Bagging, short for Bootstrap Aggregating, is a popular ensemble learning technique in machine learning. It works by combining predictions from multiple models to reduce variance, enhance stability, and improve overall performance. By training models on randomly sampled subsets of data and aggregating their outputs, Bagging minimizes the risk of overfitting and increases generalization.
This article delves into Bagging, covering its definition, implementation process, benefits, practical applications, and a comparison with Boosting. By the end, you’ll have a clear understanding of how Bagging contributes to building robust and reliable machine learning models.
What is Bagging?
Bagging, or Bootstrap Aggregating, is an ensemble learning method that enhances the performance and stability of machine learning models by combining multiple predictions. It leverages the concept of bootstrapping, where multiple subsets of the dataset are created by sampling with replacement. These subsets, known as bootstrap samples, allow models to train on slightly different versions of the original dataset, introducing diversity among the models.
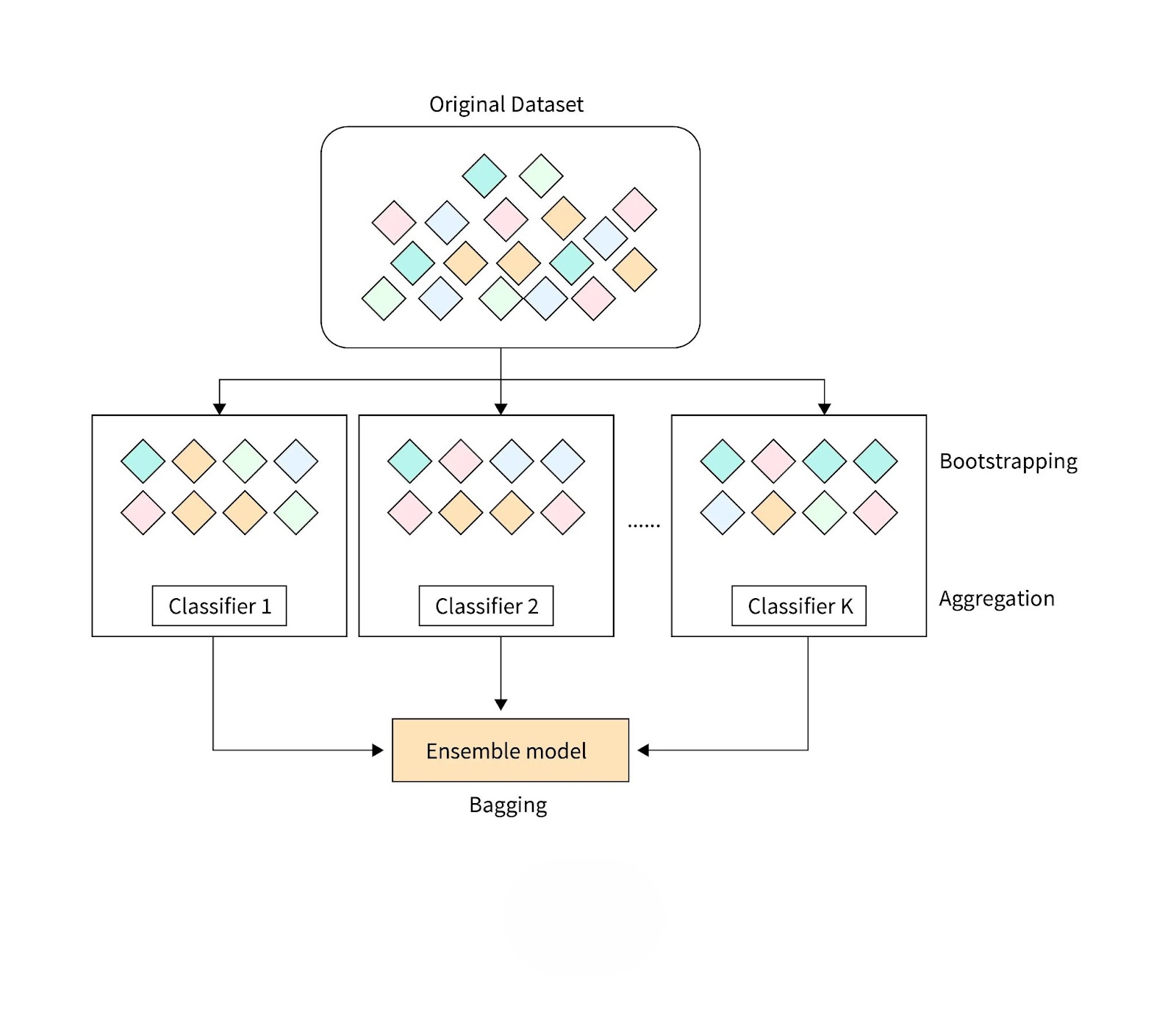
The process involves training individual models, often referred to as base learners, on these diverse datasets. Each model generates its predictions independently. Finally, the predictions are aggregated to produce a single output:
- Classification tasks: Predictions are combined through majority voting, where the most frequent class label is chosen.
