In machine learning, improving model accuracy and reducing errors are critical objectives. One approach to achieve this is through ensemble methods, which combine the predictions of multiple models to create a more robust and accurate final model. Rather than relying on a single model, ensemble techniques harness the collective intelligence of many models, each contributing to the final prediction.
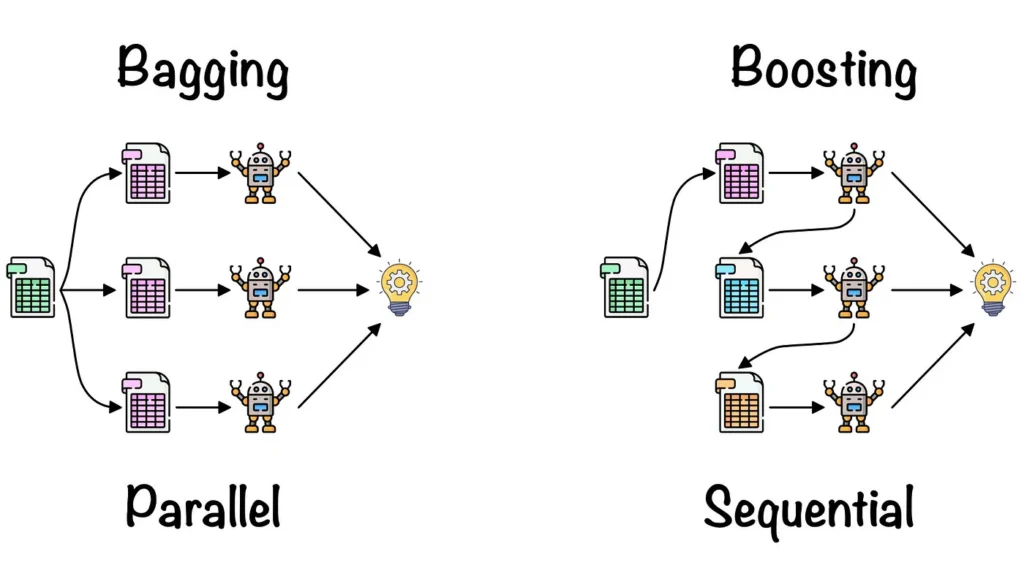
Two of the most popular ensemble techniques are Bagging (Bootstrap Aggregating) and Boosting. Both methods aim to enhance model performance, but they achieve this in different ways. Bagging focuses on reducing variance by training multiple independent models, while Boosting focuses on reducing bias by training models sequentially, with each one learning from the errors of its predecessors.
In this article, we will explore both Bagging and Boosting in depth, discuss their advantages, and examine how they differ in approach and use cases.
What is Bagging (Bootstrap Aggregating)?
Bagging, short for Bootstrap Aggregating, is an ensemble method designed to reduce the variance of machine learning models. Bagging involves training multiple independent models on different subsets of the dataset and then combining their predictions to produce a final output. This method helps improve model performance by reducing overfitting and creating a more stable model.
How Bagging Works
Bagging works by generating multiple bootstrapped datasets (random samples drawn with replacement from the original dataset) and training a separate model on each of these datasets. The key idea is that by combining predictions from models trained on slightly different datasets, the overall variance of the model decreases, leading to more accurate and reliable predictions.
Steps of Bagging:
- Data Sampling: Multiple subsets of the original dataset are created using bootstrapping (random sampling with replacement). Each subset may contain duplicate instances but will be different from the others.
- Model Training: A separate model is trained on each bootstrapped subset of the data. These models are typically of the same type, such as decision trees, but each model sees different data.
- Aggregation: For classification tasks, the final prediction is made by taking a majority vote across all models. For regression tasks, the final prediction is the average of all models’ predictions.
Advantages of Bagging:
- Reduces Variance: By combining multiple models, Bagging reduces the risk of overfitting to any particular subset of the data.
- Improves Stability: Models trained on bootstrapped datasets are less likely to be influenced by outliers or noise in the data.
- Parallelization: Since each model is trained independently, Bagging allows for easy parallelization, which can speed up training when resources are available.
Example Algorithm: Random Forest
One of the most well-known implementations of Bagging is the Random Forest algorithm. In Random Forests, multiple decision trees are trained on different bootstrapped samples of the data, and the predictions of the trees are aggregated. This method is particularly effective because it combines the strengths of decision trees with the stability and robustness of Bagging.
