance, it can help in determining the likelihood of a condition like cancer based on symptoms and test results. Doctors can combine prior knowledge (e.g., the prevalence of the disease) with specific test outcomes to make more accurate diagnoses.
- Genetic Testing: Bayes Theorem helps in evaluating the risk of inheriting genetic disorders. It allows for the updating of risk probabilities as new genetic markers or family history data become available.
3. Financial Market Analysis
- Stock Price Prediction: In the financial world, Bayesian models are used to predict stock price movements based on past data and new market information. These models help investors update their predictions about a stock’s future performance as they receive more data points like quarterly earnings, interest rates, or geopolitical events.
- Fraud Detection: Bayes Theorem is also instrumental in detecting financial fraud. It allows companies to predict the likelihood of fraudulent transactions by analyzing factors like purchase patterns, geographical locations, and payment methods, helping to prevent credit card fraud and money laundering.
4. Recommendation Systems
- Online platforms like Netflix, Amazon, and YouTube use Bayes Theorem in their recommendation engines. The algorithm estimates the probability that a user will enjoy a specific item (movie, product, video) based on their past behavior and preferences. By updating the recommendations with each interaction, these platforms offer personalized suggestions that improve user engagement.
5. Autonomous Vehicles
- Self-driving cars rely heavily on probabilistic models like Bayes Theorem to make decisions in uncertain environments. For example, a vehicle might use Bayes Theorem to assess the likelihood of a pedestrian crossing the street based on real-time sensor data. This helps the vehicle decide when to slow down or stop, ensuring safety while navigating complex traffic situations.
6. Search Engines and Information Retrieval
- Bayes Theorem is employed in search engines like Google to rank web pages based on the likelihood that a user’s query matches a page’s content. It evaluates the probability of certain keywords appearing on relevant pages, helping to deliver more accurate search results. Additionally, Bayesian spam filters ensure that low-quality content is kept out of the search results.
Advantages and Disadvantages of Naïve Bayes Classifier in Machine Learning
Advantages of Naïve Bayes Classifier
- Simplicity and Ease of Implementation
- Easy to implement, based on a straightforward application of Bayes Theorem.
- Ideal for beginners and quick prototyping of models.
- Fast and Scalable
- Efficient with linear time complexity (O(n)), making it scalable to large datasets.
- Handles high-dimensional data effectively, such as text classification.
- Performs Well with Limited Data
- Works effectively with small datasets due to its reliance on prior probabilities.
- Suitable for cases where gathering large training data is difficult.
- Handles Categorical Data Naturally
- Particularly good with categorical data like word frequency in text.
- Algorithms like Multinomial and Bernoulli Naïve Bayes are optimized for discrete data, making them powerful in tasks like spam detection and document classification.
- Less Prone to Overfitting
- Due to its simplicity and strong assumptions, it’s less likely to overfit compared to more complex models.
- Generalizes better in noisy datasets.
Disadvantages of Naïve Bayes Classifier
- Assumption of Feature Independence
- Assumes that all features are independent, which is often unrealistic in real-world data.
- Poor performance when features are correlated, as seen in text classification where words may be related.
- Sensitivity to Imbalanced Data
- Can struggle with imbalanced datasets, leading to biased results favoring the majority class.
- Requires additional techniques like oversampling or class probability adjustments to mitigate this.
- Zero Probability Problem
- Assigns zero probability to unseen feature-class combinations, which eliminates the chance of that class being predicted.
- Requires Laplace smoothing to assign small, non-zero probabilities to unseen events.
- Limited Performance with Continuous Data
- Gaussian Naïve Bayes assumes continuous data follows a normal distribution, which may not always be true.
- Performance suffers when continuous data doesn’t align with a Gaussian distribution.
- Ignores Feature Interactions
- Doesn’t account for interactions between features, limiting its predictive power in cases where feature combinations hold more information (e.g., in medical diagnosis).
- This leads to a less nuanced understanding of the data and reduces model accuracy in complex scenarios.
Code Example: Implementing Naïve Bayes Classifier with Python
Let’s implement a Naïve Bayes Classifier using Python’s popular machine learning library, scikit-learn. We will use the Iris dataset, a well-known dataset that contains 150 samples of iris flowers with four features: sepal length, sepal width, petal length, and petal width. Our task is to classify the flowers into three species: Setosa, Versicolor, and Virginica.
# Import necessary libraries
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score
# Step 1: Load the Iris dataset
data = load_iris()
X = data.data # Features (sepal length, sepal width, petal length, petal width)
y = data.target # Labels (0: Setosa, 1: Versicolor, 2: Virginica)
# Step 2: Split the dataset into training and testing sets
# We use 70% of the data for training and 30% for testing
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Step 3: Initialize the Gaussian Naïve Bayes model
gnb = GaussianNB()
# Step 4: Train the model with the training data
gnb.fit(X_train, y_train)
# Step 5: Use the trained model to make predictions on the test data
y_pred = gnb.predict(X_test)
# Step 6: Evaluate the model's accuracy
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy of Gaussian Naïve Bayes model: {accuracy * 100:.2f}%')Explanation of Code:
- Step 1: Loading the Iris Dataset
- We use the
load_iris()function fromscikit-learn, which loads the Iris dataset into memory. The dataset includes four features (sepal length, sepal width, petal length, petal width) and three possible species as target labels. Xcontains the feature values, andycontains the labels representing the species of the flowers (0 for Setosa, 1 for Versicolor, and 2 for Virginica).
- We use the
- Step 2: Splitting the Dataset
- We split the dataset into two parts: a training set (70%) and a testing set (30%) using
train_test_split(). This allows us to train the model on one portion of the data and evaluate its performance on unseen data (the test set). - The
random_state=42ensures reproducibility, meaning that the split will be the same each time the code is run.
- We split the dataset into two parts: a training set (70%) and a testing set (30%) using
- Step 3: Initializing the Gaussian Naïve Bayes Classifier
- Since we are working with continuous data (features like sepal length and petal width), we use the Gaussian Naïve Bayes classifier from
scikit-learn, which assumes that the features follow a normal (Gaussian) distribution.
- Since we are working with continuous data (features like sepal length and petal width), we use the Gaussian Naïve Bayes classifier from
- Step 4: Training the Model
- The
.fit()method trains the Gaussian Naïve Bayes model using the training data (X_trainandy_train).
- The
- Step 5: Making Predictions
- After the model is trained, we use the
.predict()method to classify the test data (X_test). The model predicts the species for each flower in the test set.
- After the model is trained, we use the
- Step 6: Evaluating the Model
- To evaluate how well the model performs, we calculate the accuracy score using
accuracy_score(), which compares the predicted labels (y_pred) to the actual labels (y_test). The accuracy is then printed as a percentage.
- To evaluate how well the model performs, we calculate the accuracy score using
Output Example
Accuracy of Gaussian Naïve Bayes model: 95.56%In this example, the Gaussian Naïve Bayes model achieves an accuracy of 95.56%, which is quite high for such a simple classification task. This demonstrates the effectiveness of Naïve Bayes, even with its simplifying assumptions of feature independence.
Conclusion
Bayes Theorem is an essential tool in machine learning, offering a structured approach to handling uncertainty and making predictions. Its practical applications, such as the Naïve Bayes classifier, demonstrate its significance in real-world scenarios, from spam detection to medical diagnosis. Understanding Bayes Theorem empowers data scientists to build more robust and intelligent models.