- Regression tasks: Outputs are averaged to produce a final prediction.
This aggregation reduces the variance in predictions, making the ensemble model more robust and less prone to overfitting. Bagging is commonly applied to high-variance models like decision trees and serves as the foundation for techniques such as Random Forest.
Understanding Ensemble Learning
Ensemble learning is a machine learning approach that combines the predictions of multiple models to achieve better performance than any individual model. By leveraging the strengths of diverse models, ensemble methods improve accuracy, robustness, and generalization, making them highly effective in solving complex problems.
There are two primary types of ensemble methods:
- Bagging (Bootstrap Aggregating): This technique reduces variance by training multiple models independently on different subsets of the data, created through bootstrapping. The predictions are aggregated, such as using majority voting in classification or averaging in regression. Bagging enhances stability and reduces the risk of overfitting.
- Boosting: Unlike bagging, boosting reduces bias by training models sequentially. Each new model focuses on correcting the errors made by the previous ones, thereby creating a strong learner from weak learners.
Bagging falls under the umbrella of ensemble learning and is particularly effective for high-variance models like decision trees. By training models in parallel and aggregating their predictions, Bagging achieves a more reliable and generalized output, making it an essential tool in the ensemble learning framework.
How Bagging Works?
Bagging, or Bootstrap Aggregating, is a systematic approach to improving model performance by reducing variance and enhancing robustness. Below is a step-by-step explanation of how Bagging works:
Step-by-Step Implementation of Bagging
- Bootstrap Sampling:
Randomly select subsets of the training dataset with replacement, creating multiple bootstrap samples. Each sample has the same size as the original dataset but contains duplicate records while leaving out some instances (due to replacement). - Train Individual Models:
Train base models, often simple learners like decision trees, on each of these subsets independently. Each model learns patterns from its respective subset, introducing diversity into the ensemble. - Aggregate Predictions:
After training, combine the predictions from all the individual models:- Classification Tasks: Use majority voting to select the most frequently predicted class.
- Regression Tasks: Take the average of predictions to produce the final output.
Why Bagging Works?
Bagging works because of the diversity it introduces among models:
- Reduced Overfitting: Training on slightly different datasets ensures that individual models make different errors. When aggregated, these errors tend to cancel out, reducing overfitting and improving generalization.
- Improved Robustness: By averaging predictions, Bagging minimizes the impact of any single model’s poor performance, leading to more stable and reliable results.
This process ensures that Bagging leverages the power of ensemble learning to create a robust and high-performing predictive model, particularly effective for high-variance algorithms like decision trees.
Benefits of Bagging
Bagging offers several advantages that make it a go-to ensemble learning technique for building robust and accurate machine learning models.
- Reduces Overfitting: One of Bagging’s primary strengths is its ability to reduce overfitting. By training models on diverse bootstrap samples and aggregating their predictions, Bagging minimizes the impact of individual model errors, creating more generalized and reliable outputs.
- Increases Model Stability: Bagging enhances model stability by combining the outputs of multiple weak learners into a stronger, more consistent ensemble. This approach ensures that minor variations in the training data do not significantly affect the overall prediction, resulting in a model that is less sensitive to noise.
- Handles High Variance Models: Bagging is particularly effective for high-variance models like decision trees, which tend to overfit on training data. The ensemble approach smooths out their predictions, improving performance on unseen data.
- Scalable and Parallelizable: Since each model in Bagging is trained independently, the process can be easily parallelized, making it computationally efficient and scalable for large datasets and complex problems. This characteristic is especially beneficial in distributed computing environments.
Applications of Bagging in Machine Learning
Bagging is widely used across industries to enhance the performance and accuracy of machine learning models. Its versatility makes it applicable to various domains and tasks.
- Random Forests: Bagging forms the backbone of Random Forests, an ensemble method that combines multiple decision trees to improve classification and regression performance. Each tree is trained on a bootstrap sample, and their predictions are aggregated.
- Example: Random Forests are extensively used in feature selection, credit scoring, and classification tasks in industries like finance, healthcare, and e-commerce.
- Credit Scoring and Fraud Detection: In finance, Bagging improves predictive accuracy by aggregating multiple weak models to assess credit risk and detect fraudulent transactions. The technique helps identify anomalies and reduces false positives in fraud detection systems.
- Medical Diagnostics: Bagging boosts the reliability of machine learning models in medical diagnostics, where precision is critical. By aggregating predictions, Bagging enhances the accuracy of disease predictions, patient risk assessments, and personalized treatment plans.
- Sentiment Analysis: Natural Language Processing (NLP) tasks like sentiment analysis benefit from Bagging by combining predictions from multiple models to improve the overall sentiment classification accuracy. This application is particularly useful in understanding customer feedback and reviews in marketing and social media.