- Use Case: Random Forests are commonly used in tasks like classification (e.g., predicting whether a customer will churn) and regression (e.g., predicting house prices) due to their ability to handle large datasets, categorical variables, and complex relationships in the data.
What is Boosting?
Boosting is another powerful ensemble technique in machine learning, but unlike Bagging, Boosting focuses on reducing bias rather than variance. The main idea behind Boosting is to train models sequentially, where each new model tries to correct the errors made by the previous models. Boosting creates a strong model by combining the predictions of weak learners (models that are only slightly better than random guessing), improving accuracy and performance over time.
How Boosting Works
Boosting works by building models one at a time, with each subsequent model focusing on the mistakes made by the previous models. The key to Boosting’s success lies in its ability to learn from past mistakes and improve gradually.
Steps of Boosting:
- Model Initialization: The process starts with training a weak learner (usually a simple model like a decision tree) on the entire dataset.
- Weight Adjustment: The algorithm assigns higher weights to the incorrectly classified examples, emphasizing them in the next round of training. This ensures that the subsequent model focuses on these difficult examples.
- Model Combination: Each model is added to the ensemble, and its prediction is combined with those of the previous models. In the case of classification, a weighted majority vote is often used, while for regression, the models’ predictions are averaged.
Key Concept: Weak Learners
Boosting typically works by combining several weak learners. A weak learner is a model that performs only slightly better than random guessing, but when combined with others in a Boosting framework, it contributes to creating a strong learner.
Popular Boosting Algorithms
1. AdaBoost (Adaptive Boosting)
AdaBoost is one of the first and most well-known Boosting algorithms. In AdaBoost, each model is trained sequentially, with greater emphasis placed on the data points that were misclassified by the previous models. After training each model, AdaBoost assigns a weight to that model’s prediction, which is based on its accuracy. The final output is a weighted combination of the predictions from all models.
- Use Case: AdaBoost is often used in binary classification tasks such as spam detection or fraud detection, where the data may contain outliers or noisy samples that the algorithm can learn to handle.
2. Gradient Boosting Machines (GBM)
Gradient Boosting Machines (GBM) is a generalization of AdaBoost that applies gradient descent to optimize the performance of the model. Each subsequent model is trained to correct the residual errors (i.e., the difference between the actual and predicted values) from the previous models, which helps improve accuracy.
- Use Case: GBM is widely used in predictive analytics tasks such as predicting credit default risk, customer churn, and sales forecasting. It’s known for its strong predictive performance in both classification and regression tasks.
3. XGBoost (Extreme Gradient Boosting)
XGBoost is an optimized implementation of Gradient Boosting that has gained immense popularity for its speed and performance. XGBoost incorporates several additional features, including regularization to prevent overfitting and parallel processing for faster training.
- Use Case: XGBoost is commonly used in data science competitions (like Kaggle) and in real-world applications such as time-series forecasting, marketing analytics, and recommendation systems.
4. LightGBM
LightGBM (Light Gradient Boosting Machine) is a gradient boosting algorithm optimized for large datasets. LightGBM achieves faster training speeds and lower memory usage by implementing techniques such as leaf-wise tree growth and histogram-based learning.
- Use Case: LightGBM is ideal for large-scale machine learning tasks, such as ranking, classification, and regression, especially when speed and memory efficiency are critical.
Similarities Between Bagging and Boosting
While Bagging and Boosting are distinct ensemble learning techniques with different approaches, they share several similarities that make them both valuable for improving model performance.
1. Both are Ensemble Methods
Bagging and Boosting both fall under the umbrella of ensemble methods, which combine the predictions of multiple models to create a more accurate and robust final model. The idea is that by combining multiple weak learners, the final ensemble model will have better performance than any individual model.
2. Both Improve Model Performance
One of the primary goals of both Bagging and Boosting is to improve the performance of a machine learning model by reducing errors that occur in a single model. In both cases, the combination of multiple models reduces overfitting and leads to better generalization to unseen data.
3. Both Use Base Learners
Both techniques are designed to improve the performance of base learners, which are often simple models like decision trees or linear models. These base learners, when combined in Bagging or Boosting, create a stronger overall model.
4. Both are Versatile
Bagging and Boosting can be applied to a wide range of machine learning tasks, including classification and regression. They are also flexible enough to be used with different types of base learners, depending on the specific problem being solved.
Differences Between Bagging and Boosting
| Aspect | Bagging | Boosting |
| Objective | Reduce variance by averaging predictions across multiple models. | Reduce bias by sequentially learning from model errors. |
| Model Training | Models are trained independently on different subsets of the data. | Models are trained sequentially, with each model learning from the errors of the previous one. |
| Data Sampling | Uses bootstrapped datasets (random sampling with replacement). | No bootstrapping; uses the entire dataset, but focuses on misclassified samples. |
| Model Combination | Voting for classification and averaging for regression. | Weighted combination of models based on their performance. |
| Overfitting Risk | Less prone to overfitting due to averaging across independent models. | Higher risk of overfitting, especially if the model becomes too complex. |
| Focus | Focuses on improving stability and reducing variance. | Focuses on improving accuracy by reducing bias. |
| Model Diversity | Models are trained in parallel and are often diverse due to bootstrapping. | Models are trained sequentially, and depend on the errors of previous models. |
| Computational Efficiency | Can be more computationally efficient due to parallelization. | Sequential training makes it more computationally intensive. |
| Base Learner | Typically uses strong learners like decision trees. | Typically uses weak learners like shallow decision trees. |
| Use Case | Suitable for reducing overfitting in high-variance models (e.g., Random Forest). | Suitable for tasks that require improving model accuracy on complex datasets (e.g., XGBoost, AdaBoost). |
| Common Algorithms | Random Forest, Bagging Classifier | AdaBoost, Gradient Boosting Machines (GBM), XGBoost, LightGBM |
Challenges and Considerations
While Bagging and Boosting offer significant improvements in model performance, both techniques come with certain challenges and considerations that need to be addressed.
1. Increased Computational Cost
Both Bagging and Boosting involve training multiple models, which can lead to higher computational requirements. This is especially true for large datasets or complex models, where training hundreds or even thousands of models can significantly increase the time and resources needed.
- Bagging: In Bagging, since each model is trained independently, it’s possible to parallelize the process, reducing the computational burden. However, running multiple models still requires substantial computational power.
- Boosting: Boosting, on the other hand, involves sequential model training, where each model depends on the results of the previous one. This makes it more computationally intensive than Bagging and less suited for parallelization.
2. Overfitting in Boosting
While Boosting is highly effective at reducing bias, it can also lead to overfitting if not carefully tuned. Since Boosting focuses on correcting the errors made by previous models, it may overemphasize noisy or outlier data, leading to poor generalization on unseen data.
- Solution: To mitigate overfitting in Boosting, techniques like early stopping (halting the training process when the performance stops improving), regularization (penalizing model complexity), and hyperparameter tuning (adjusting the learning rate or tree depth) are often employed.
3. Model Interpretability
Both Bagging and Boosting, particularly when using complex models like decision trees, can result in ensembles that are harder to interpret. As the number of models in the ensemble grows, understanding how each model contributes to the final prediction becomes more challenging.
- Bagging: While models like Random Forests are powerful, they can be seen as “black boxes” due to the complexity of combining numerous decision trees.
- Boosting: Boosting models, especially when using techniques like Gradient Boosting or XGBoost, can become even more complex, making it difficult to explain the model’s predictions to non-technical stakeholders.
4. Sensitivity to Noisy Data in Boosting
Boosting algorithms are particularly sensitive to noisy data or outliers. Since Boosting assigns more weight to misclassified examples, it may focus too much on these outliers, leading to poorer overall performance.
- Solution: Addressing data quality by performing proper data cleaning and outlier removal before training the model can help mitigate the negative impact of noisy data on Boosting algorithms.
Conclusion
Bagging and Boosting are essential ensemble techniques in machine learning that enhance model performance by combining multiple models. Bagging reduces variance by training models independently on bootstrapped datasets, making it effective for reducing overfitting, as seen in applications like Random Forest for fraud detection and credit scoring. Boosting, on the other hand, reduces bias by sequentially improving weak learners, excelling in tasks like customer churn prediction and financial forecasting. However, Boosting is more prone to overfitting and requires careful tuning.
Both methods come with increased computational costs, and model complexity can make interpretation challenging. Choosing the right technique depends on the problem: Bagging is better for improving stability, while Boosting is ideal for tasks requiring high accuracy.
Understanding these techniques allows data scientists to optimize models for specific tasks, improving overall performance and robustness.