Bagging vs. Boosting
Bagging and Boosting are two powerful ensemble learning methods. While they share the goal of improving model performance, their methodologies differ. Below is a detailed comparison followed by similarities and use cases.
| Aspect | Bagging | Boosting |
| Learning Process | Models are trained independently in parallel using bootstrap samples. | Models are trained sequentially, with each correcting previous errors. |
| Objective | Reduces variance, making the model more stable and generalized. | Reduces bias by iteratively improving weak learners. |
| Aggregation | Combines predictions through voting (classification) or averaging (regression). | Aggregates weighted predictions, giving higher importance to strong models. |
| Performance Focus | Excels with high-variance models prone to overfitting. | Excels with high-bias models needing stronger predictions. |
| Data Sampling | Uses bootstrap sampling (sampling with replacement). | Uses the entire dataset for each iteration but focuses on harder instances. |
| Examples | Random Forest. | Gradient Boosting, AdaBoost, XGBoost. |
| Error Handling | No specific focus on reducing errors of individual models. | Prioritizes correcting errors in subsequent models. |
| Training Speed | Faster due to independent training of models. | Slower due to sequential learning. |
| Risk of Overfitting | Lower due to averaging or voting. | Higher if overfitting occurs on the training data. |
Similarities
- Both are ensemble learning methods that combine multiple models to improve accuracy and generalization.
- Both reduce prediction errors, albeit through different mechanisms.
- Both can use the same base learners, such as decision trees, for model building.
When to Use Bagging vs. Boosting?
- Use Bagging: For high-variance models (e.g., decision trees) that are prone to overfitting, Bagging stabilizes predictions by averaging multiple outputs.
- Use Boosting: For high-bias models or datasets requiring stronger predictions, Boosting improves accuracy by correcting errors iteratively.
Advantages and Disadvantages of Bagging
Bagging is a highly effective ensemble learning technique, but like any method, it comes with its own strengths and limitations.
Advantages
- Reduces Overfitting: Bagging minimizes variance, making it especially useful for high-variance models like decision trees. By aggregating predictions, it ensures more stable and generalized outputs.
- Handles Noisy Datasets: The averaging or majority voting process smooths out noise in the data, leading to better model performance even with noisy inputs.
- Versatility: Bagging works seamlessly for both classification tasks (e.g., spam detection) and regression tasks (e.g., predicting house prices).
Disadvantages
- Limited Improvement for Low-Variance Models: For models that are already stable and low in variance, such as linear regression, Bagging may not yield significant performance improvements.
- Higher Computational Resources: Training multiple models independently can be resource-intensive in terms of both computation time and memory, especially for large datasets or complex base models.
Bagging is most effective when applied to unstable models with high variance, but its computational cost and limited impact on low-variance models must be considered when deciding its use in machine learning projects.
Implementing Bagging in Python
Bagging is straightforward to implement in Python using libraries like Scikit-learn. Below are two examples that demonstrate how to apply Bagging for classification and regression tasks.
Example: Bagging with Decision Trees (Classification)
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
# Create a dataset
X, y = make_classification(n_samples=1000, n_features=20, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Create and train a Bagging classifier
bagging_clf = BaggingClassifier(
base_estimator=DecisionTreeClassifier(),
n_estimators=10,
random_state=42
)
bagging_clf.fit(X_train, y_train)
# Evaluate the model
accuracy = bagging_clf.score(X_test, y_test)
print(f"Bagging Classifier Accuracy: {accuracy:.2f}")Explanation:
- The BaggingClassifier combines the predictions of multiple decision trees trained on random subsets of the data.
- The final prediction is determined by majority voting.
Example: Bagging for Regression with Random Forest
from sklearn.ensemble import RandomForestRegressor
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
# Create a dataset
X, y = make_regression(n_samples=1000, n_features=10, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Create and train a Random Forest Regressor
rf_regressor = RandomForestRegressor(n_estimators=100, random_state=42)
rf_regressor.fit(X_train, y_train)
# Evaluate the model
r2_score = rf_regressor.score(X_test, y_test)
print(f"Random Forest Regressor R2 Score: {r2_score:.2f}")Explanation:
- The RandomForestRegressor is a bagging-based algorithm that aggregates predictions from multiple decision trees to improve accuracy.
- The final output is the average of the predictions.
Conclusion
Bagging is a powerful ensemble technique in machine learning that plays a critical role in reducing variance, improving accuracy, and stabilizing model predictions. By training multiple models on diverse subsets of data and aggregating their outputs, Bagging enhances the robustness of high-variance models and ensures better generalization on unseen data.
Its simplicity, scalability, and effectiveness make Bagging an essential tool for both classification and regression tasks. As part of the broader ensemble learning framework, it is particularly valuable when paired with algorithms like decision trees.
Readers are encouraged to experiment with Bagging and compare it with other ensemble techniques like Boosting to determine the most suitable approach for their specific machine learning problems.
References:


